Batch Normalization
in projects on Blog, Github, Pages, Jekyll, Spacy, Regularization, Normalization
딥러닝 모델은 일반적으로 Gradient Descent를 사용하여 학습되며, 효율적인 최적화를 위해 입력 데이터의 분포를 적절히 조정하는 것이 중요하다. 입력 feature들의 스케일이 크게 다르거나 강한 상관관계를 가지면 최적화가 어려워질 수 있기 때문에, Standardization, Decorrelation, Whitening과 같은 전처리 기법이 사용된다. 이러한 아이디어를 네트워크 내부의 각 레이어에 적용한 것이 Batch Normalization이며, 이는 학습을 안정화하고 학습 속도를 향상시키는 데 도움을 준다. 이 포스트에서는 Batch Normalization의 동작 원리를 살펴보고, 왜 이 기법이 딥러닝 학습에 효과적인지 분석한다.
1. Why Batch Normalization?
딥러닝은 복잡한 문제를 해결하기 위해 여러 개의 레이어로 구성된 심층 신경망을 학습한다. 이러한 모델은 일반적으로 Gradient Descent 계열의 최적화 알고리즘을 사용하여 파라미터를 업데이트한다.
Gradient Descent가 효율적으로 동작하기 위해서는 입력 데이터의 스케일과 분포가 적절하게 조정되는 것이 중요하다. 입력 feature들의 스케일이 크게 다르거나 서로 강한 상관관계를 가지는 경우, 최적화 문제가 ill-conditioned해질 수 있으며 이는 학습 속도를 저하시킨다.
이러한 문제를 완화하기 위해 입력 데이터에 다양한 전처리 기법이 사용된다. 대표적으로 Normalization, Decorrelation, Whitening 등이 있다. 실제로는 계산 비용과 구현의 단순성 때문에 Whitening보다는 Standardization이 훨씬 널리 사용되며, 대부분의 딥러닝 모델에서 기본적인 전처리 방법으로 자리 잡았다.
그렇다면 입력 데이터뿐 아니라 네트워크 내부의 각 레이어로 전달되는 활성값(activation) 역시 적절한 분포를 유지하도록 만들면 학습을 더욱 쉽게 만들 수 있지 않을까? 이러한 아이디어에서 출발한 기법이 Batch Normalization(BN)이다. Batch Normalization은 각 레이어의 입력을 정규화하여 학습을 안정화하고, 더 큰 학습률을 사용할 수 있도록 하며, 결과적으로 딥러닝 모델의 학습을 크게 가속화한다.
2. Two Perspectives on Why Batch Normalization Works
이번 글에서는 Batch Normalization(BN)이 어떻게 동작하는지, 그리고 왜 딥러닝 학습에 효과적인지 살펴본다. 이를 위해 Batch Normalization을 처음 제안한 논문인 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift와, 이후 BN의 성공 원인을 재분석한 How Does Batch Normalization Help Optimization?을 중심으로 리뷰한다.
먼저 Batch Normalization 논문은 BN의 핵심 효과를 Internal Covariate Shift(ICS) 의 완화로 설명한다. 저자들은 학습 과정에서 이전 레이어의 파라미터가 변화함에 따라 각 레이어의 입력 분포가 지속적으로 변하는 현상이 최적화를 어렵게 만든다고 주장한다. BN은 각 레이어의 입력을 정규화하여 이러한 분포 변화를 줄이고, 활성화 함수가 saturation 영역에 머무르는 비율을 감소시켜 학습을 안정화한다. 또한 BN은 가중치의 크기(scale)에 대해 출력이 불변인 특성을 가지므로, 모델이 단순히 weight norm을 키우는 방향이 아니라 실제로 유의미한 방향의 변화를 학습하도록 유도한다고 설명한다.
반면 How Does Batch Normalization Help Optimization?은 BN의 성능 향상이 정말 ICS 감소 때문인지 면밀히 분석한다. 흥미롭게도 실험 결과 BN을 사용하더라도 ICS가 반드시 감소하지 않으며, 경우에 따라서는 오히려 증가할 수도 있음을 보인다. 대신 저자들은 BN의 핵심 효과가 손실 함수의 지형(loss surface)을 더 부드럽고 예측 가능하게 만드는 데 있다고 주장한다. 이러한 성질은 gradient의 변화를 안정화하여 더 큰 learning rate를 사용할 수 있게 만들고, 결과적으로 최적화를 더욱 빠르고 안정적으로 수행할 수 있도록 한다.
