Differential Privacy
in projects on Blog, Github, Pages, Jekyll, Spacy
설문조사 참여나 온라인 서비스 가입이 일상화된 현대 사회에서 우리의 개인정보는 다양한 데이터베이스에 저장되고 활용된다. 따라서 이러한 데이터를 안전하게 보호하는 것은 매우 중요한 과제이다. 데이터베이스 자체가 유출되는 개인정보 침해 사고는 잘 알려진 위협이지만, 데이터 수집 과정이나 공개된 통계 정보를 통해 개인 정보가 간접적으로 노출되는 경우도 존재한다. 특히 개별 정보를 직접 공개하지 않더라도, 여러 통계 정보를 조합하여 민감한 정보를 추론할 수 있다는 점에서 이러한 문제는 더욱 주목받고 있다. 이번 포스트에서는 이러한 간접적인 정보 유출 사례들을 살펴보고, 이를 방지하기 위한 대표적인 프라이버시 보호 기법인 Differential Privacy에 대해 알아본다.
1. What is Differential Privacy?
Differential Privacy(DP)는 한 사람의 데이터가 있든 없든 분석 결과가 거의 같게 나오도록 만드는 프라이버시 보호 기법이다.
예를 들어 어떤 기관이 데이터 분석 결과를 공개한다고 하자. 공격자는 이 결과를 이용해 특정 사람이 데이터베이스에 포함되어 있는지 추론하려고 할 수 있다. DP의 목표는 이러한 추론을 어렵게 만드는 것이다. 이를 위해 알고리즘의 결과에 적절한 무작위성을 추가하여, 한 사람의 데이터를 추가하거나 제거하더라도 결과가 크게 달라지지 않도록 만든다.
수학적으로, 알고리즘 $A$가 데이터베이스 $d$를 입력받아 출력 공간 $O$의 값을 반환한다고 하자. 이때 $A$가 $(\epsilon,\delta)$-DP가 만족한다는 것은 distance metric $\rho$에 대해 $\rho(d,d’) \le 1$인 임의의 두 데이터베이스 $d,d’$와 모든 $S \subseteq O$에 대하여 아래가 성립함을 의미한다. \[P(A(d)\in S) \le e^\epsilon P(A(d')\in S) + \delta.\]
여기서 $\delta \in [0,1]$이다.
일반적으로 $\rho$로는 Hamming distance를 사용하며, 이는 두 데이터베이스가 최대 한 개의 레코드에서만 차이가 난다는 의미이다. 따라서 DP를 만족하는 알고리즘은 특정 개인의 데이터를 추가하거나 제거하더라도 출력 분포가 크게 변하지 않는다. 즉, $A$의 결과를 관찰하더라도 특정 개인의 데이터가 사용되었는지 여부를 알아내기 어렵게 된다.
DP는 크게 Central Differential Privacy(CDP) 와 Local Differential Privacy(LDP) 로 나뉜다. 두 방식은 비슷한 프라이버시 목표를 가지지만 데이터를 수집하고 보호하는 방식에는 큰 차이가 있다. 이후에는 각각이 어떤 환경에서 사용되는지 실제 사례와 함께 살펴본다.
또한 DP에는 Post-processing Property, Composition, Privacy Amplification by Sampling, Group Privacy 와 같은 중요한 성질들이 존재한다. 이러한 성질들은 단순한 이론적 결과가 아니라 실제 DP 시스템을 설계하고 분석하는 데 핵심적인 역할을 한다. 더 깊이 공부하고 싶다면 The Algorithmic Foundations of Differential Privacy를 참고하길 바란다.
2. What is Central Differential Privacy?
Central Differential Privacy(CDP)는 사용자의 원본 데이터를 신뢰할 수 있는 중앙 서버가 수집한 뒤, 통계나 분석 결과를 공개할 때 노이즈를 추가하여 개별 레코드의 정보가 노출되지 않도록 보호하는 방식이다. 왜 이러한 보호 기법이 필요한지 간단한 예를 통해 살펴보자.
어느 기업의 IT 부서에는 총 11명의 직원이 근무하고 있으며, 그중 한 명은 부서장인 철수이다. 회사는 직원들의 연봉 정보를 직접 공개하지 않고 아래와 같은 통계만 공개하였다.
