Adversarial Training
in projects on Blog, Github, Pages, Jekyll, Spacy
딥러닝은 연구 단계를 넘어 우리 일상생활의 다양한 분야에 활용되고 있다. 대표적인 예로 자율주행, 문자 인식(OCR), 음성 인식, 스팸 탐지 등이 있으며, 이러한 기술들은 우리의 삶을 더욱 편리하게 만들어 주고 있다. 하지만 딥러닝 모델이 잘못된 판단을 내릴 경우 그 영향은 단순한 오류를 넘어 심각한 사고로 이어질 수 있다. 예를 들어 도로에 출입금지 표지판이 있을 때 자율주행 시스템이 이를 올바르게 인식한다면 해당 도로로 진입하지 않을 것이다. 그러나 누군가 표지판에 작은 스티커를 붙이거나 특정한 패턴을 추가했을 때, 사람은 여전히 이를 출입금지 표지판으로 인식하지만 딥러닝 모델은 다른 표지판으로 오인식하거나 아예 인식하지 못할 수 있다. 그 결과 차량이 잘못된 경로로 진입하는 등의 문제가 발생할 수 있다. 이처럼 입력에 사람이 인지하기 어려운 작은 변화를 가해 모델의 예측을 크게 변화시키는 입력을 adversarial example(적대적 예제) 이라고 한다. 이번 포스트에서는 현실 세계에서 발생할 수 있는 adversarial example의 사례를 살펴보고, 이러한 현상이 왜 발생하는지 그리고 이를 방어하기 위한 방법에는 무엇이 있는지 알아본다.
Real-World Examples of Adversarial Attacks
딥러닝 모델은 다양한 실제 시스템에 적용되고 있으며, adversarial attack은 더 이상 이미지 분류기의 장난감 문제가 아니다. 자율주행, 얼굴 인식, 음성 인식, 추천 시스템, 대규모 언어 모델(LLM) 등 실제 서비스에서도 adversarial example이 연구되고 있다.
대표적으로 자율주행 시스템은 도로 표지판 인식, 차선 인식, 보행자 탐지 등 다양한 컴퓨터 비전 기술에 의존한다.
실제로 Robust Physical-World Attacks on Deep Learning Models에서는 정지 표지판에 검은색과 흰색 스티커를 부착하여 객체 인식 모델이 이를 다른 표지판으로 오인하도록 만드는 공격을 제안하였다. 연구진은 실제 도로 환경에서 촬영한 영상에서도 공격이 성공함을 보였으며, 이동 중인 차량이 촬영한 프레임의 상당수에서 오인식이 발생함을 보고하였다.

또 다른 연구인 Simple Physical Adversarial Examples against End-to-End Autonomous Driving Models에서는 도로 위에 단순한 검은 선 몇 개를 추가하는 것만으로도 차량의 조향을 교란할 수 있음을 보였다. 연구 결과, 이러한 패턴은 차선 이탈이나 충돌을 유발할 수 있었으며, 특히 우회전 구간에서 높은 공격 성공률을 보였다.

자율주행뿐만 아니라 얼굴 인식 시스템에서도 adversarial attack이 가능하다. Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition에서는 adversarial 패턴이 포함된 안경을 제작하여 얼굴 인식 시스템이 공격자를 다른 사람으로 인식하도록 만드는 공격을 시연하였다.

이와 유사하게 Real-World Adversarial Attack on ArcFace Face ID System (AdvHat)에서는 모자에 부착한 작은 패턴만으로도 얼굴 인식 시스템이 사용자를 올바르게 인식하지 못하도록 만들 수 있음을 보였다.
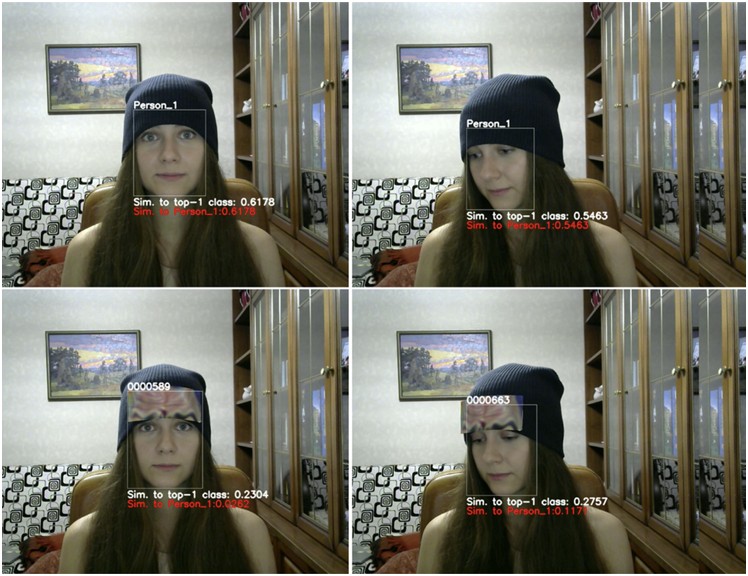
이러한 공격은 공항 출입국 심사, 회사 출입 통제, 스마트폰 Face ID와 같은 실제 인증 시스템에 영향을 줄 수 있기 때문에 큰 관심을 받고 있다.
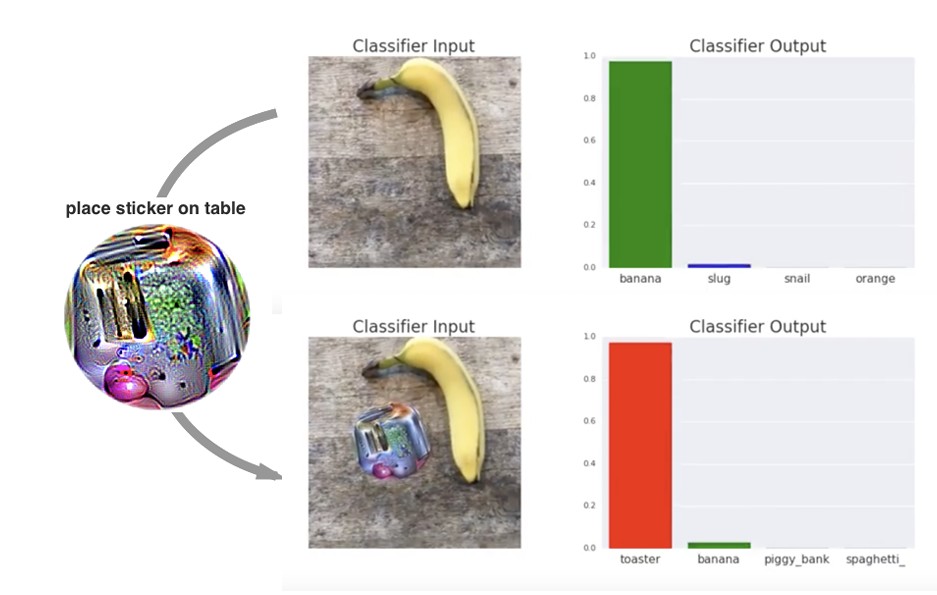
얼굴 인식뿐만 아니라 일반적인 객체 인식 모델 역시 취약하다. Adversarial Patch에서는 이미지의 일부에 작은 패치를 부착하는 것만으로도 객체 인식 모델이 특정 클래스로 오인하도록 만들 수 있음을 보였다. 즉, 공격자는 전체 이미지를 수정하지 않고도 모델의 예측을 조작할 수 있다.
Computer Vision 분야뿐만 아니라 음성 인식 분야에서도 adversarial example이 연구되고 있다. Practical Hidden Voice Attacks against Speech and Speaker Recognition Systems에서는 사람이 거의 이해하지 못하는 음성을 생성했음에도 음성 인식 시스템은 이를 정상적인 명령으로 인식할 수 있음을 보였다. 실제 예시는 해당 연구의 데모 페이지에서 확인할 수 있다.
이러한 사례들은 adversarial example이 특정 연구 환경에만 존재하는 현상이 아니라 실제 시스템에서도 문제가 될 수 있음을 보여준다. 또한 추천 시스템에서는 특정 콘텐츠가 추천 결과 상위에 노출되도록 유도하는 shilling attack과 poisoning attack이 연구되고 있으며, 최근에는 ChatGPT, Claude, Gemini와 같은 대규모 언어 모델을 대상으로 한 Prompt Injection, Jailbreak, Indirect Prompt Injection 등의 공격도 활발하게 연구되고 있다.
Adversarial Examples related papers
그렇다면 adversarial example은 어떻게 생성되는 것일까? 또한 왜 딥러닝 모델은 이러한 입력에 취약하며, 이를 방어하기 위해 어떤 연구들이 제안되었을까? Adversarial example 연구는 공격 기법의 발전과 방어 기법의 발전이 반복적으로 이루어지며 성장해 왔다. 이번 포스트에서는 adversarial example 연구의 흐름을 이해하기 위해 해당 분야의 대표 논문들을 시간순으로 살펴본다.
Explaining and Harnessing Adversarial Examples (2014) — 20.6k citations
Adversarial example 연구를 대중화한 대표 논문으로, 딥러닝 모델의 선형성이 adversarial example의 원인이라고 주장하였다. 또한
FGSM(Fast Gradient Sign Method)과 Adversarial Training의 초기 형태를 제안하였다.Towards Evaluating the Robustness of Neural Networks (2017) — 13.5k citations
강력한 공격 기법인
C&W Attack을 제안하고 당시 널리 사용되던 Defensive Distillation을 무력화하였다. 이후 수년간 adversarial defense를 평가하는 대표적인 공격 방법으로 사용되었다.Towards Deep Learning Models Resistant to Adversarial Attacks (2017) — 19.6k citations
Adversarial robustness를 Robust Optimization 문제로 해석하고
PGD Adversarial Training을 제안하였다. 현재까지도 가장 대표적인 adversarial defense 기법 중 하나로 평가받고 있다.Adversarial Patch (2018) — 1.8k citations
이미지의 일부에 작은 패치를 부착하는 것만으로 모델을 속일 수 있음을 보였다. Adversarial example 연구를 디지털 환경에서
현실 세계의 물리적 공격으로 확장한 대표 논문이다.Certified Robustness to Adversarial Examples with Differential Privacy (2018) — 1.4k citations
Differential Privacy를 활용하여 특정 범위의 입력 변화에 대해 예측이 변하지 않음을 수학적으로 보장하고자 하였다.
Certified Robustness 연구분야의 초기 대표 논문 중 하나이다.Constructing Unrestricted Adversarial Examples with Generative Models (2018) — 0.4k citations
GAN을 이용하여 사람이 보기에도 자연스러운 adversarial example을 생성하였다. 이를 통해 adversarial attack이 반드시 작은 노이즈일 필요는 없음을 보여주었다.Obfuscated Gradients Give a False Sense of Security (2018) — 4.4k citations
당시 제안된 많은 방어 기법들이 실제 강건성을 제공하는 것이 아니라
gradient를 숨기고 있을 뿐임을 지적하였다. 이후 adversarial defense를 평가할 때 반드시 인용되는 대표 논문이 되었다.Adversarial Examples Are Not Bugs, They Are Features (2019) — 2.7k citations
Adversarial example이 단순한 모델의 버그가 아니라
모델이 학습한 non-robust feature의 결과라고 주장하였다. 인간과 모델이 서로 다른 특징을 활용한다는 관점을 제시하며 adversarial example의 원인을 새롭게 해석하였다.
1. Explaining and Harnessing Adversarial Examples (2014) — 20.6k citations
입력에 작은 변화를 가했음에도 출력이 크게 변하는 현상은 기존에 모델의 비선형성(non-linearity)이나 과적합(overfitting)에 의해 발생하는 것으로 설명되곤 하였다. 그러나 본 논문은 이러한 현상이 오히려 딥러닝 모델의 선형성(linearity) 에서 비롯된다고 주장한다. 저자들은 고차원 공간에서는 매우 작은 perturbation이라도 각 차원에서 누적되어 큰 변화를 일으킬 수 있으며, 이로 인해 adversarial example이 발생한다고 설명한다.
또한 adversarial perturbation은 특정 모델에만 국한되지 않고 여러 모델 사이에서 공유되는 transferability 특성을 가진다. 즉, 하나의 모델을 공격하기 위해 생성한 adversarial example이 다른 모델에 대해서도 높은 확률로 공격에 성공할 수 있음을 보였다. 이러한 특성은 공격자가 대상 모델의 구조나 파라미터를 알지 못하는 black-box 환경에서도 adversarial attack이 가능함을 보인다.