즉, 첫 번째 논문은 BN의 효과를 “입력 분포 변화의 감소” 관점에서 설명하는 반면, 두 번째 논문은 BN이 최적화 문제 자체를 더 잘-conditioned하게 만든다는 관점에서 그 성공 원인을 해석한다. 이번 글에서는 두 논문의 주장과 실험 결과를 비교하며 Batch Normalization의 동작 원리를 자세히 살펴본다.
3. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Batch Normalization(BN)은 원래 논문에서 Internal Covariate Shift(ICS)를 완화하여 딥러닝 학습을 가속화하는 방법으로 제안되었다.
BN의 아이디어를 이해하기 위해 먼저 입력 데이터 전처리가 최적화에 미치는 영향을 살펴보자. 전통적인 머신러닝에서는 입력 데이터에 대해 Normalization, Decorrelation, Whitening과 같은 변환을 수행하면 Gradient Descent의 수렴 속도를 향상시킬 수 있다는 사실이 잘 알려져 있다.
\begin{itemize} \item \textbf{Normalization}: 각 feature의 평균과 분산을 조정하여 스케일 차이를 제거한다. \item \textbf{Decorrelation}: feature들 사이의 상관관계를 제거한다. \item \textbf{Whitening}: Normalization과 Decorrelation을 동시에 수행하여 공분산 행렬을 단위행렬로 만든다. \end{itemize}
이러한 변환이 중요한 이유는 최적화 문제의 condition number를 개선할 수 있기 때문이다. Condition number가 크면 손실 함수의 곡률(curvature)이 방향에 따라 크게 달라져 Gradient Descent가 비효율적으로 동작하게 된다.
이를 이해하기 위해 선형 회귀를 예로 들어보자. 평균이 제거된 데이터에 대해 평균제곱오차(MSE) 손실 함수는 다음과 같이 정의된다. \[\mathcal{L}(w) = \frac{1}{2}\|Xw-y\|_2^2\]
이 손실 함수의 Hessian은 다음과 같이 계산된다. \[H = \nabla_w^2 \mathcal{L}(w) = X^T X\]
한편 평균이 제거된 데이터의 공분산 행렬은 다음과 같이 표현할 수 있다. \[\Sigma = \frac{1}{N}X^T X\]
따라서 Hessian과 공분산 행렬 사이에는 다음 관계가 성립한다. \[H = N\Sigma\]
즉 선형 회귀에서는 Hessian의 고유값 구조가 입력 데이터의 공분산 구조와 직접 연결되어 있다.
만약 데이터가 강한 상관관계를 가지거나 feature마다 스케일 차이가 크다면 Hessian의 condition number가 커질 수 있다. 이러한 경우 Gradient Descent는 어떤 방향에서는 빠르게 이동하고 다른 방향에서는 매우 느리게 이동하게 되어 학습 효율이 떨어진다.
반면 Whitening을 적용하면 공분산 행렬은 다음과 같이 단위행렬이 된다. \[\Sigma = I\]
이 경우 모든 feature가 동일한 분산을 가지며 서로 상관관계가 없게 된다. 선형 회귀의 경우 Hessian 역시 단위행렬에 비례하게 되므로 condition number가 1이 되며, Gradient Descent는 모든 방향에서 동일한 속도로 수렴하게 된다.
그러나 Whitening은 실제 딥러닝에 적용하기 쉽지 않다. Whitening을 수행하려면 먼저 공분산 행렬을 계산한 뒤 그 역제곱근 행렬을 구해야 한다. \[\Sigma^{-1/2}\]
공분산 행렬의 역제곱근을 계산하려면 고유값 분해(eigendecomposition) 또는 SVD와 같은 연산이 필요하며, 이는 계산 비용이 매우 크다. 또한 신경망 학습 과정에서는 각 층의 입력 분포가 계속 변하므로 이러한 연산을 반복적으로 수행해야 한다.
Batch Normalization은 이러한 문제를 해결하기 위해 제안되었다. BN은 Whitening처럼 feature 간 상관관계를 제거하지는 않지만, 각 feature를 mini-batch의 평균과 분산을 이용하여 정규화한다. 이를 통해 계산 비용을 크게 증가시키지 않으면서도 입력 분포의 스케일 변화를 줄여 보다 안정적인 학습을 가능하게 한다.