* IT 부서 전체 직원(11명)의 평균 연봉 : 6,000만 원
* 철수를 제외한 일반 직원(10명)의 평균 연봉 : 5,500만 원
겉보기에는 개별 연봉이 공개되지 않았기 때문에 안전해 보인다. 하지만 공격자는 간단한 계산만으로 철수의 연봉을 정확하게 알아낼 수 있다.
이처럼 개별 정보를 직접 공개하지 않더라도 여러 통계 정보를 조합하면 특정 개인의 정보를 추론할 수 있는 경우가 존재한다. Central Differential Privacy는 이러한 문제를 방지하기 위해 공개되는 통계값에 적절한 무작위 노이즈를 추가한다. 그러면 공격자가 동일한 계산을 수행하더라도 정확한 연봉을 복원할 수 없게 된다.
오늘날 많은 기관과 기업들이 이러한 방식으로 데이터를 분석하고 공개하며, 대표적인 사례로 미국 Census를 들 수 있다. 미국 Census Bureau는 2020 Census부터 DP를 도입하였는데, 그 배경에는 2010 Census에서 발견된 심각한 프라이버시 문제가 있었기 때문이다. 이를 설명하기 위해 Census Bureau는 아래의 기술 보고서를 공개하였다.
2.1. A Simulated Reconstruction and Reidentification Attack on the 2010 U.S. Census
Differential Privacy가 주목받게 된 이유 중 하나는, 기존에 안전하다고 여겨졌던 통계 공개 방식이 생각보다 많은 정보를 노출할 수 있다는 사실이 밝혀졌기 때문이다.
오랫동안 통계 기관들은 집계 통계표(tabular data)를 공개하는 것은 안전하다고 생각해 왔다. 집계 통계표란 개별 데이터를 직접 공개하는 대신 여러 사람의 데이터를 합쳐 생성한 통계 결과를 의미한다. 예를 들어 특정 지역의 인구 수, 성별 분포, 연령 분포 등이 이에 해당한다. 반면 공개용 microdata는 이름이나 주소와 같은 직접 식별자를 제거한 뒤 공개하는 개인 단위 데이터셋이다. 일반적으로 집계 통계는 개별 레코드가 드러나지 않기 때문에 microdata보다 안전하다고 여겨졌다.
하지만 2010 U.S. Census를 대상으로 수행된 연구는 이러한 가정이 항상 성립하지는 않음을 보여주었다. 2010 Census는 총 180개의 table set에 걸쳐 1,500억 개 이상의 집계 통계를 공개하였다. 연구진은 이 중 34개의 table set만 사용하여 reconstruction attack을 수행하였고, 공개된 통계만으로도 원본 데이터의 상당 부분을 복원할 수 있음을 보였다.
구체적으로 공격자는 (census block, sex, age, race, ethnicity) 로 구성된 개별 레코드를 재구성할 수 있었다. 여기서 census block은 Census에서 사용하는 가장 작은 통계 단위이다. 예를 들어 특정 census block에 대해 다음과 같은 정보가 복원될 수 있다.
* 17세 흑인 남성 1명
* 43세 백인 여성 1명
* 68세 아시아인 남성 1명
물론 이 정보만으로 개인의 이름을 바로 알 수 있는 것은 아니다. 그러나 외부 데이터와 결합할 경우 실제 개인을 식별할 가능성이 생긴다. 이 연구가 보여준 핵심은 단순하다. 개별 데이터를 공개하지 않더라도, 충분히 많은 집계 통계가 공개되면 원본 데이터에 대한 정보를 역으로 추론할 수 있다. 이러한 reconstruction attack의 위험성 때문에 미국 Census Bureau는 2020 Census부터 Differential Privacy 기반의 Disclosure Avoidance System을 도입하게 되었다.
3. What is Local Differential Privacy?
앞서 살펴본 Central Differential Privacy(CDP)는 서버가 사용자의 원본 데이터를 수집한 뒤, 통계나 분석 결과를 공개할 때 노이즈를 추가하여 개인정보를 보호하는 방식이다. 반면 Local Differential Privacy(LDP) 는 사용자의 데이터가 서버에 전달되기 전에 클라이언트 측에서 먼저 노이즈를 추가하는 방식이다. 따라서 서버는 원본 데이터를 직접 수집하지 않으며, 개별 사용자가 실제로 어떤 응답을 했는지 알 수 없다.