논문의 주요 기여(contributions)는 다음과 같이 정리할 수 있다:
- 딥러닝 모델의 비선형성(non-linearity)이 아니라, 고차원 공간에서의 선형성(linearity) 이 adversarial example의 주요 원인임을 주장.
- 기존의 L-BFGS 기반 공격보다 빠르고 효율적인 Fast Gradient Sign Method (FGSM) 를 제안.
- 학습 과정에서 adversarial example을 함께 사용하여 모델의 강건성(robustness)을 향상시키는 Adversarial Training 소개.
1.1. The Linear Explaination of Adversarial Examples
논문에서는 adversarial example이 딥러닝 모델의 비선형성 때문이 아니라, 오히려 고차원 공간에서의 선형성(linearity) 때문에 발생한다고 주장한다. 이를 설명하기 위해 저자들은 선형 모델을 가정하고 다음과 같은 식을 고려한다. \[\mathbf{w}^T\tilde{\mathbf{x}} = \mathbf{w}^T\mathbf{x} + \mathbf{w}^T\boldsymbol{\eta}\]
여기서 $\boldsymbol{\eta}$는 입력에 추가되는 작은 perturbation이다. 비록 각 원소의 크기는 매우 작더라도, 고차원 공간에서는 이러한 변화가 여러 차원에 걸쳐 누적된다. 예를 들어 입력 차원이 $n$이고 perturbation의 각 원소 크기가 최대 $\epsilon$이라고 하자. 또한 가중치의 평균 절댓값을 $m$이라고 정의하자. 이 경우 perturbation이 출력에 미치는 영향은 다음과 같이 근사할 수 있다. \(\mathbf{w}^T\boldsymbol{\eta} \approx \epsilon mn\)
즉, 개별 차원에서는 거의 눈에 띄지 않는 작은 변화라도 고차원 공간에서는 누적되어 모델의 출력을 크게 바꿀 수 있다. 저자들은 이것이 adversarial example이 발생하는 주요 원인이라고 설명한다.
그리고 이러한 출력 변화를 최대화하기 위해서는 perturbation을 가중치와 같은 방향으로 설정하면 된다. \[\boldsymbol{\eta} = \epsilon \cdot \text{sign}(\mathbf{w})\]
이러한 아이디어를 실제 딥러닝 모델에 적용한 공격 기법이 FGSM이다. FGSM은 가중치 벡터 $\mathbf{w}$ 의 부호를 사용하는 대신, 입력에 대한 손실 함수의 gradient 부호를 perturbation 방향으로 사용한다. \[\boldsymbol{\eta} = \epsilon \cdot \operatorname{sign} \left( \nabla_{\mathbf{x}} J(\boldsymbol{\theta},\mathbf{x},y) \right)\]
즉, 입력을 손실 함수가 가장 빠르게 증가하는 방향으로 이동시켜 모델이 오분류하도록 만든다. 그렇다면 출력 변화를 최대화하려면 단순히 가중치의 부호를 사용하면 될 것 같은데, 왜 FGSM은 weight의 sign 대신 gradient의 sign을 사용하는 것일까?

이를 이해하기 위해 가장 단순한 선형 분류기인 logistic regression을 살펴보자. Logistic regression 모델은 다음과 같이 정의된다. \[P(y=1)=\sigma(\mathbf{w}^{T}\mathbf{x}+b)\]
여기서 $\sigma(x)$ 는 시그모이드 함수이다. 또한 라벨을 $y\in{-1,+1}$로 표현하면 logistic regression의 기대 손실 함수는 다음과 같이 나타낼 수 있다. \[\mathbb{E}_{\mathbb{x},y \sim p_{\text{data}} } \zeta(-y(\mathbb{w}^T \mathbb{x} + b))\]
여기서 $\zeta(z) = \log (1+\exp(z))$ 는 softplus 함수이다.
위 식이 어떻게 유도되는지 살펴보자. 먼저 $y\in{-1,+1}$일 때 조건부 확률은 다음과 같이 표현할 수 있다. \[P(y|x) = \sigma(y(\mathbb{w}^T \mathbb{x} + b))\]
이는 시그모이드 함수가 $\sigma(x) + \sigma(-x) = 1$ 를 만족하기 때문이다. 따라서 negative log-likelihood loss는 아래와 같이 정의된다. \[\mathcal{L}(\mathbf{w},\mathbf{x},y) = -\log P(y|\mathbf{x}) = -\log \sigma\!\left( y(\mathbf{w}^{T}\mathbf{x}+b) \right)\]
그리고 Sigmoid 함수의 정의를 이용하면 위 식은 아래와 같이 정리된다. \[\mathcal{L}(\mathbf{w},\mathbf{x},y) = \log\!\left( 1+e^{-y(\mathbf{w}^{T}\mathbf{x}+b)} \right) = \zeta\!\left( -y(\mathbf{w}^{T}\mathbf{x}+b) \right)\]
이제 입력 $\mathbf{x}$에 대한 gradient를 계산해 보자. 로그 함수의 미분 공식 $[\ln f(x)]’ = \frac{f’(x)}{f(x)}$ 을 이용하면 다음을 얻을 수 있다. \[\nabla_{\mathbf{x}} \mathcal{L}(\mathbf{w},\mathbf{x},y) = \frac{ e^{-y(\mathbf{w}^{T}\mathbf{x}+b)} }{ 1+e^{-y(\mathbf{w}^{T}\mathbf{x}+b)} } (-y\mathbf{w})\]
이 식에 $\operatorname{sign}$을 취하면 아래와 같다. \[\begin{aligned} \operatorname{sign} \!\left( \nabla_{\mathbf{x}}\mathcal{L} \right) &= \operatorname{sign} \!\left( \frac{ e^{-y(\mathbf{w}^{T}\mathbf{x}+b)} }{ 1+e^{-y(\mathbf{w}^{T}\mathbf{x}+b)} } (-y\mathbf{w}) \right) \\ &= \operatorname{sign}(-y\mathbf{w}) \\ &= -y\,\operatorname{sign}(\mathbf{w}) \end{aligned}\]
이는 지수 함수의 출력과 분모가 항상 양수이므로 gradient의 부호가 $-y\mathbf{w}$에 의해서만 결정되기 때문이다.
결과적으로 logistic regression에서는 gradient의 부호를 구하는 것이 가중치의 부호를 구하는 것과 본질적으로 동일하다는 것을 보였다. 즉, 클래스 라벨 $y$에 따라 전체 방향만 반전될 뿐, FGSM이 사용하는 gradient의 sign은 weight의 sign과 같은 방향 정보를 담게된다.
1.2. Adversarial Training of Linear Models Versus Weight Decay
그렇다면 adversarial training은 어떻게 이루어질까? 가장 간단한 방법은 원본 입력 $\mathbf{x}$ 대신 adversarial perturbation이 추가된 입력 $\tilde{\mathbf{x}}=\mathbf{x}+\boldsymbol{\eta}$ 를 사용하여 학습하는 것이다. 그러면 loss 함수는 다음과 같이 정의된다. \[\mathcal{L}(\mathbf{w},\tilde{\mathbf{x}},y) = \zeta\!\left( -y(\mathbf{w}^{T}\tilde{\mathbf{x}}+b) \right)\]
앞서 logistic regression의 경우 FGSM perturbation이 $\boldsymbol{\eta} = -\epsilon y\,\operatorname{sign}(\mathbf{w})$ 로 표현됨을 보였다. 또한 $|\mathbf{w}|_1=\mathbf{w}^{T}\operatorname{sign}(\mathbf{w})$ 이므로 다음 관계를 얻을 수 있다. \[\begin{aligned} y(\mathbf{w}^{T}\tilde{\mathbf{x}}+b) &= y\!\left( \mathbf{w}^{T} (\mathbf{x}-\epsilon y\,\operatorname{sign}(\mathbf{w})) +b \right) \\ &= y(\mathbf{w}^{T}\mathbf{x}+b) -\epsilon \mathbf{w}^{T} \operatorname{sign}(\mathbf{w}) \\ &= y(\mathbf{w}^{T}\mathbf{x}+b) -\epsilon\|\mathbf{w}\|_1 . \end{aligned}\]
따라서 adversarial example에 대한 loss는 아래와 같이 쓸 수 있다. \[\mathcal{L}(\mathbf{w},\tilde{\mathbf{x}},y) = \zeta\!\left( \epsilon\|\mathbf{w}\|_1 -y(\mathbf{w}^{T}\mathbf{x}+b) \right).\]
이 식은 $L^1$ regularization과 매우 유사한 형태를 가진다. 실제로 $\epsilon|\mathbf{w}|_1$ 항이 추가적인 penalty 역할을 수행하기 때문이다. 하지만 중요한 차이점이 존재한다. $L^1$ regularization에서는 penalty가 loss에 직접 더해지는 반면, adversarial training에서는 penalty가 activation 내부에서 차감된다.
Weight decay의 경우 모델이 최적의 해를 찾더라도 regularization 항은 항상 loss에 남아 있다. 반면 adversarial training에서는 모델이 충분히 좋은 예측을 하게 되면 softplus 함수의 입력이 큰 음수가 되어 loss 값이 0에 가까워진다. 따라서 학습이 진행됨에 따라 penalty의 효과가 자연스럽게 감소할 수 있다.
이러한 차이는 multiclass 분류 문제에서 더욱 직관적으로 이해할 수 있다. 예를 들어 고양이 이미지를 분류하는 상황을 생각해 보자. 현재 모델이 고양이를 주로 개와 혼동한다고 하자. Adversarial training은 이러한 실제 취약성을 반영하여 고양이와 개를 구분하는 방향에 집중적으로 penalty를 부여한다. 즉, 모델이 실제로 실수하기 쉬운 방향에 대해서만 robust하도록 학습된다.
반면 weight decay는 어떤 방향이 실제로 취약한지 알지 못한다. 모든 가중치의 크기를 일괄적으로 감소시키기 때문에 결과적으로는 고양이와 개를 구분하는 방향뿐 아니라 고양이와 자동차, 고양이와 비행기처럼 현재 분류에 큰 영향을 주지 않는 방향까지 함께 억제하게 된다.
물론 두 방법을 완전히 동일한 것으로 볼 수는 없다. 하지만 adversarial 관점에서 해석하면 weight decay는 실제 취약한 방향만 고려하는 것이 아니라 모든 방향이 잠재적으로 adversarial direction이라고 가정하는 것으로 볼 수 있다. 다시 말해 weight decay는 adversarial perturbation의 영향을 과대평가하는 보다 보수적인 regularization이라고 해석할 수 있다.
그 결과 weight decay의 계수를 지나치게 크게 설정하면 실제로 중요하지 않은 방향까지 함께 억제하게 되어 underfitting이 발생할 수 있다. 반면 adversarial training은 실제로 취약한 방향에 대해서만 penalty를 부여하며, 모델의 예측이 충분히 좋아지면 그 효과가 자연스럽게 감소한다. 따라서 adversarial training은 상대적으로 더 큰 $\epsilon$ 값을 사용하더라도 학습이 가능하다.
1.3. Why Do Adversarial Examples Generalize?
논문에서는 FGSM 방향으로 입력을 이동시키면서 $\epsilon$ 값을 점차 증가시켰을 때 모델의 출력이 어떻게 변하는지 분석한다.