3.1. BN Algorithm
\[\begin{aligned} \mu_B &\leftarrow \frac{1}{m}\sum_{i=1}^{m} x_i && \text{// mini-batch mean} \\ \sigma_B^2 &\leftarrow \frac{1}{m}\sum_{i=1}^{m}(x_i-\mu_B)^2 && \text{// mini-batch variance} \\ \hat{x}_i &\leftarrow \frac{x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}} && \text{// normalize} \\ y_i &\leftarrow \gamma \hat{x}_i + \beta \equiv \mathrm{BN}_{\gamma,\beta}(x_i) && \text{// scale and shift} \end{aligned}\]Batch Normalization은 먼저 activation을 평균 0, 분산 1이 되도록 정규화한 뒤, 학습 가능한 파라미터 $\gamma$와 $\beta$를 이용하여 적절한 scale과 shift를 다시 부여한다.
따라서 정규화된 activation $\hat{x}$는 평균 0, 분산 1을 가지지만, 최종 출력 $y$는 반드시 평균 0, 분산 1일 필요는 없다. 이를 통해 네트워크는 정규화의 이점을 유지하면서도 필요한 표현력을 잃지 않을 수 있다.
3.2. Why Batch Normalization works well
3.2.1. Mitigating Activation Saturation
sigmoid나 tanh와 같은 활성화 함수는 saturation regime이 존재한다. 입력값의 절댓값이 지나치게 커지면 활성화 함수의 기울기가 0에 가까워지며, 이로 인해 gradient propagation이 어려워진다. 그렇다고 활성화 함수를 제거할 수는 없다. 활성화 함수는 모델에 비선형성(non-linearity)을 부여하여 복잡한 함수를 학습할 수 있게 해주기 때문이다.
Batch Normalization은 activation의 분포를 평균 0, 분산 1에 가깝게 유지함으로써 입력값이 saturation regime에 과도하게 집중되는 현상을 완화한다. 결과적으로 더 많은 activation이 기울기가 충분히 큰 영역에 위치하게 되어 학습이 안정적으로 이루어질 수 있다.
일반적으로 Batch Normalization은 선형 변환과 활성화 함수 사이에 배치된다. \[x \rightarrow Wx+b \rightarrow \mathrm{BN} \rightarrow \mathrm{Activation}\]
ReLU 이후에 Batch Normalization을 적용하는 것도 가능하지만 실제로는 자주 사용되지 않는다. ReLU는 음수 입력을 모두 0으로 만들어 희소한(sparse) activation을 생성하는데, ReLU 뒤에 Batch Normalization을 적용하면 activation 분포가 다시 평균 0 부근으로 이동하면서 이러한 희소성이 감소할 수 있다. 따라서 일반적으로는 ReLU가 적용되기 전에 Batch Normalization을 수행하는 것이 더 효과적인 것으로 알려져 있다.
3.2.2. Scale Invariance with Respect to Weights
Batch Normalization의 중요한 성질 중 하나는 weight의 크기(scale)에 대해 불변(invariant)하다는 점이다.
어떤 층의 입력을 $u$, 가중치를 $W$라고 하자. 이때 선형 변환의 출력은 다음과 같이 표현할 수 있다. \[x = Wu\]
이제 가중치 전체를 양의 상수 $a$만큼 스케일링한다고 가정하자. 그러면 선형 변환의 출력은 다음과 같이 변한다. \[x' = aWu\]
그러나 Batch Normalization은 평균과 표준편차를 이용하여 activation을 정규화한다. 따라서 가중치의 크기를 스케일링하더라도 Batch Normalization 이후의 출력은 변하지 않는다. \[\mathrm{BN}(Wu) = \mathrm{BN}(aWu), \qquad a>0\]
즉 가중치의 절대적인 크기를 변경하더라도 정규화된 activation은 동일하게 유지된다.
이 성질은 학습 과정에도 영향을 준다. Batch Normalization이 적용된 경우 가중치의 크기가 증가할수록 해당 가중치에 대한 gradient의 크기는 감소하는 경향이 있다. \[\left\| \frac{\partial \mathcal{L}} {\partial W} \right\| \propto \frac{1}{\|W\|}\]
따라서 매우 큰 weight는 자연스럽게 작은 update를 받게 된다.