이것을 이해하기 위해 다음과 같은 예를 생각해 보자. 어느 학교에서 학생 1,000명을 대상으로 ` “시험에서 부정행위를 한 적이 있습니까?”`와 같은 민감한 설문조사를 진행한다고 하자. 학생들은 솔직하게 답했다가 불이익을 받을 수 있다고 생각하여 진실을 말하기를 꺼릴 수 있다. 이를 해결하기 위해 선생님은 다음과 같은 규칙을 제안한다.
- 다른 사람이 보지 않는 곳에서 동전을 던진다.
- 앞면이 나오면 실제 여부와 관계없이 무조건 “네”라고 답한다.
- 뒷면이 나오면 자신의 실제 답변을 그대로 말한다.
이 규칙을 사용하면 어떤 학생이 “네”라고 답하더라도 그 학생이 실제로 부정행위를 한 것인지, 아니면 동전 앞면이 나와서 그렇게 답한 것인지 알 수 없다. 즉, 개별 응답자의 프라이버시가 보호된다. 이처럼 Local Differential Privacy에서는 개별 사용자의 응답을 먼저 무작위화(randomization)하여 프라이버시를 보호한다. 서버는 원본 응답을 알 수 없지만, 충분히 많은 사용자의 데이터를 수집하면 전체 집단의 통계적 특성은 여전히 추정할 수 있다.
대표적으로 Apple과 Google은 일부 데이터 수집 과정에서 Local Differential Privacy 기법을 활용한 바 있다. 그렇다면 실제 서비스에서는 이러한 기법이 어떻게 사용될까? Apple의 사례를 통해 Local Differential Privacy가 실제로 적용되는 방식을 살펴보자.
3.1. Understanding Aggregate Trends for Apple Intelligence Using Differential Privacy
Apple은 Differential Privacy를 실제 서비스에 어떻게 활용하는지 Machine Learning Research 블로그 포스트를 통해 공개하였다.
해당 글에서는 Genmoji와 같은 기능에서 사용자가 자주 사용하는 프롬프트 패턴을 어떻게 수집하는지, 그리고 이메일 요약과 같은 기능에서 실제 이메일 내용을 수집하지 않으면서도 사용자 데이터의 전반적인 경향을 파악하기 위해 Differential Privacy와 synthetic data를 어떻게 활용하는지를 소개한다.
3.1.1. GEnmoji: AI-generated emojis created using Apple Intelligence
Apple은 Genmoji와 같은 서비스를 개선하기 위해 사용자들이 어떤 종류의 프롬프트를 자주 사용하는지 파악할 필요가 있다. 예를 들어 "dinosaur in a cowboy hat" 과 같이 여러 개의 객체가 포함된 요청이 빈번하게 사용된다면, Apple은 이러한 유형의 요청에 대한 모델의 성능을 평가하고 개선할 수 있다.
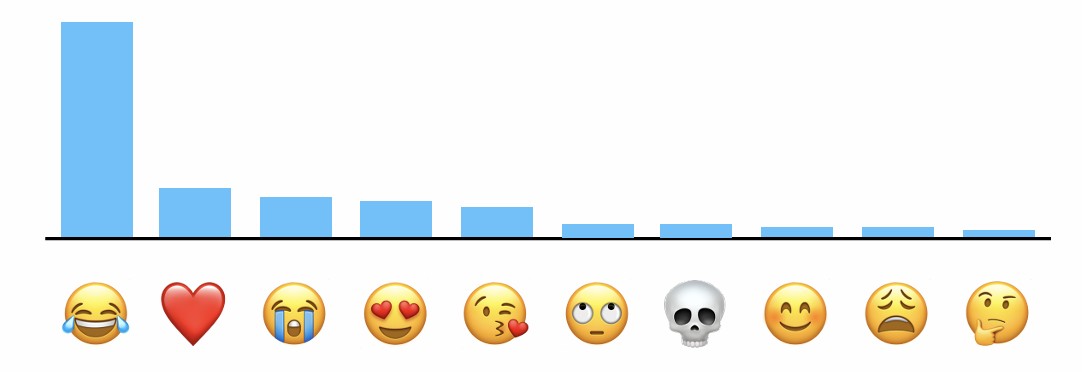
하지만 사용자의 프롬프트를 그대로 수집한다면 개인정보 침해 문제가 발생할 수 있다. 이를 방지하기 위해 Apple은 Local Differential Privacy를 사용한다. 사용자가 입력한 프롬프트는 기기 내부에서 먼저 무작위화된 뒤 서버로 전송되며, Apple은 특정 사용자가 어떤 프롬프트를 입력했는지 알 수 없다.