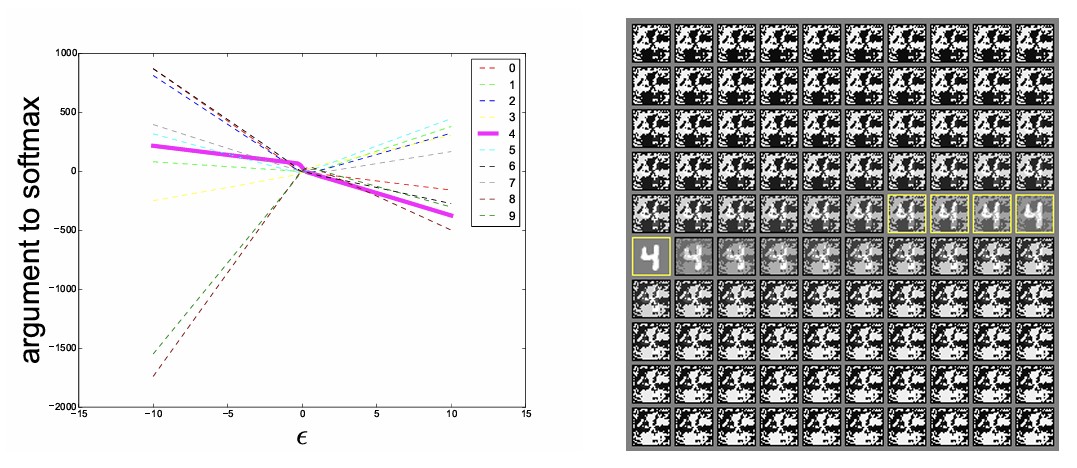
실험 결과, $\epsilon$ 값이 증가함에 따라 각 클래스의 softmax score는 거의 선형적으로 증가하거나 감소하는 모습을 보였다. 이는 FGSM이 찾은 방향을 따라 이동할 때 모델이 국소적으로 선형에 가까운 동작을 한다는 것을 의미한다. 다시 말해, adversarial example은 매우 복잡한 비선형 구조에 의해 발생하는 것이 아니라 모델의 선형적인 특성에 의해 설명될 수 있다는 것이다.
이러한 결과는 adversarial example이 왜 서로 다른 모델 사이의 전이성(transferability)을 설명하는데 중요한 단서를 제공한다.
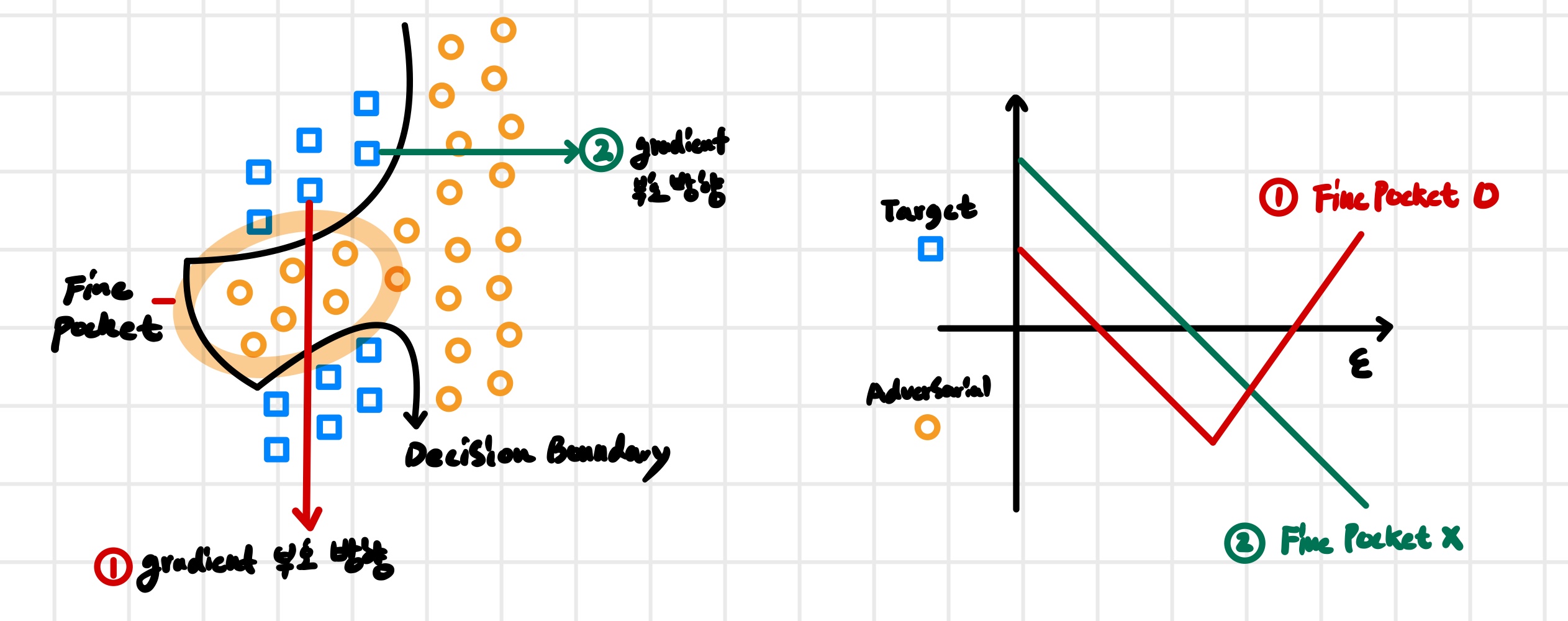
만약 adversarial example이 고차원 공간에서의 복잡한 비선형성에 의해 생성된 fine pocket 때문이라면, $\epsilon$을 증가시키면서 이동할 때 공격 성공 영역과 실패 영역이 반복적으로 나타나야 한다. 즉, softmax score가 감소했다가 다시 증가하는 등 매우 불규칙한 변화를 보여야 한다.
반면 실제 실험에서는 이러한 현상이 관찰되지 않았다. FGSM 방향을 따라 이동할수록 softmax score는 비교적 일정한 기울기로 증가하거나 감소하였다. 이는 adversarial example이 매우 좁고 복잡한 pocket에 존재하는 것이 아니라, 비교적 넓은 영역에 걸쳐 분포하고 있음을 말한다.
따라서 adversarial example은 특정한 점에서만 발생하는 현상이 아니라 넓은 subspace에 걸쳐 존재한다고 볼 수 있다. 이러한 구조는 fine pocket과 같은 국소적인 구조보다 서로 다른 모델에 의해 일관되게 학습될 가능성이 높다. 특히 서로 다른 모델이 동일한 데이터 분포로부터 유사한 decision boundary를 학습한다면, adversarial region 역시 비슷한 형태로 형성될 수 있다. 그 결과 한 모델에서 생성한 adversarial example이 다른 모델에서도 동작하는 transferability가 발생한다고 해석할 수 있다.
1.4. Adversarial Training
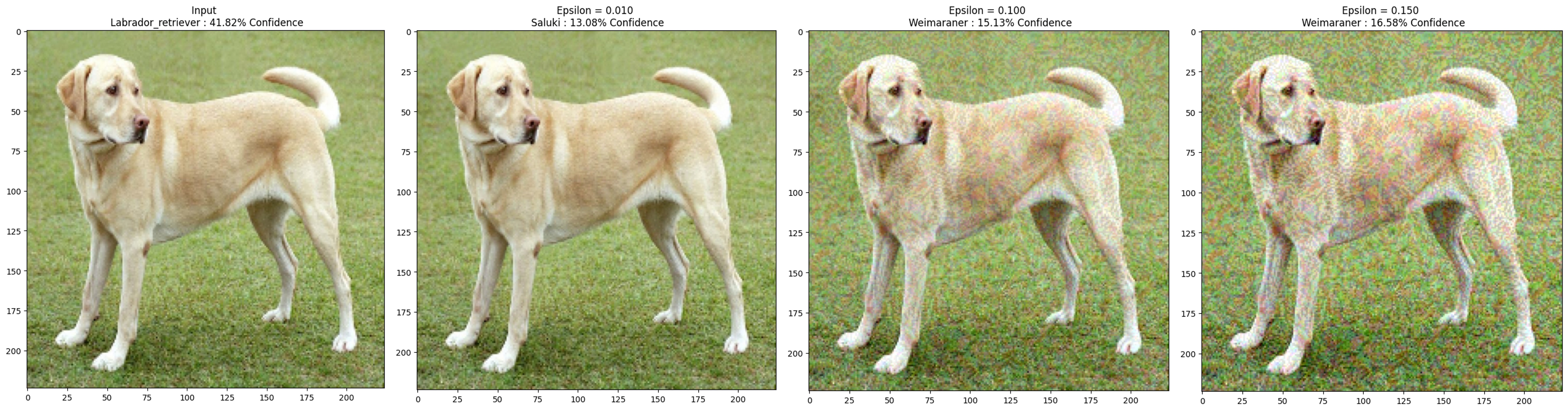
\[\tilde{J}(\mathbb{\theta}, \mathbb{x}, y) = \alpha J(\mathbb{\theta}, \mathbb{x}, y) + (1-\alpha)J(\mathbb{\theta}, \mathbb{x}+\epsilon \operatorname{sign}(\nabla_{\mathbb{x}}J(\mathbb{\theta}, \mathbb{x}, y)), y)\][Adversarial example using FGSM] 에서 FGSM 기법으로 adversarial example을 생성하는 코드를 실습할 수 있다.
2. Towards Evaluating the Robustness of Neural Networks (2015) — 13.5k citations
앞서 소개한 FGSM은 입력에 대한 gradient 정보를 이용하여 adversarial example을 생성한다. 따라서 모델이 gradient 정보를 숨기는 gradient masking 현상을 보이면 효과적인 adversarial example을 찾기 어려울 수 있다. 이러한 특성을 이용한 대표적인 방어 기법 중 하나가 Defensive Distillation이다.
본 논문에서는 이러한 방어 기법에도 효과적으로 동작하는 강력한 최적화 기반 공격 기법인 CW (Carlini & Wagner) Attack을 제안한다.
FGSM은 gradient 방향으로 $\epsilon$ 만큼 한 번 이동하여 adversarial example을 생성한다. 이 방법은 계산량이 매우 적다는 장점이 있지만, $\epsilon$ 값을 사전에 설정해야 한다는 한계가 있다. $\epsilon$이 너무 작으면 decision boundary를 넘지 못해 공격에 실패할 수 있고, 반대로 너무 크면 이미지가 과도하게 변형될 수 있다. 또한 한 번의 gradient step만 사용하므로 복잡하고 비선형적인 decision boundary를 효과적으로 탐색하지 못할 수 있다.
반면 CW Attack은 adversarial example 생성 문제를 최적화 문제로 정식화한다. 공격 성공 여부와 perturbation의 크기를 동시에 고려하여 반복적으로 최적화를 수행하기 때문에, 일반적으로 더 작은 distortion으로 공격에 성공하는 adversarial example을 찾을 수 있다. 또한 softmax 기반 loss 대신 logits를 직접 이용하는 목적 함수를 사용하여 gradient masking에 상대적으로 강인한 특성을 보인다.
논문의 주요 기여(contributions)는 아래와 같다.
- Adversarial example 생성 문제를 최적화 문제로 정식화하는 방법을 제시.
- 공격 성공과 perturbation 크기를 동시에 고려하여 작은 distortion의 adversarial example을 효과적으로 탐색.
- 기존 방어 기법, 특히 Defensive Distillation이 실제로는 robust하지 않음을 보임.
- 이후 adversarial robustness 연구에서 강력한 $L_2$ 기반 공격의 대표적인 baseline으로 활용됨.
2.1. What is Defensive Distillation?
Defensive Distillation은 softmax 함수에 temperature (T)를 도입하여 모델을 학습하는 방어 기법이다. \[\operatorname{softmax}(x, T)_i = \frac{e^{x_i/T}} {\sum_j e^{x_j/T}}\]
학습 과정은 다음과 같다.
- Temperature를 ($T=100$)로 설정하여 teacher network A를 학습한다.
- 학습된 teacher network A를 이용하여 soft label을 생성한다.
- 동일한 temperature ($T=100$)를 사용하여 soft label로 student network B를 학습한다.
- 테스트 시에는 temperature를 ($T=1$)로 설정하여 추론을 수행한다.
일반적인 distillation은 teacher network가 학습한 클래스 간 관계(class similarity)를 student network에 효과적으로 전달하기 위해 사용된다. 이는 teacher의 soft label이 단순한 정답 클래스뿐만 아니라, 다른 클래스들 간의 상대적인 확률 분포 정보를 함께 포함하기 때문이다. 이러한 정보를 통해 student network는 제한된 capacity를 가지더라도 teacher의 출력 분포를 모방함으로써 더 높은 성능을 달성할 수 있다.
반면 Defensive Distillation에서는 teacher network A와 student network B가 일반적으로 동일한 구조와 capacity를 사용한다. 따라서 모델 압축이라는 원래의 목적보다는 soft label을 이용하여 더 smooth한 decision boundary를 학습하고 adversarial attack에 대한 robustness를 높이는 것을 목표로 한다.