결과적으로 Batch Normalization이 적용된 네트워크는 단순히 weight의 크기를 조절하는 것보다 weight vector의 방향(direction)을 학습하는 데 더 집중하게 된다. 이는 최적화 과정을 안정화시키고 보다 큰 learning rate를 사용할 수 있게 하는 요인 중 하나이다.
3.2.3. Mean and Variance as Learnable Dependencies
Batch Normalization에서 사용되는 평균과 분산은 단순한 상수가 아니라 mini-batch의 입력으로부터 계산되는 함수이다. 따라서 역전파 과정에서도 평균과 분산을 계산 그래프의 일부로 취급해야 한다.
이를 이해하기 위해 분산 정규화는 무시하고 평균 제거만 수행하는 간단한 경우를 생각해 보자.
입력과 batch 평균은 다음과 같이 정의된다. \[x_i = u_i + b\] \[\mu_B = \frac{1}{N} \sum_{i=1}^{N} x_i\] \[\hat{x}_i = x_i-\mu_B\]
이제 평균 $\mu_B$를 입력 $x_i$에 의해 결정되는 변수로 취급해 보자.
아래 그림은 이러한 경우의 계산 그래프와 편미분 과정을 보여준다.
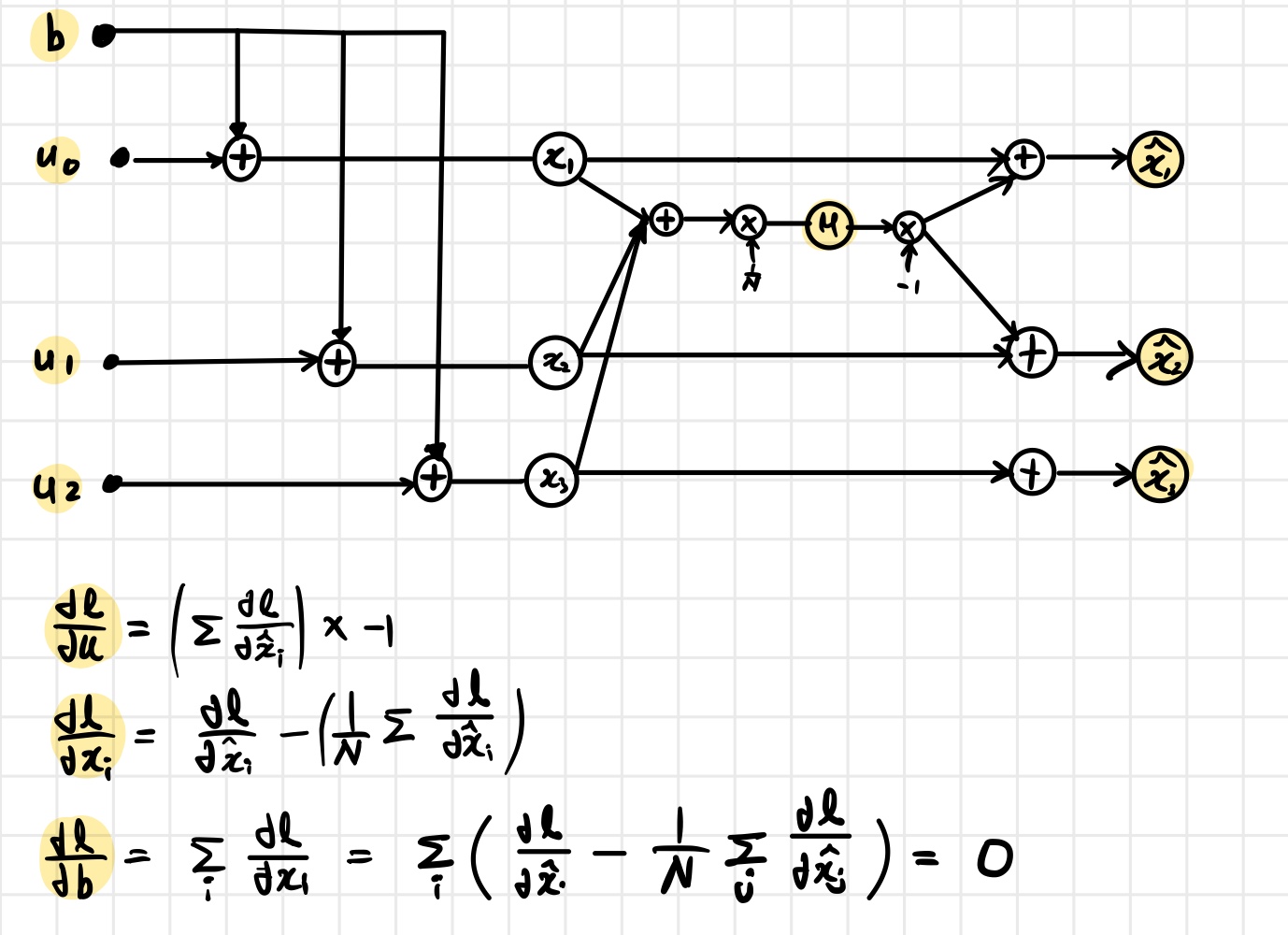
여기서 중요한 점은 bias $b$가 변하더라도 정규화된 출력은 변하지 않는다는 것이다.