대신 수많은 사용자의 데이터를 통계적으로 집계하여 자주 사용되는 프롬프트의 경향만 파악할 수 있다. 따라서 널리 사용되는 요청 패턴은 분석할 수 있지만, 특정 사용자만 입력한 희귀한 프롬프트나 개별 사용자의 입력 내용은 복원할 수 없다. 또한 수집된 정보는 IP 주소나 Apple ID와 연결되지 않기 때문에 특정 사용자나 특정 기기를 식별하는 것도 불가능하다.
3.1.2. Improving Text Generation with Synthetic Data
Apple은 이메일 요약과 같은 Apple Intelligence 기능을 개선하기 위해 사용자들이 실제로 어떤 종류의 이메일을 주고받는지 알고 싶다. 예를 들어 회의 일정, 배송 안내, 스포츠 약속과 같은 주제 중 어떤 것들이 자주 등장하는지 알 수 있다면 모델을 더 효과적으로 평가하고 개선할 수 있다.
하지만 여기에는 문제가 있다. Apple은 사용자의 실제 이메일을 수집하거나 읽고 싶지 않으며, 개인정보 보호 기준상 그렇게 해서도 안 된다. 그렇다면 실제 이메일을 보지 않고 어떻게 사용자들의 이메일 분포를 파악할 수 있을까?
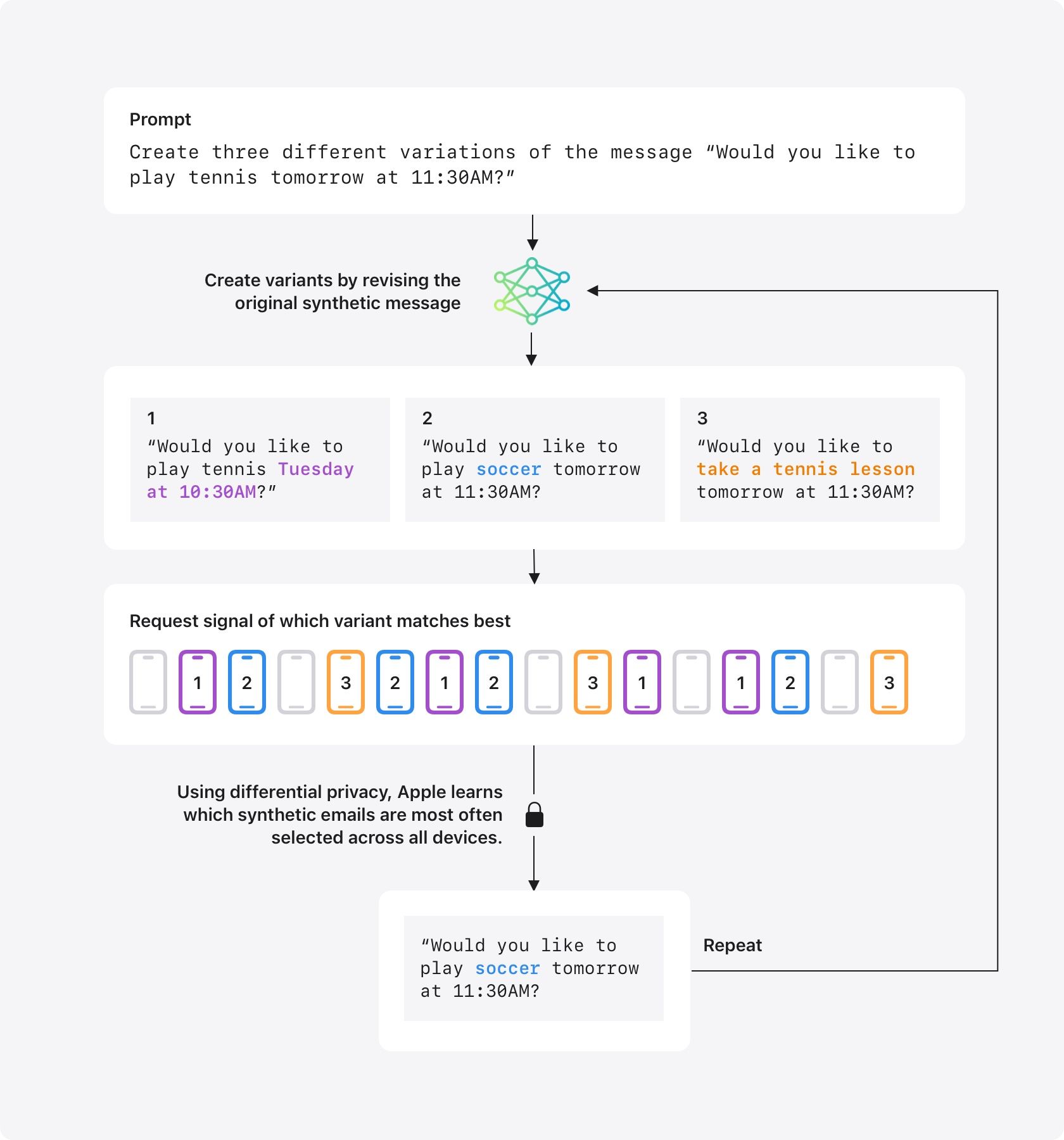
Apple은 이 문제를 해결하기 위해 먼저 LLM을 이용해 다양한 synthetic email을 생성한다. 예를 들어 다음과 같은 가상의 이메일을 만든다.
Would you like to play tennis tomorrow at 11:30 AM?
이후 이 이메일을 조금씩 변형한 여러 개의 variant를 생성한다.
Would you like to play tennis Tuesday at 10:30 AM? Would you like to play soccer tomorrow at 11:30 AM? Would you like to take a lesson tomorrow at 11:30 AM?