그러나 본 논문에서는 Defensive Distillation의 robustness가 실제로는 decision boundary의 변화 때문이라기보다 gradient masking에 의해 발생한 현상임을 보였다.
2.2. Why Defensive Distillation is Effective Against FGSM
Defensive Distillation은 gradient 정보를 이용하여 adversarial example을 생성하는 FGSM 공격에 대해 높은 방어 성능을 보인다. 그 이유는 FGSM이 입력에 대한 loss의 gradient를 이용하여 adversarial example을 생성하는 반면, Defensive Distillation은 이러한 gradient를 매우 작게 만드는 효과를 가지기 때문이다.
Cross-Entropy Loss와 Softmax를 함께 사용할 경우 softmax의 역전파 과정은 아래 그림과 같다.
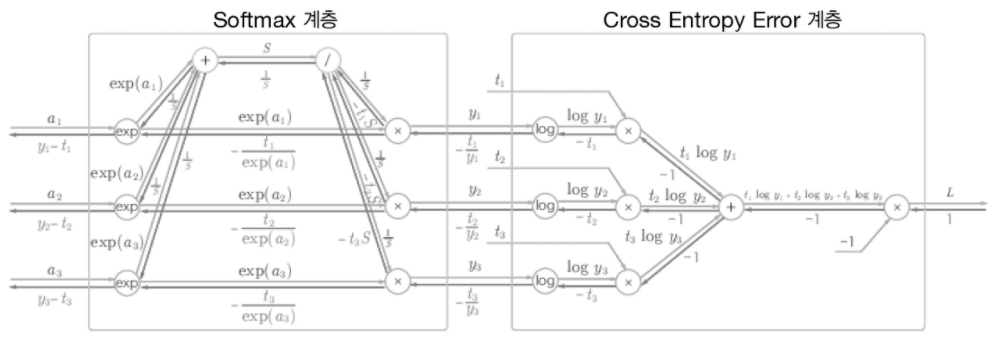
역전파되는 값은 $\frac{\partial L}{\partial z_i}=y_i - t_i$ 이고 여기서 $y_i$ 는 softmax 출력값이고, $t_i$는 정답 레이블이다.
Defensive Distillation에서는 큰 $T$ 값을 사용해 학습한 뒤 테스트 시에는 $T=1$을 사용하기 때문에 $y_i$ 값이 매우 sparse해진다. 즉, 정답 클래스의 확률은 1에 매우 가까워지고 나머지 클래스들의 확률은 0에 가까워진다.
이러한 경우 softmax에서 역전파되는 $y_i - t_i$ 값 또한 매우 작은 값을 가지게 되며, 결과적으로 계산되는 gradient 역시 매우 작아진다. 따라서 FGSM은 adversarial example을 생성하는 데 필요한 유의미한 gradient 정보를 얻지 못하게 된다.
이러한 현상은 Gradient Masking이라고 불리며, Defensive Distillation이 FGSM에 대해 강한 방어 성능을 보이는 주된 이유이다.
2.3. Ways to Attack Defensive Distillation
Defensive Distillation은 높은 temperature로 학습한 뒤, 추론 시에는 다시 $T=1$을 사용한다. 그 결과 softmax의 출력이 매우 sparse해지며, 대부분의 클래스 확률이 0 또는 1에 가까워진다. 따라서 softmax를 통해 계산되는 gradient 역시 매우 작아져 gradient 기반 공격이 어려워진다.
그렇다면 학습에 사용된 temperature $T$를 알고 있다면 FGSM 공격을 수행할 수 있지 않을까?
실제로 공격자는 gradient를 계산할 때 동일한 temperature를 사용하여 softmax의 포화(saturation)를 완화할 수 있다. 이렇게 하면 Defensive Distillation이 만들어낸 gradient masking 효과를 상당 부분 제거할 수 있으며, FGSM과 같은 gradient 기반 공격도 다시 동작하게 된다.
하지만 Carlini와 Wagner는 여기서 한 단계 더 나아간다. 애초에 softmax의 출력 확률을 이용하지 않고, softmax에 입력되는 logit을 직접 최적화하면 어떨까?
이 경우 포화된 softmax를 통과하여 역전파할 필요가 없으며, gradient masking 문제 자체를 우회할 수 있다. 실제로 CW attack은 softmax 출력 대신 logit 값을 직접 사용하는 목적 함수를 설계하여 Defensive Distillation을 효과적으로 무력화하였다.
그리고 이것이 CW attack의 핵심 아이디어이다.
2.4. Carlini & Wagner (C&W) Attack
모델의 표기는 다음과 같이 정의된다. 신경망의 logit 출력은 $Z(x)$, softmax 출력은 $F(x)$, 최종 예측 결과는 $C(x)$ 로 둔다.
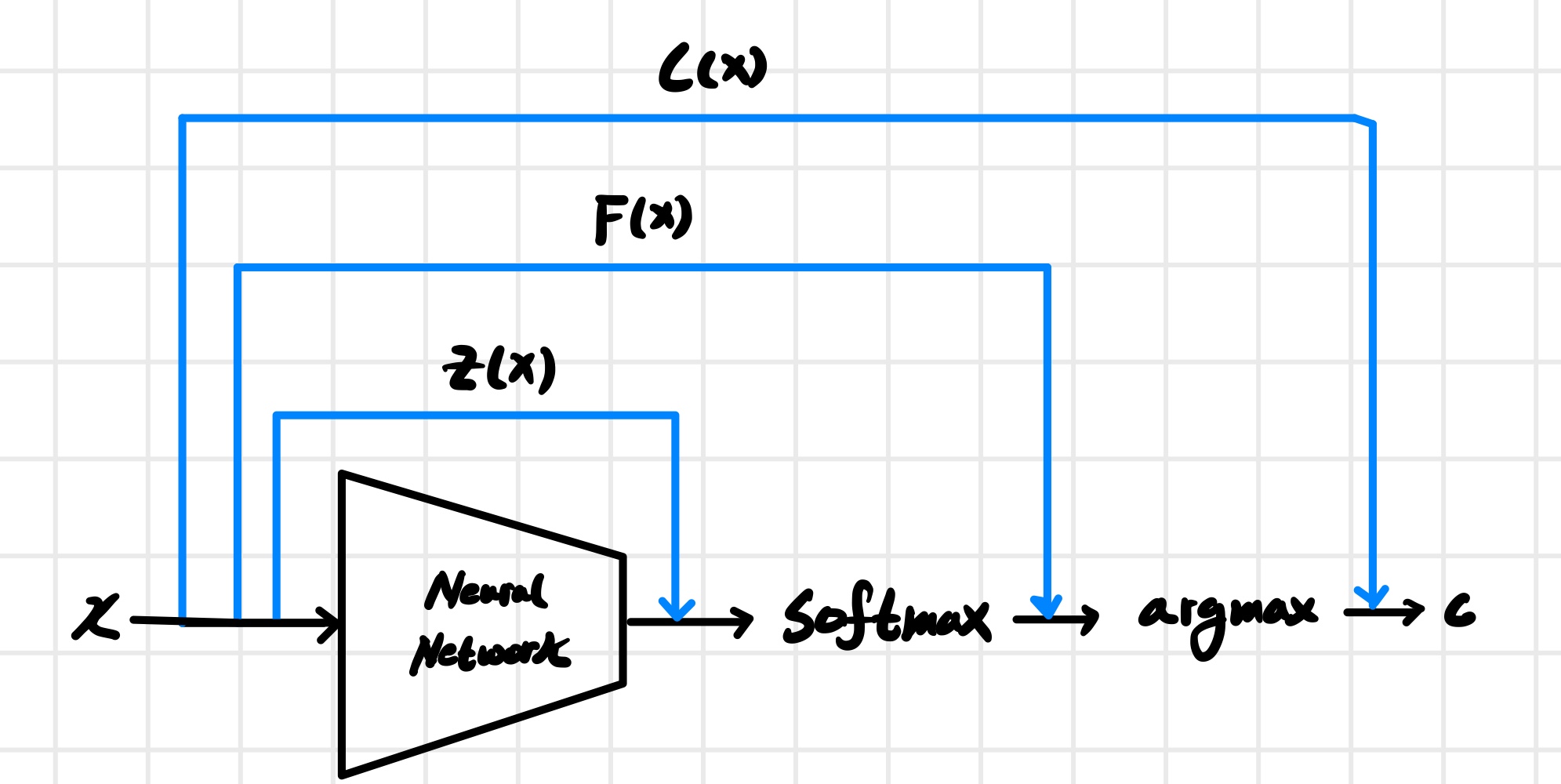
2.4.1. 원래 최적화 문제
우리가 원하는 목표는 다음과 같이 표현된다. \[\begin{aligned} \min_{\delta} \quad & D(x, x+\delta) \\ \text{s.t.} \quad & C(x+\delta)=t, \\ & x+\delta \in [0,1]^n \end{aligned}\]
하지만 $C(\cdot)=\arg\max$는 비연속 함수이기 때문에 gradient 기반 최적화가 어렵다.
2.4.2. logit 기반 제약으로 변환
이를 해결하기 위해 argmax 제약을 logit 기반 연속 함수로 바꾼다. \[f(x') = \max_{i \ne t} Z(x')_i - Z(x')_t\]
이때 $f(x’) \le 0$ 이면 target class $t$가 가장 큰 logit을 가지므로 공격이 성공한 것으로 본다. 따라서 최적화 문제는 아래과 같이 변환된다. \[\begin{aligned} \min_{\delta} \quad & D(x, x+\delta) \\ \text{s.t.} \quad & f(x+\delta) \le 0, \\ & x+\delta \in [0,1]^n \end{aligned}\]
2.4.3. Lagrangian relaxation (penalty form)
제약 조건을 penalty 형태로 바꾸면 아래과 같이 표현된다. \[\min_{\delta} \quad D(x, x+\delta) + c \cdot f(x+\delta)\]
여기서 $c$는 distortion과 constraint violation 사이의 trade-off를 조절하는 상수이다.
2.4.4. $L_p$-norm distance
거리 함수로 $L_p$-norm을 사용한다. 그 수식을 표현하면 아래와 같다. \[\min_{\delta} \quad \|\delta\|_p + c \cdot f(x+\delta)\]
2.4.5. Box constraint
입력 $x+\delta \in [0,1]^n$를 만족시키기 위해 change of variable을 사용한다. \[x' = \frac{1}{2}(\tanh(w) + 1)\]
따라서 perturbation은 아래와 같이 표현된다. \[\delta = x' - x = \frac{1}{2}(\tanh(w) + 1) - x\]
tanh는 항상 $[-1,1]$ 범위를 가지므로 $x’ \in [0,1]$이 자동으로 보장된다.
2.4.6. 최종 formulation
최종적으로 C&W attack은 아래와 같이 정리된다. \[\boxed{ \min_{w} \left\| \frac{1}{2}(\tanh(w)+1) - x \right\|_p + c \cdot f\!\left(\frac{1}{2}(\tanh(w)+1)\right) }\] \[f(x') = \max_{i \ne t} Z(x')_i - Z(x')_t\]
2.5. Code Implementation
정확한 구현은 아니지만 C&W attack은 아래과 같은 형태로 구현할 수 있다.
w = torch.zeros_like(x, requires_grad=True)
optimizer = torch.optim.Adam([w], lr=0.01)
for i in range(iter):
x_adv = 0.5 * (torch.tanh(w) + 1)
loss1 = torch.norm(x_adv - x, p=2)
loss2 = c * f(model(x_adv))
loss = loss1 + loss2
optimizer.zero_grad()
loss.backward()
optimizer.step()
파라미터 $w$를 최적화함으로써 입력 $x$에 대한 adversarial example을 생성할 수 있다.
3. Towards Deep Learning Models Resistant to Adversarial Attacks (2017) — 19.6k citations
FGSM은 gradient 방향으로 단 한 번만 이동하기 때문에, 주어진 perturbation budget 내에서 가장 강력한 adversarial example을 찾는다고 보장할 수 없다. 즉, 동일한 $\epsilon$-ball 내부에 더 큰 loss를 유발하는 adversarial example이 존재하더라도 이를 발견하지 못할 수 있다.