실제로 $b$를 $\Delta b$만큼 증가시키면 모든 입력은 동일하게 이동한다. \[x_i' = u_i+b+\Delta b\]
이때 batch 평균 역시 동일하게 이동한다. \[\mu_B' = \mu_B+\Delta b\]
따라서 정규화된 출력은 \[\hat{x}_i' = x_i' - \mu_B' = x_i+\Delta b-(\mu_B+\Delta b) = \hat{x}_i\]
가 된다.
즉 입력이 변하더라도 정규화된 출력은 변하지 않는다. 따라서 손실 함수 역시 변하지 않으며 다음이 성립해야 한다. \[\frac{\partial \mathcal L}{\partial b} = 0\]
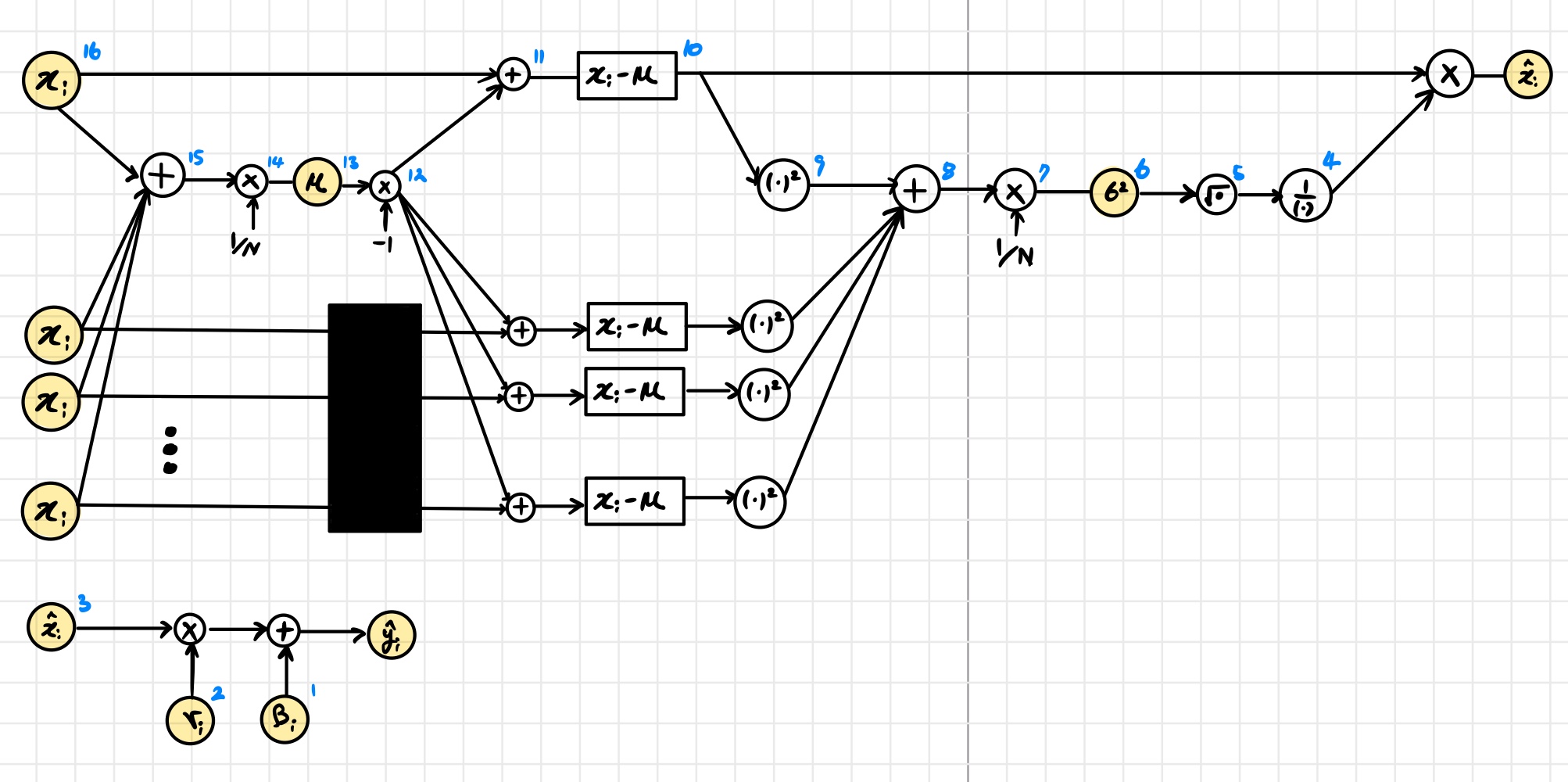
3.3 Backpropagation Through Batch Normalization

3.4. Applying Batch Normalization to CNNs
완전연결층(Fully Connected Layer)에서는 하나의 feature가 하나의 뉴런에 대응된다. 따라서 각 feature에 대해 mini-batch 차원에서 평균과 분산을 계산하고 이를 이용하여 정규화한다.
반면 CNN에서는 동일한 채널(channel)에 속한 activation들이 같은 convolution filter에 의해 생성된다. 따라서 같은 채널에 속한 activation들은 서로 유사한 feature를 나타낸다고 볼 수 있다.
입력 텐서의 크기가 $(B, C, H, W)$라고 하자. CNN의 Batch Normalization은 각 채널마다 평균과 분산을 계산한다. 즉 하나의 채널에 속한 모든 activation들이 동일한 정규화 통계를 공유한다.
이를 위해 채널 $c$의 평균은 batch 차원과 spatial 차원 전체에 대해 계산된다. \[\mu_c = \frac{1}{BHW} \sum_{b=1}^{B} \sum_{h=1}^{H} \sum_{w=1}^{W} x_{bchw}\]