이제 사용자의 기기에서는 최근 이메일들을 살펴본 뒤, 어떤 variant가 실제 이메일과 가장 비슷한지 판단한다. 예를 들어 사용자의 이메일에 축구 약속과 관련된 내용이 많다면 soccer variant가 가장 적합하다고 선택될 수 있다.
하지만 이 선택 결과가 그대로 Apple에 전달되지는 않는다. 기기는 LDP를 적용하여 노이즈가 섞인 신호만 전송한다. 따라서 Apple은 특정 사용자가 어떤 이메일을 가지고 있었는지, 혹은 어떤 variant를 선택했는지를 알 수 없다.
대신 수많은 기기로부터 이러한 신호를 수집하면 어떤 종류의 synthetic email이 자주 선택되는지는 파악할 수 있다. 만약 soccer와 관련된 variant가 반복적으로 선택된다면, Apple은 실제 이메일을 읽지 않고도 해당 주제가 사용자들 사이에서 자주 등장한다는 사실을 알 수 있다.
이렇게 얻은 정보를 바탕으로 Apple은 새로운 synthetic email을 생성한다. 예를 들어 soccer 관련 메시지가 많이 선택되었다면 다음 단계에서는 soccer practice, soccer game, soccer tournament와 같은 더욱 세분화된 메시지를 추가로 생성할 수 있다. 이후 동일한 과정을 반복하면서 synthetic dataset을 점점 실제 사용자 데이터의 분포에 가깝게 업데이트한다.
결과적으로 Apple은 사용자의 이메일을 한 번도 수집하지 않으면서도, 실제 사용자들이 어떤 주제와 표현을 자주 사용하는지 파악할 수 있다. 그리고 이렇게 구축된 synthetic dataset을 이용해 이메일 요약과 같은 Apple Intelligence 기능을 평가하고 개선한다.
참고자료
- A Simulated Reconstruction and Reidentification Attack on the 2010 U.S. Census
- Understanding Aggregate Trends for Apple Intelligence Using Differential Privacy