이러한 한계를 극복하기 위해 FGSM을 여러 번 반복 적용하는 BIM(Basic Iterative Method)이 제안되었다. Madry는 이와 유사하게 매 step마다 gradient ascent를 수행한 뒤 perturbation이 허용된 범위를 벗어나면 다시 $\epsilon$-ball 내부로 projection하는 PGD(Projected Gradient Descent) 공격을 제안한다. 이를 통해 주어진 perturbation 범위 내에서 더 큰 loss를 유발하는 adversarial example을 효과적으로 탐색할 수 있다.
하지만 이 논문의 핵심은 PGD 공격 자체에 있지 않다. 저자들은 PGD를 이용해 adversarial example을 생성하는 과정을 모델의 loss를 최대화하는 내부 최적화 문제로 해석하였다. 그리고 이를 바탕으로 adversarial training을 robust optimization 기반의 min-max 최적화 문제로 정식화하였다.
논문의 주요 기여는 다음과 같다.
- Adversarial training을 robust optimization 기반의 min-max 문제로 정식화.
- PGD를 inner maximization 문제를 근사적으로 해결하는 강력한 first-order 공격으로 활용.
- PGD가 매우 강력한 공격임을 실험적으로 보였으며, 이후 adversarial robustness 연구에서 사실상의 표준 $L_\infty$ 공격 baseline으로 사용.
3.1. Optimization View on Adversarial Robustness
저자들은 adversarial robustness를 다음과 같은 min-max 최적화 문제로 정식화하였다. \[\min_\theta \mathbb{E}_{(x,y)\sim D} \left[ \max_{\delta \in S} L(\theta, x+\delta, y) \right]\]
여기서 내부 최적화(inner maximization)는 주어진 perturbation 집합 $S$ 내에서 모델의 loss를 최대화하는 adversarial example을 찾는 과정이며, 외부 최적화(outer minimization)는 이러한 adversarial example에 대해서도 올바르게 분류하도록 모델을 학습하는 과정이다.
즉, 저자들은 공격과 방어를 하나의 통합된 saddle-point 문제로 해석하였으며, 이를 통해 adversarial robustness를 정량적으로 평가할 수 있는 기반을 마련하였다. 따라서 주어진 perturbation 범위 내에서의 worst-case loss가 작을수록 모델이 더 robust하다고 해석할 수 있다.
3.1. Projected Gradient Descent
PGD 공격은 아래와 같이 정의된다. \[x^{t+1} = \Pi_{x+S} \left( x^t + \alpha \,\mathrm{sgn}\!\left(\nabla_x L(\theta, x^t, y)\right) \right)\]
이 과정을 반복하면 내부 최적화 문제 $\max_{\delta \in S} L(\theta, x+\delta, y)$ 를 근사적으로 해결할 수 있다.
그렇다면 PGD를 수행하면 실제로 최대 loss를 갖는 adversarial example을 찾을 수 있을까? 일반적으로 신경망은 비선형 함수이기 때문에 내부 최적화 문제를 정확하게 푸는 것은 매우 어렵다. 따라서 PGD가 항상 전역 최적해(global optimum)를 찾는다고 보장할 수는 없다.
그러나 논문에서는 randomly re-started PGD를 사용하여 이 문제를 실험적으로 분석하였다. 구체적으로는 허용된 perturbation 영역 내에서 여러 개의 랜덤한 초기점을 선택한 뒤 각각에 대해 PGD를 수행하였다. 그 결과 서로 다른 초기점에서 시작하더라도 최종적으로 도달한 adversarial example들의 loss 값이 매우 비슷하게 나타났다.
이는 다양한 초기점에서 시작한 PGD가 일관되게 높은 loss를 갖는 해를 찾는다는 것을 의미한다. 즉, 실제 신경망의 loss landscape에서는 PGD가 내부 최적화 문제에 대한 매우 강력한 근사 해법으로 동작하며, random restart를 충분히 수행하면 최대 loss에 가까운 adversarial example을 찾을 가능성이 높다는 것을 시사한다.
아래 그림은 여러 번의 random restart PGD를 수행했을 때 최종 loss 값들이 비슷한 수준으로 수렴하는 모습을 보여준다.
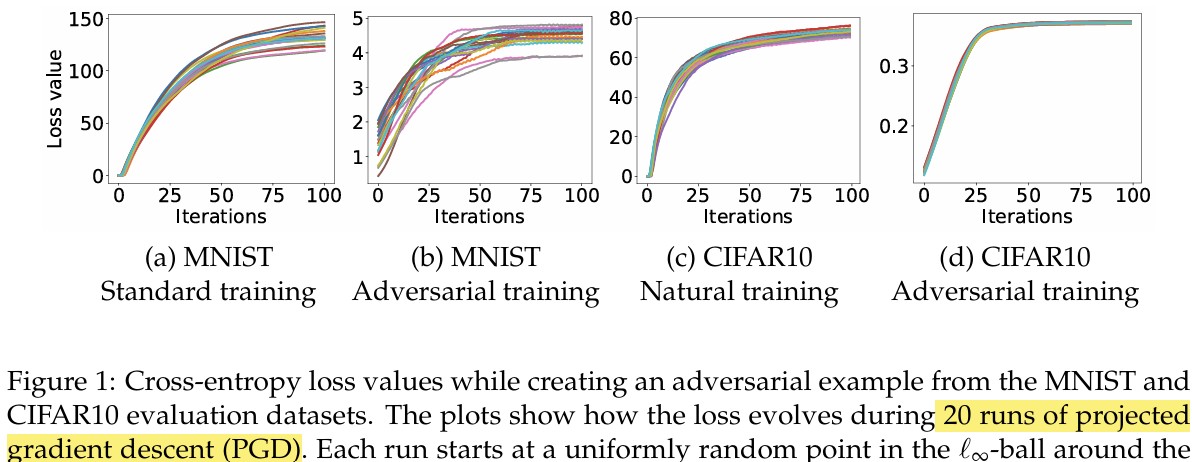
또한 adversarial training을 수행한 이후에는 이러한 최대 loss 값 자체가 감소하는 경향을 보인다. 이는 모델이 perturbation에 대해 덜 민감하도록 학습되었음을 의미한다. 다시 말해 허용된 perturbation 범위 내에서 공격자가 loss를 크게 증가시키기 어려워지며, 결과적으로 모델의 adversarial robustness가 향상된다.
이러한 관찰은 adversarial training의 내부 최적화 문제를 PGD로 근사하는 것이 합리적임을 뒷받침한다. 비록 PGD가 전역 최적해를 찾는다고 보장할 수는 없지만, 다양한 초기점에서 시작한 PGD가 일관되게 비슷한 수준의 높은 loss에 도달한다는 사실은 더 좋은 adversarial example을 놓쳤을 가능성이 크지 않음을 시사한다. 따라서 저자들은 PGD를 ‘first-order adversary에 대한 보편적인(universal) 공격 방법으로 간주하고, 이를 이용하여 모델의 adversarial robustness를 평가하고 학습하였다.
3.2. Adversarial Training
PGD를 이용하여 inner maximization 문제를 근사적으로 해결한 뒤, 해당 perturbation에 대해 모델 파라미터 $\theta$를 최적화하는 것이 adversarial training의 목표이다. \[\min_\theta \max_{\delta \in S} L(\theta, x+\delta, y)\]
이를 최적화하기 위해서는 다음 gradient를 계산해야 한다. \[\nabla_\theta \max_{\delta\in S} L(\theta,x+\delta,y)\]
먼저 inner maximization의 해를 \[\delta^*(\theta) = \arg\max_{\delta\in S} L(\theta,x+\delta,y)\]
라고 정의하면 목적함수는 다음과 같이 쓸 수 있다. \[\min_\theta L(\theta,x+\delta^*(\theta),y)\]
따라서 필요한 gradient는 아래와 같다. \[\nabla_\theta L(\theta,x+\delta^*(\theta),y)\]
여기서 $\delta *$ 는 $\theta$ 에 의존하므로 chain rule을 적용하면 $\partial\delta * / \partial\theta$ 항이 등장한다. 그러나 $\delta *$ 는 또 다른 최적화 문제의 해이기 때문에 $\partial\delta * / \partial\theta$ 를 직접 계산하는 것은 매우 어렵다.
이때 Danskin’s theorem을 사용할 수 있다. Danskin’s theorem에 따르면 일정한 조건 하에서 아래가 성립한다 \[\nabla_\theta \max_{\delta\in S} L(\theta,x+\delta,y) = \nabla_\theta L(\theta,x+\delta^*(\theta),y)\]
즉, $\partial\delta* / \partial\theta$ 를 계산하지 않고도 gradient를 구할 수 있으며, $\delta^*$를 상수처럼 취급한 채 미분해도 올바른 gradient를 얻을 수 있다.
따라서 adversarial training은 다음과 같이 수행된다.
- PGD를 이용하여 inner maximization 문제를 근사적으로 해결한다.
- 얻어진 $\delta^*$를 고정한 상태에서
- $\nabla_\theta L(\theta,x+\delta^*,y)$를 계산하여 SGD를 수행한다.
엄밀하게는 Danskin’s theorem은 $f(\theta,\delta)$가 $\theta$에 대해 미분 가능하고, inner maximization의 global maximizer $\delta^* \in \arg\max_{\delta \in S} f(\theta,\delta)$가 존재함을 가정한다.
그러나 실제 adversarial training에서는 이 가정을 그대로 만족시키기 어렵다.
inner maximization은 일반적으로 non-convex 문제이며, PGD를 통해 근사적으로 해결된다.
이때 얻어지는 $\delta^*$는 global maximizer가 아니라 PGD에서의 초기화와 반복적인 perturbation 과정에 의해 결정되는 근사해이다.
또한 신경망은 ReLU와 같이 비미분 가능한 지점을 포함하지만, 이러한 지점들은 거의 모든 곳에서 무시할 수 있는 집합(measure zero)이므로 실제 최적화에서는 subgradient 관점으로 다뤄진다.
따라서 adversarial training은 Danskin’s theorem의 엄밀한 조건을 그대로 만족하지는 않지만, PGD가 충분히 강한 adversarial example을 생성한다는 경험적 근거를 바탕으로 해당 형태의 gradient update를 사용한다.
3.3. Code Implementation
정확한 구현은 아니지만 PGD adversarial training은 아래와 같은 형태로 구현할 수 있다.
# inner maximization
for _ in range(num_steps):
loss_adv = criterion(model(x_adv), y)
grad = torch.autograd.grad(loss_adv, x_adv)[0]
x_adv = x_adv + alpha * grad.sign()
# projection step
x_adv = torch.clamp(x_adv, x - eps, x + eps)
x_adv = torch.clamp(x_adv, 0.0, 1.0).detach()
# outer minimization
logits = model(x_adv)
loss = criterion(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
4. Certified Robustness to Adversarial Examples with Differential Privacy (2018) - 1.4k citations
기존 adversarial training 기법들은 알려진 공격 기법에 대해 강건한 모델을 만드는 것을 목표로 하였다. 이러한 방법들은 경험적으로 강한 성능을 보일 수 있지만, 더 강력한 공격이 등장하면 취약해질 수 있다. 즉, 대부분의 adversarial training은 best-effort robustness를 제공한다.
반면 이 논문은 특정 perturbation 범위 내에서 모델의 예측이 변하지 않음을 수학적으로 보장하는 certified robustness를 목표로 한다. 다시 말해, 주어진 입력 주변의 특정 영역 안에는 adversarial example이 존재하지 않음을 증명할 수 있는 모델을 구축한다.
저자들은 이러한 보장을 얻기 위해 Differential Privacy(DP)의 안정성(stability) 이론을 활용한다. 원래 DP는 데이터베이스의 개별 레코드가 결과에 미치는 영향을 제한하여 개인정보를 보호하기 위해 제안된 개념이다. 본 논문은 DP의 민감도 분석을 입력 공간에 적용하여 robustness certificate를 도출한다. 구현 측면에서는 모델의 중간 계층에 노이즈를 주입하는 방식으로 이루어지며, 이는 이후의 randomized smoothing 계열 방법과도 밀접한 관련이 있다.
논문의 주요 기여는 아래과 같다.
- Differential Privacy를 활용하여 provable robustness를 제공하는 방어 기법 PixelDP을 제안
- 대규모 신경망에도 적용 가능한 scalable한 certified defense framework 제시
- 특정 $L_2$ 및 $L_1$ perturbation 범위에 대해 robustness certificate를 제공
4.1. What is Differential Privacy
Differential Privacy(DP)는 한 사람의 데이터가 있든 없든 분석 결과가 거의 같게 나오도록 만드는 프라이버시 보호 기법이다.