마찬가지로 채널 $c$의 분산 역시 batch 차원과 spatial 차원 전체에 대해 계산된다. \[\sigma_c^2 = \frac{1}{BHW} \sum_{b=1}^{B} \sum_{h=1}^{H} \sum_{w=1}^{W} (x_{bchw}-\mu_c)^2\]
따라서 동일한 채널에 속한 모든 activation은 같은 평균과 분산을 사용하여 정규화된다. 이는 같은 채널의 activation들이 동일한 feature detector의 출력이라는 CNN의 구조적 특성을 반영한 것이다.
4. How Does Batch Normalization Help Optimization?
Batch Normalization을 제안한 원 논문에서는 Internal Covariate Shift(ICS)를 완화함으로써 딥러닝 학습을 가속화한다고 설명하였다.
그러나 이 논문은 Batch Normalization의 효과가 반드시 ICS 감소 때문은 아닐 수 있다고 주장하였다. 저자들은 Batch Normalization을 사용하더라도 Internal Covariate Shift가 실제로 줄어들지 않을 수 있으며, 오히려 Batch Normalization이 loss landscape를 더 smooth하게 만들어 최적화를 쉽게 한다고 설명하였다.
이를 뒷받침하기 위해 저자들은 loss와 gradient의 Lipschitzness를 분석하였다. Batch Normalization이 적용되면 작은 parameter 변화에 대해 loss와 gradient가 급격하게 변하지 않으며, 결과적으로 최적화가 더욱 안정적으로 이루어진다는 것을 보였다.
Loss landscape가 smooth해지면 여러 가지 장점이 생긴다. 먼저 현재 gradient가 다음 step에서도 비슷하게 유지되므로 gradient의 예측 가능성(gradient predictiveness)이 높아진다. 또한 더 넓은 범위의 learning rate를 사용할 수 있으며, 결과적으로 네트워크의 수렴 속도도 빨라질 수 있다.