예를 들어 어떤 기관이 데이터 분석 결과를 공개한다고 하자. 공격자는 이 결과를 이용해 특정 사람이 데이터베이스에 포함되어 있는지 추론하려고 할 수 있다. DP의 목표는 이러한 추론을 어렵게 만드는 것이다. 이를 위해 알고리즘의 결과에 적절한 무작위성을 추가하여, 한 사람의 데이터를 추가하거나 제거하더라도 결과가 크게 달라지지 않도록 만든다.
수학적으로, 알고리즘 $A$가 데이터베이스 $d$를 입력받아 출력 공간 $O$의 값을 반환한다고 하자. 이때 $A$가 $(\epsilon,\delta)$-DP가 만족한다는 것은 distance metric $\rho$에 대해 $\rho(d,d’) \le 1$인 임의의 두 데이터베이스 $d,d’$와 모든 $S \subseteq O$에 대하여 아래가 성립함을 의미한다. \[P(A(d)\in S) \le e^\epsilon P(A(d')\in S) + \delta.\]
여기서 $\delta \in [0,1]$이다.
일반적으로 $\rho$로는 Hamming distance를 사용하며, 이는 두 데이터베이스가 최대 한 개의 레코드 (row)에서만 차이가 난다는 의미이다. 따라서 DP를 만족하는 알고리즘은 특정 개인의 데이터를 추가하거나 제거하더라도 출력 분포가 크게 변하지 않는다. 즉, $A$의 결과를 관찰하더라도 특정 개인의 데이터가 사용되었는지 여부를 알아내기 어렵게 된다.
Differential Privacy의 기본 개념과 실제로 어떻게 프라이버시를 보호하는지에 대해서는 이 글에서 자세히 다루었다.
Certified Robustness에서는 데이터베이스를 이미지로, 레코드를 픽셀로 해석하여 DP의 개념을 적용한다. 따라서 몇 개의 픽셀이 변경되더라도 모델의 출력 분포가 크게 변하지 않도록 만들며, 이를 통해 입력 변화에 대한 강건성을 보장한다.
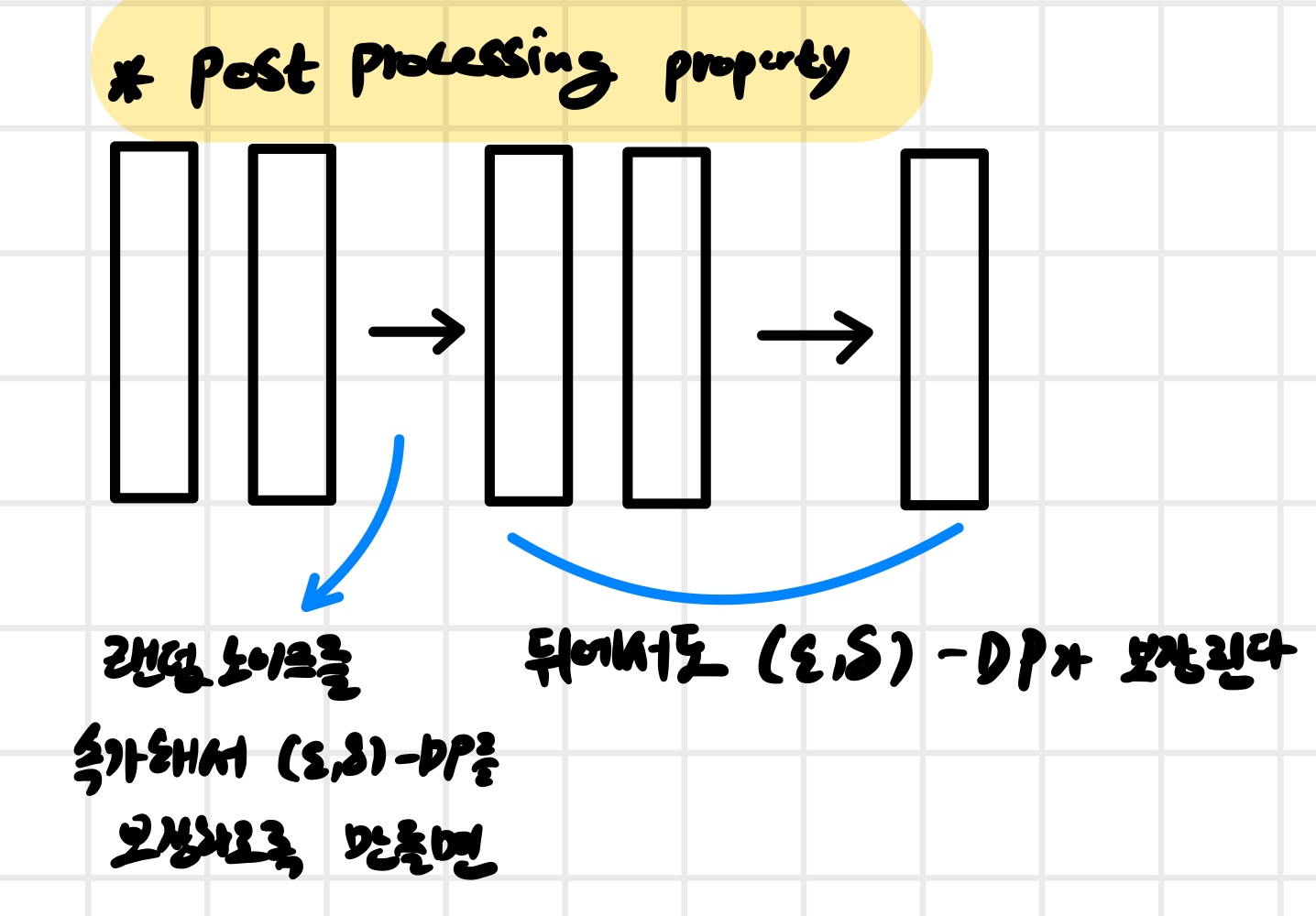
DP를 만족하는 알고리즘은 잘 알려진 Post-Processing Property를 만족하며, 더 나아가 이 논문에서 제시하는 expected output stability bound 역시 만족한다.
4.2. Post Processing Property
$(\epsilon,\delta)$-DP 알고리즘의 출력에 적용되는 어떠한 연산도 $(\epsilon,\delta)$-DP 보장을 훼손하지 않는다.
4.3. Expected Output Stability Bound
출력값이 $[0,b]$ 범위에 속하는 확률적 함수 $A$가 $(\epsilon,\delta)$-DP를 만족한다고 가정하자. 그러면 $A$의 출력 기댓값은 다음과 같은 bound를 만족한다. \[\forall \alpha \in B_p(1), \quad \mathbb{E}[A(x)] \le e^{\epsilon}\mathbb{E}[A(x+\alpha)] + b\delta.\]
이 결과는 DP의 정의와 Tail Sum Formula를 이용하여 증명할 수 있다. 먼저 출력 $A(x)$가 $[0,b]$ 구간에 bounded 되어 있다고 가정하자. 그러면 Tail Sum Formula에 의해 기대값은 다음과 같이 표현된다. \[\mathbb{E}[A(x)] = \int_0^b P(A(x) > t)\,dt.\]
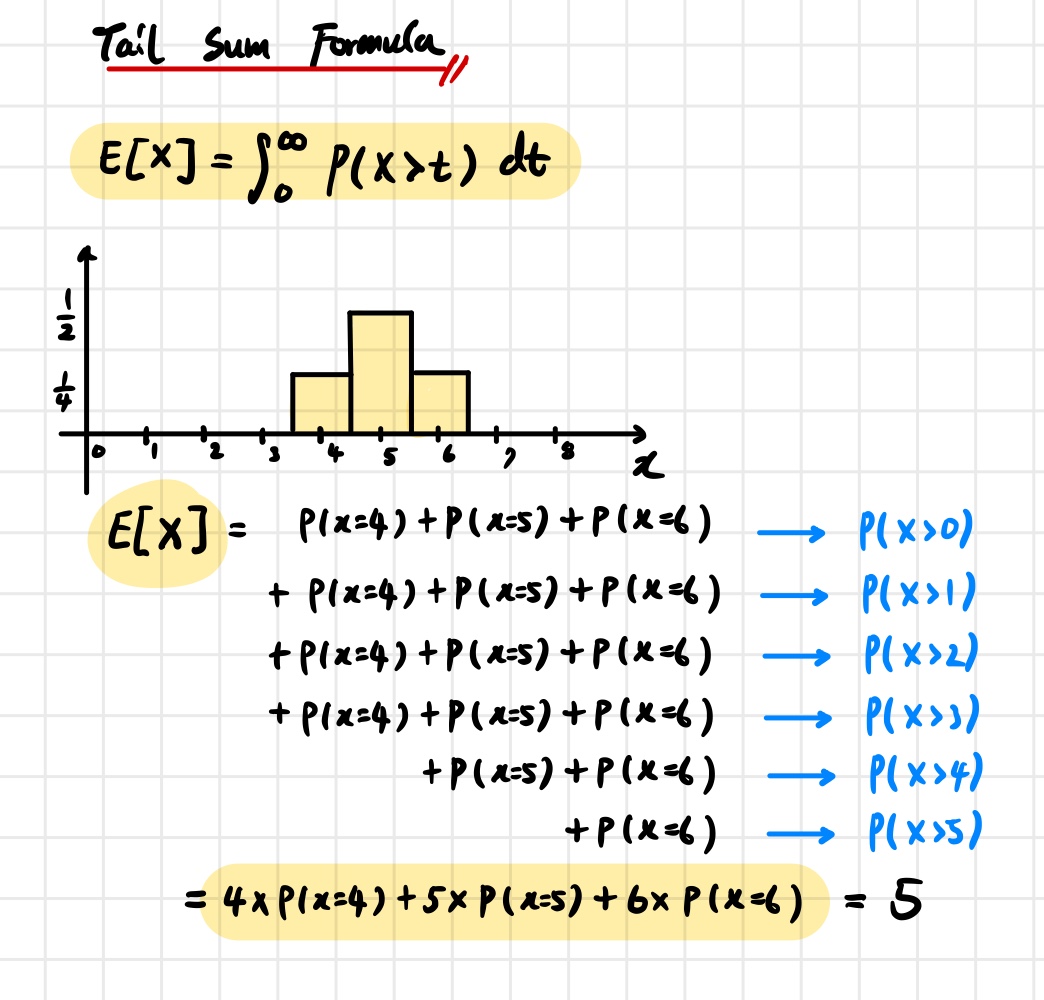
이제 DP 정의를 이용하면 아래의 부등식을 얻을 수 있다. \[\int_0^b P(A(x)>t)\,dt \le e^\epsilon \int_0^b P(A(x+\alpha)>t)\,dt + \int_0^b \delta\,dt.\]
이를 정리하면 최종적으로 Expected Output Stability Bound를 얻을 수 있다.
4.4. Robustness Condition
이제 expectation 관점에서 robustness condition을 다시 표현해보자. 기존의 deterministic condition은 아래와 같다. \[y_k(x+\alpha) > \max_{i \ne k} y_i(x+\alpha)\]
이를 expectation으로 확장하면 아래와 같은 형태의 조건을 고려할 수 있다. \[\mathbb{E}[A_k(x+\alpha)] > e^{2\epsilon}\max_{i \ne k} \mathbb{E}[A_i(x+\alpha)] + (1+e^\epsilon)\delta\]
즉, differential privacy를 만족하는 경우 위와 같은 형태의 robustness condition이 성립함을 보일 수 있다. 이 조건이 성립하면, label probability vector $y(x) = (E[A_1(x)], \ldots, E[A_K(x)])$를 기반으로 하는 multiclass classification model은 입력 $x$에 가해지는 perturbation $|\alpha|_p \le 1$ 공격에 대해 robustness를 갖는다.
이를 보이기 위해 DP 정의로부터 아래의 두 inequality를 사용한다. \[\mathbb{E}[A_i(x)] \le e^{\epsilon} \mathbb{E}[A_i(x+\alpha)] + \delta\] \[\mathbb{E}[A_i(x+\alpha)] \ge e^{-\epsilon}\big(\mathbb{E}[A_i(x)] - \delta\big)\]
이제 이를 클래스별로 나누어 살펴보자.