4.1. Why Can Batch Normalization Use Larger Learning Rates?
Gradient Descent는 현재 위치에서 계산한 gradient를 이용하여 다음 위치를 결정한다. 따라서 parameter를 조금 이동했을 때 gradient가 급격하게 변하지 않는 것이 중요하다.
Batch Normalization은 loss landscape를 더욱 smooth하게 만들어 gradient가 급격하게 변하는 현상을 완화한다. 즉 현재 step에서 계산한 gradient와 다음 step에서 계산되는 gradient가 서로 유사하게 유지된다.
따라서 learning rate를 다소 크게 설정하더라도 최적화 경로가 크게 흔들리지 않으며, 보다 안정적으로 학습을 진행할 수 있다.
또한 gradient가 $L$-Lipschitz 조건을 만족한다고 가정하면 learning rate는 일반적으로 다음 조건을 만족해야 한다. \[\eta < \frac{2}{L}\]
따라서 Lipschitz constant $L$이 작을수록 사용할 수 있는 learning rate의 범위가 넓어진다.
Batch Normalization은 loss landscape를 smooth하게 만들어 Lipschitz constant를 감소시키므로, 더 큰 learning rate를 안정적으로 사용할 수 있게 해준다.
4.2. Questioning the Internal Covariate Shift Explanation
4.2.1. Evidence Against the Internal Covariate Shift Hypothesis
만약 Batch Normalization의 효과가 Internal Covariate Shift를 줄이는 데 있다면, 인위적으로 Internal Covariate Shift를 증가시켰을 때 학습 성능은 크게 저하되어야 한다.
이를 검증하기 위해 저자들은 Batch Normalization을 적용한 네트워크의 activation에 랜덤 노이즈를 추가하여 Internal Covariate Shift를 의도적으로 증가시키는 실험을 수행하였다.
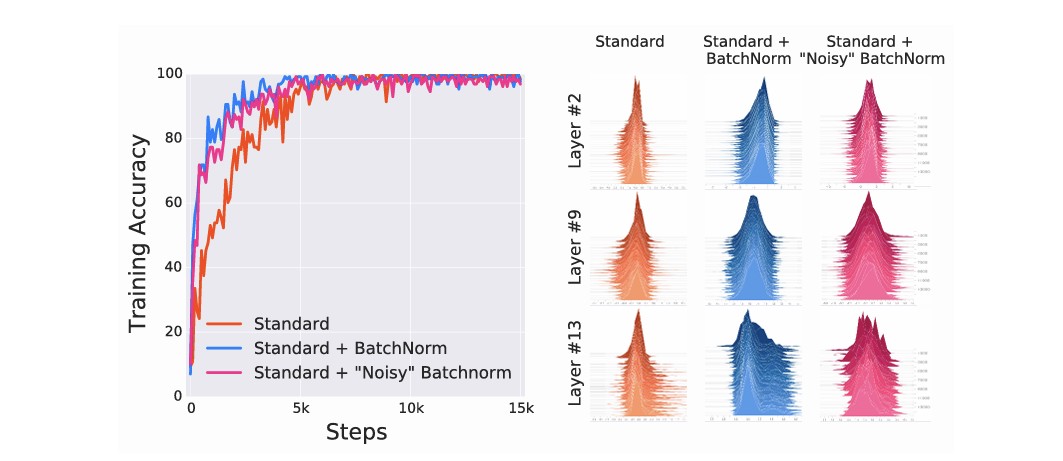
흥미롭게도 Internal Covariate Shift가 증가했음에도 불구하고 모델은 여전히 안정적으로 학습되었다.
이 결과는 Batch Normalization의 효과를 단순히 Internal Covariate Shift 감소만으로 설명하기 어렵다는 점을 보여준다.
4.2.2. Evidence Against the Internal Covariate Shift Hypothesis
이 실험에서는 이전 layer를 한 번 업데이트한 뒤 현재 layer가 받는 영향이 얼마나 큰지를 측정한다.
만약 Batch Normalization이 Internal Covariate Shift를 줄인다면, 이전 layer가 업데이트되더라도 현재 layer가 보는 입력 분포는 크게 변하지 않아야 한다.
이를 확인하기 위해 저자들은 업데이트 전후의 gradient 차이를 측정하였다.
아래 그림에서 볼 수 있듯이 Batch Normalization을 사용한 경우에도 gradient 변화량은 작아지지 않았으며 오히려 더 크게 나타났다.
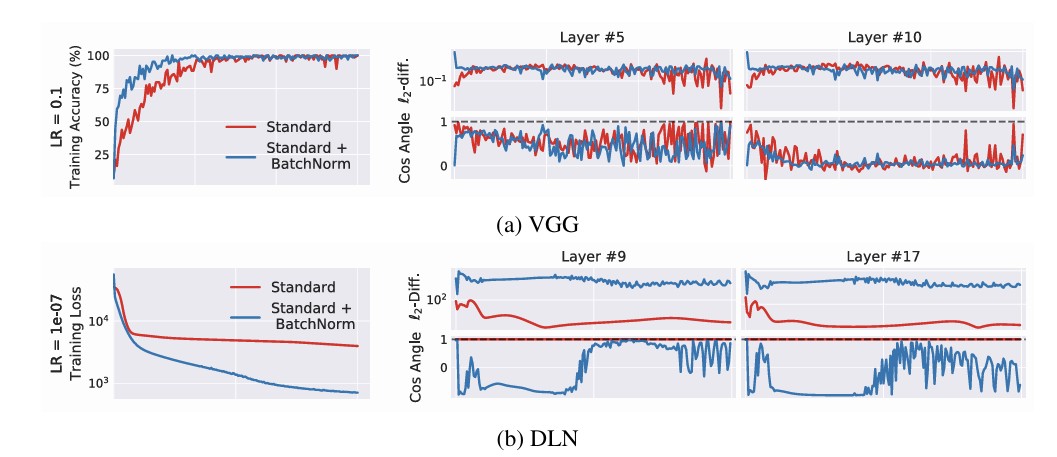
이는 Batch Normalization이 실제로 Internal Covariate Shift를 감소시키는 것은 아니라는 점을 시사한다. 따라서 Batch Normalization의 효과를 단순히 Internal Covariate Shift 감소만으로 설명하기는 어렵다.
4.2.3. Smoother Loss Landscape
저자들은 Batch Normalization이 실제로 loss landscape를 더욱 smooth하게 만든다는 사실을 실험적으로 확인하였다.
먼저 parameter를 한 번 업데이트한 이후 gradient가 얼마나 변하는지를 측정하였다. Loss landscape가 smooth하다면 업데이트 전후의 gradient는 서로 유사해야 한다.
실험 결과 Batch Normalization을 사용한 경우 gradient의 변화가 더 작게 나타났으며, 이는 현재 gradient가 다음 step의 gradient를 더 잘 예측할 수 있음을 의미한다.
또한 loss landscape를 시각화한 결과 Batch Normalization을 적용한 경우 훨씬 완만한 형태의 landscape가 형성되는 것을 확인할 수 있었다.
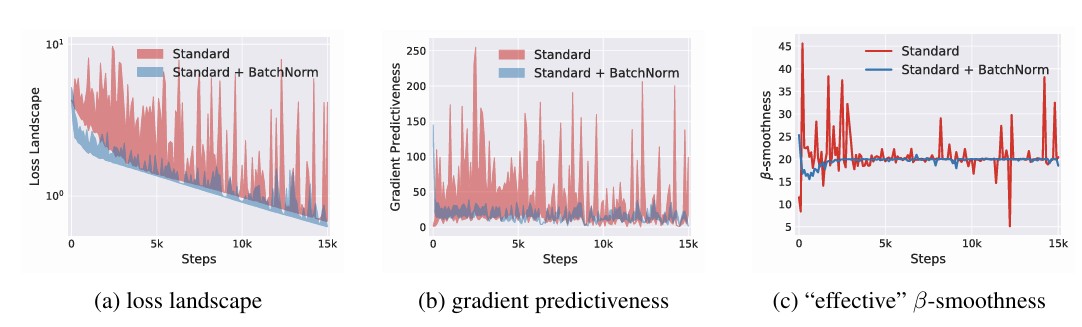
마지막으로 loss와 gradient의 Lipschitz constant를 측정한 결과 역시 Batch Normalization을 사용한 경우 더 작은 값을 보였다.
이는 Batch Normalization이 최적화 문제를 더 잘 조건화된 형태로 만들어 학습을 용이하게 한다는 사실을 보여준다.
참고
[블로그]
[논문]
Batch Normalization: Accelerating Deep Network Training by, Reducing Internal Covariate Shift
How Does Batch Normalization Help Optimization?