(1) 정답 클래스 $k$
정답 클래스에 대해서는 아래의 lower bound가 성립한다. \[\mathbb{E}[A_k(x+\alpha)] \ge e^{-\epsilon}\big(\mathbb{E}[A_k(x)] - \delta\big)\]
여기서는 정답 클래스의 값을 최대한 크게 유지하는 것이 중요하므로 lower bound를 사용한다.
(2) 비정답 클래스 $i \ne k$
비정답 클래스에 대해서는 아래의 upper bound가 성립한다. \[\mathbb{E}[A_i(x+\alpha)] \le e^{\epsilon}\mathbb{E}[A_i(x)] + \delta\]
여기서는 비정답 클래스의 값을 최대한 작게 유지하는 것이 중요하므로 upper bound를 사용한다. 따라서 모든 비정답 클래스에 대해 다음 inequality를 얻는다. \[\max_{i \ne k} \mathbb{E}[A_i(x+\alpha)] \le e^{\epsilon}\max_{i \ne k} \mathbb{E}[A_i(x)] + \delta\]
따라서, 정답 클래스의 lower bound가 비정답 클래스의 upper bound보다 크다면 robustness가 보장이 된다. 즉, 아래의 inequality가 성립하면 된다. \[e^{-\epsilon}\big(\mathbb{E}[A_k(x)] - \delta\big) > e^{\epsilon}\max_{i \ne k} \mathbb{E}[A_i(x)] + \delta\]
이 조건을 정리하면 처음에 제시한 expectation 기반 robustness condition을 얻을 수 있다.
4.5. PixelDP Certified Defense Architecture
PixelDP는 differential privacy (DP)를 neural network에 적용한 certified defense 방법으로, 각 layer의 sensitivity에 비례하여 noise를 추가함으로써 전체 모델이 $(\epsilon, \delta)$-DP를 만족하도록 설계된다.
이때 중요한 성질은 post-processing property이다. 이는 DP를 만족하는 출력에 대해 이후의 deterministic한 연산(추가적인 neural network layer 등)을 적용하더라도 DP 성질이 유지된다는 의미이다. 따라서 특정 layer까지 $(\epsilon, \delta)$-DP가 성립하면, 그 이후의 layer 출력 또한 동일한 DP 보장을 유지한다. 이 성질 때문에, 우리는 noise를 어디에 추가할지와 sensitivity를 어떻게 정의할지를 신중하게 선택해야 한다. 즉, DP 보장을 만족시키면서도 성능 손실을 최소화할 수 있는 위치를 찾는 것이 핵심이다. 예를 들어, 단순히 입력 이미지에 noise를 추가하는 경우 sensitivity는 $\Delta_{p,q} = 1$로 설정된다. 이는 가장 단순한 설정이지만, 입력 단계에서부터 정보를 직접 훼손하기 때문에 모델 성능(utility)이 크게 저하될 수 있다. 따라서 noise injection 위치는 sensitivity를 얼마나 잘 계산할 수 있는지와, 동시에 performance loss를 얼마나 줄일 수 있는지 사이의 trade-off 문제로 볼 수 있다.
sensitivity는 아래와 같이 정의된다. \[\Delta_{p,q} = \Delta_{p,q}^g = \max_{x,x' : x \ne x'} \frac{\|g(x) - g(x')\|_q}{\|x - x'\|_p}\]
논문에서는 noise를 추가하는 위치에 따라 sensitivity가 달라지는 네 가지 경우를 고려한다.
- Noise in Image : sensitivity $\Delta_{p,q} = 1$
- Noise after First Layer
- Noise Deeper in the Network : sensitivity bounding이 어려움
- Noise in Auto-encoder
![]()
각 설정마다 sensitivity를 계산하는 방법은 구조에 따라 달라지며, 이는 논문에서 상세히 다룬다.
이렇게 계산된 sensitivity를 기반으로 noise scale을 설정하면, DP 이론에 따라 전체 시스템이 $(\epsilon, \delta)$-DP를 만족하게 된다. 여기서 noise로는 Gaussian 또는 Laplacian mechanism을 사용할 수 있다.
4.5.1 Laplacian Mechanism
Laplacian mechanism은 평균이 0인 Laplace 분포에서 noise를 샘플링하는 방법이다.
이때 noise의 scale은 다음과 같이 설정된다: \[\sigma = \frac{\sqrt{2}\,\Delta_{p,1}L}{\epsilon}\]
이 메커니즘은 $(\epsilon, 0)$-DP를 보장한다.
4.5.2 Gaussian Mechanism
Gaussian mechanism은 평균이 0인 Gaussian 분포에서 noise를 샘플링하는 방법이다.
이때 noise의 scale은 다음과 같이 설정된다: \[\sigma = \frac{2\ln(1.25/\delta)\,\Delta_{p,2}L}{\epsilon}\]
이 메커니즘은 $(\epsilon, \delta)$-DP를 보장하며, 일반적으로 $\epsilon \le 1$인 경우에 성립한다.
4.6. Training PixelDP
원칙적으로 DP는 별도의 학습 과정 없이도 적용이 가능하다. 즉, 각 layer의 sensitivity를 계산한 뒤 그에 비례하는 noise를 추가하면 이론적으로 $(\epsilon, \delta)$-DP를 만족시킬 수 있다. 하지만 실제로는 이 과정이 단순하지 않다. 그 이유는 아무 제약 없이 학습된 neural network의 경우, layer의 sensitivity가 매우 크게 증가할 수 있기 때문이다. 이 경우 DP를 만족시키기 위해 필요한 noise scale 또한 커지게 되고, 결과적으로 입력 신호에 비해 noise가 상대적으로 커지면서 classification accuracy가 크게 감소하거나 decision boundary가 불안정해지는 문제가 발생한다. 따라서 실용적으로 PixelDP를 적용하기 위해서는 sensitivity 자체를 제한하는 추가적인 training 과정이 필요하다. 이를 위해 논문에서는 $p, q$ norm 설정에 따라 다양한 방식의 constraint를 적용한다.
예를 들어 $\Delta_{1,1}$, $\Delta_{1,2}$, $\Delta_{\infty,\infty}$의 경우 linear layer의 row 또는 column을 normalize하여 sensitivity를 제한하고, fixed noise variance 하에서 standard optimization (SGD)을 수행한다.
한편 $\Delta_{2,2}$의 경우 에는 SGD 이후마다 projection step을 적용하여 weight matrix를 특정 constraint set으로 사상한다. 이를 통해 pre-noise layer들이 Parseval tight frame을 만족하도록 만든다. 결과적으로 $\Delta_{2,2} = 1$이 되도록 강제할 수 있다.
4.7. PixelDP Inference
Inference 단계에서는 noisy model output $A(x)$의 expectation $\mathbb{E}[A(x)]$를 직접 계산할 수 없기 때문에, Monte Carlo sampling을 통해 이를 근사한 뒤 각 class에 대한 expected probability를 비교하여 최종 label을 결정한다.
5. Constructing Unrestricted Adversarial Examples with Generative Models (2018) — 0.4k citations
기존 adversarial attack들은 $L_\infty$ 또는 $L_2$ norm constraint 하에서 입력에 작은 perturbation을 추가하여 adversarial example을 생성한다. 그러나 이러한 방식은 픽셀 단위의 작은 변화에 제한되기 때문에, 물체의 회전, 형태 변화, 스타일 변화와 같은 semantic-level transformation을 충분히 표현하기 어렵다.
이러한 한계를 해결하기 위해 본 논문은 perturbation을 직접 pixel space에서 생성하는 대신, GAN의 generator를 이용하여 data manifold 상에서 adversarial example을 생성하는 방법을 제안한다. 즉, generator $G(z)$가 학습한 자연 이미지 공간에서 latent vector $z$를 최적화하여 classifier를 속이는 이미지를 생성한다.
아래에 PGD 기반 공격과 GAN 기반 공격을 비교한 결과를 보여준다.
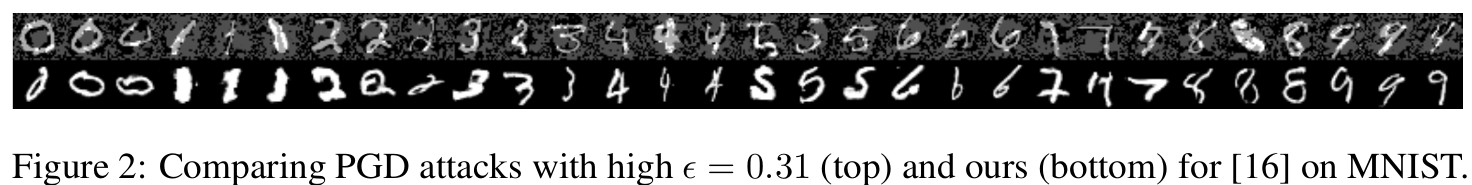
그림에서 볼 수 있듯이 PGD 기반 공격은 입력 이미지에 자잘한 노이즈를 추가하여 모델을 혼란시키는 반면, GAN 기반 공격은 latent space를 조작하여 더 자연스럽고 semantic한 변형을 가진 adversarial example을 생성한다. 즉, 단순한 noise perturbation이 아니라 객체의 형태나 특징이 유지되면서도 classifier를 잘못 분류하도록 유도하는 변형이 나타난다.
5.1. Auxiliary Classifier GAN (AC-GAN)
논문에서는 adversarial example 생성을 위해 GAN의 한 변형인 Auxiliary Classifier GAN (AC-GAN) 구조를 사용한다. AC-GAN은 conditional GAN (cGAN)을 확장한 모델로, 단순히 class 정보를 입력 조건으로 사용하는 것을 넘어, 생성된 이미지가 해당 class를 얼마나 잘 반영하는지에 대한 class consistency를 함께 학습하도록 설계된 구조이다. 여기서 class consistency란 generator가 생성한 이미지가 주어진 class label에 대해 실제 해당 class의 이미지처럼 보이도록 만드는 성질을 의미한다.
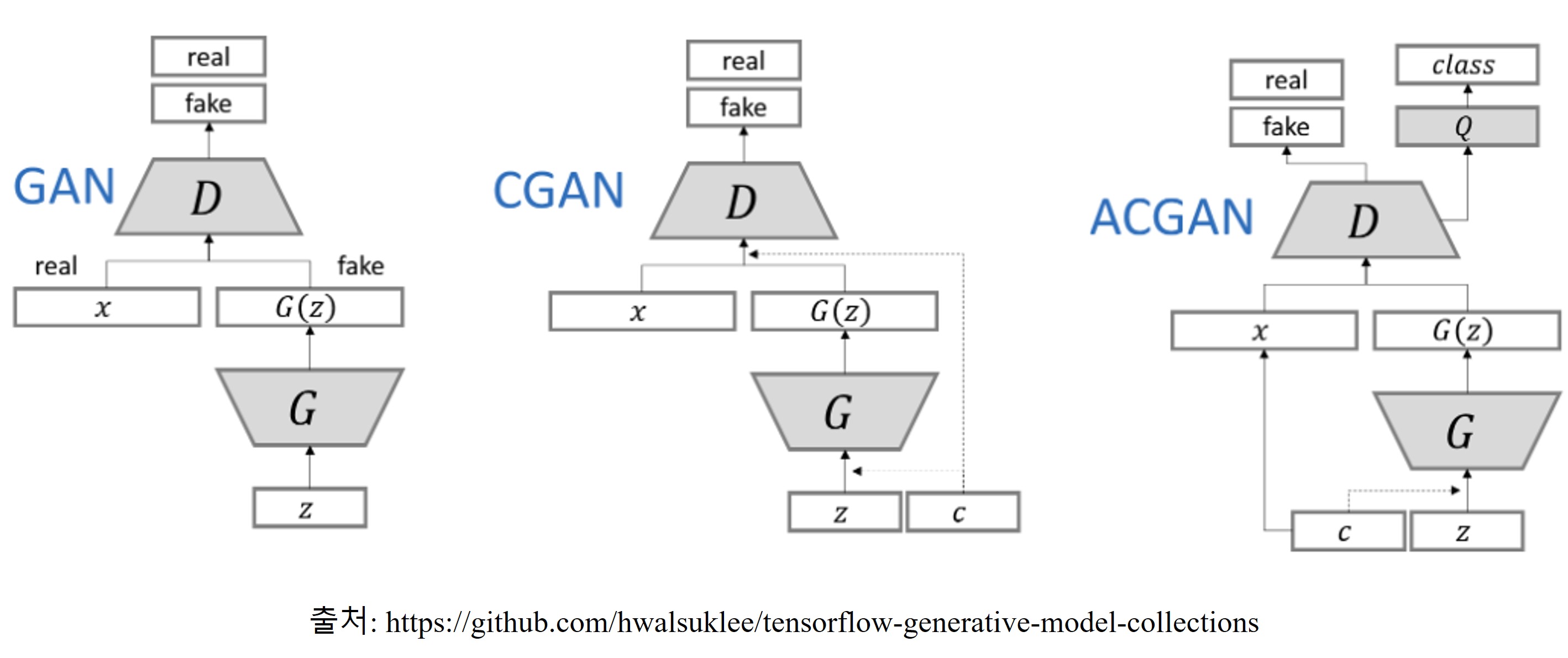
위 그림은 GAN, cGAN, AC-GAN의 차이를 비교한 것이다. cGAN은 generator와 discriminator에 class label을 조건으로 함께 넣어서 특정 class의 이미지를 생성하도록 학습한다. AC-GAN은 여기서 discriminator의 구조를 한 단계 더 확장한다. 기존의 real/fake 판별 기능에 더해, 입력 이미지가 어떤 class에 속하는지를 예측하는 classification branch를 추가한다. 즉 discriminator는 아래의 두 가지 역할을 동시에 수행한다.
- real/fake 판별 (adversarial head)
- class label 예측 (auxiliary classifier head)
이 구조에서 generator는 단순히 discriminator를 속이는 것뿐만 아니라, auxiliary classifier가 올바른 class를 예측하도록 만드는 방향으로도 학습된다. 다시 말해 generator는 adversarial loss와 classification loss를 동시에 받는다.
이 덕분에 AC-GAN은 cGAN보다 생성된 이미지가 특정 class의 특징을 더 잘 유지하는 경향이 있다. 즉, class consistency가 더 강하게 나타나는 generator를 학습할 수 있다.
5.2. Adversarial Example Generation
$g_\theta(z,y)$와 $c_\phi(x)$를 각각 AC-GAN의 generator와 auxiliary classifier라고 하고, $f(x)$를 공격 대상 classifier라고 하자.
Unrestricted adversarial example을 생성하기 위해 latent variable $z$를 최적화 변수로 두고, 다음 loss 함수 최소화하는 문제로 formulation한다. \[L = L_0 + \lambda_1 L_1 + \lambda_2 L_2,\]
여기서 $\lambda_1, \lambda_2$는 각 loss 항의 중요도를 조절하는 hyperparameter이다. 각 loss 항은 아래과 같이 정의된다. \[\begin{aligned} L_0 &\triangleq -\log f(y_{\text{target}} \mid g_\theta(z, y_{\text{source}})), \\ L_1 &\triangleq \frac{1}{m} \sum_{i=1}^{m} \max\left(|z_i - z_i^0| - \epsilon, 0\right), \\ L_2 &\triangleq -\log c_\phi\big(y_{\text{source}} \mid g_\theta(z, y_{\text{source}})\big). \end{aligned}\]
각 항의 역할은 아래과 같다.
$L_0$ (attack objective)
생성된 이미지 $g_\theta(z, y_{\text{source}})$가 target classifier $f$에 의해 target label $y_{\text{target}}$로 분류되도록 유도하는 공격 항이다.$L_1$ (latent space regularization)
기준 latent vector $z^0$로부터 $z$가 과도하게 벗어나지 않도록 제한하는 regularization term이다. 이를 통해 latent space에서 자연스러운 manifold를 크게 이탈하지 않으면서 adversarial example을 생성할 수 있다.$L_2$ (class consistency constraint)
generator의 출력이 auxiliary classifier $c_\phi$에 의해 source class $y_{\text{source}}$로 유지되도록 유도하여 AC-GAN의 class consistency를 보존한다.
5.3. Code Implementation
정확한 구현은 아니지만 아래와 같은 형태로 구현할 수 있다.
# initialize latent code
z = torch.randn(batch_size, z_dim, requires_grad=True)
optimizer = torch.optim.Adam([z], lr=1e-2)
for _ in range(num_steps):
x = g_theta(z, y_source)
L0 = -torch.log(f(x)[..., y_target])
L1 = torch.mean(torch.clamp(torch.abs(z - z0) - eps, min=0))
L2 = -torch.log(c_phi(x)[..., y_source])
loss = L0 + lambda1 * L1 + lambda2 * L2
optimizer.zero_grad()
loss.backward()
optimizer.step()
6. Obfuscated Gradients Give a False Sense of Security (2018) — 4.4k citations
Adversarial training을 포함한 여러 방어 기법들이 iterative optimization 기반 attack에 대해 효과적으로 동작하는 것처럼 보이는 경우가 있다.
하지만 이는 실제로 robustness를 달성한 것이 아니라, gradient 정보를 왜곡하거나 숨기는 obfuscated gradient 현상에 의해 생긴 착시일 수 있음을 지적한다.
이 논문은 이러한 obfuscated gradient를 크게 세 가지 유형으로 정리한다: shattered gradients, stochastic gradients, 그리고 vanishing/exploding gradients.
또한 각 유형에서 기존 gradient-based attack이 왜 실패하는지 분석하고, 이를 우회하여 공격하는 방법들을 제시한다.
더 나아가 기존 방어 기법들이 실제로 어떤 방식으로 gradient를 숨기고 있는지 체계적으로 분석하며, 이러한 방어들이 실제 robustness를 제공하지 못함을 실험적으로 보여준다.
논문의 주요 기여는 아래과 같다.
- 기존 방어 기법들이 공유하는 문제점(obfuscated gradients)을 유형별로 체계적으로 정리하고 분석.
- adversarial training을 제외한 다수의 방어 기법이 gradient masking에 해당함을 보이며 효과적으로 파훼.
- 미분 불가능하거나 stochastic한 방어를 공격할 수 있는 BPDA (Backward Pass Differentiable Approximation) 기법 제시.
6.1. Shattered Gradients
일부 방어 기법은 비미분 연산을 사용하여 gradient 계산을 어렵게 만든다. 이 경우 공격자는 정확한 gradient를 얻을 수 없기 때문에 iterative optimization 기반 공격이 제대로 동작하지 않는다. 신경망을 아래와 같이 표현하자. \[f(x)=f^{j+1}(f^j(\cdots f^1(x)))\]
만약 중간 계층 $f^i$가 미분 불가능하다면 chain rule을 적용할 수 없으므로 gradient 계산이 막히게 된다. 이러한 현상을 논문에서는 shattered gradient라고 부른다.
6.1.1. Backward Pass Differentiable Approximation (BPDA)
BPDA는 미분 불가능한 연산을 미분 가능한 함수로 근사하여 gradient를 계산하는 방법이다. 핵심 아이디어는 forward pass와 backward pass에서 서로 다른 함수를 사용하는 것이다.
Forward pass에서는 원래 연산을 그대로 사용한다. \[y=f^i(x)\]
반면 backward pass에서는 이를 근사하는 미분 가능한 함수 $g(x)$를 사용한다. \[f^i(x)\approx g(x)\]
즉, 실제 모델은 그대로 유지하면서 gradient 계산만 우회하는 것이다. 근사 함수로 인해 gradient에 오차가 발생하지만, 공격에 필요한 방향 정보는 대부분 유지된다. 실제로 논문은 많은 gradient masking 기반 방어가 BPDA만으로 쉽게 무너진다는 것을 보인다.
6.2. Stochastic Gradients
일부 방어 기법은 추론 시 무작위성을 추가한다. 예를 들어 입력을 매번 다른 각도로 회전시키거나 랜덤 노이즈를 삽입할 수 있다. 이 경우 동일한 입력이라도 매번 다른 gradient가 계산된다. 따라서 공격자는 어느 방향으로 입력을 업데이트해야 할지 알기 어렵다.
6.2.1. Expectation Over Transformation (EoT)
EoT는 이러한 무작위성을 제거하려고 하지 않는다. 대신 모든 transformation에 대한 평균적인 gradient를 이용해 공격을 수행한다. 최적화 대상은 아래과 같다. \[\mathbb{E}_{t\sim T}[f(t(x))]\]
미분과 기댓값을 교환할 수 있으므로 아래 식이 성립한다. \[\nabla_x \mathbb{E}_{t\sim T}[f(t(x))] = \mathbb{E}_{t\sim T} \left[ \nabla_x f(t(x)) \right]\]
즉, 여러 transformation에 대해 gradient를 계산한 뒤 그 평균을 사용하면 된다. 회전 방어의 경우를 생각해보면, 여러 회전 각도에서 gradient를 계산한 뒤 이를 평균내어 입력을 업데이트하는 방식이다.
6.3. Vanishing / Exploding Gradients
일부 방어 기법은 gradient가 지나치게 작거나 크게 만들어 optimization을 어렵게 한다. 이 경우 공격은 진행되더라도 업데이트가 거의 일어나지 않거나, 반대로 불안정하게 발산하게 된다.
6.3.1. Reparameterization
논문은 이러한 문제를 해결하기 위해 최적화 변수를 다시 정의하는 reparameterization 기법을 사용한다. 예를 들어 방어 기법이 입력에 어떤 전처리 함수 $g$를 적용한다고 하자. 공격자는 전처리 이후의 입력을 직접 최적화하는 대신 새로운 변수 $z$를 도입한다. 입력은 아래와 같이 표현할 수 있다. \[x = h(z)\]
그러면 원래 최적화 문제인 $\max_x f(g(x))$ 를 아래와 같이 다시 쓸 수 있다. \[\max_z f(g(h(z)))\]
이렇게 하면 gradient가 소실되거나 폭주하는 입력 공간을 우회하여 보다 안정적으로 최적화를 수행할 수 있다. 즉, reparameterization의 핵심은 모델을 바꾸는 것이 아니라 공격이 수행되는 최적화 공간을 바꾸는 것이다.
6.4. Case Study
논문에서는 아래의 방어 기법들을 분석하고, 각각에 대한 공격 방법을 제시한다. 자세한 내용은 원문 논문을 참고하기 바란다.
- Thermometer Encoding: One Hot Way to Resist Adversarial Examples(2018) — 0.8k citations
- Countering Adversarial Images using Input Transformations (2017) — 2.1k citations
- Characterizing Adversarial Subspaces Using Local Intrinsic Dimensionality (2018) — 1k citations
- Stochastic Activation Pruning for Robust Adversarial Defense (2018) — 0.8k citations
- Mitigating Adversarial Effects Through Randomization (2017) — 1.6k citations
- PixelDefend: Leveraging Generative Model to Understand and Defend Against Adversarial Examples (2018) — 1.1k citations
- DefenceGAN: Protecting Classifiers Against Adversarial Attacks using GANs (2018) — 1.7k citations
7. Adversarial Examples Are Not Bugs, They Are Features (2019) — 2.7k citations
그렇다면 adversarial example은 왜 발생하는 것일까? 이 논문은 그 원인을 non-robust feature에서 찾는다. 논문에서는 분류에 활용되는 유의미한 feature를 크게 robust feature와 non-robust feature로 구분한다.
- Robust feature는 label 예측에 유용하면서도 작은 perturbation이 추가되어도 그 예측력이 유지되는 feature이다. 이러한 feature는 대체로 사람이 인식하는 semantic 정보와 유사하다.
- Non-robust feature는 label 예측에는 유용하지만 작은 perturbation에 의해 쉽게 변하는 feature이다. 이러한 feature는 인간이 직접 인식하기 어려운 미세한 통계적 패턴인 경우가 많다.
즉, 모델은 사람이 주목하는 semantic feature뿐만 아니라 사람이 거의 인식하지 못하는 non-robust feature도 함께 활용해 분류를 수행한다. Adversarial perturbation은 바로 이러한 non-robust feature를 조작하여 모델의 예측을 바꾸는 역할을 한다.
다시 말해 adversarial example은 모델이 강하게 활용하는 non-robust feature 방향에서 가장 쉽게 생성된다. 이러한 feature는 작은 perturbation에 취약하지만, 원래는 label 예측에 유용한 정보를 담고 있다.
논문의 주요 기여는 다음과 같다.
- Adversarial perturbation을 단순한 노이즈가 아니라 non-robust feature를 조작한 결과라는 새로운 관점에서 설명하였다.
- 서로 다른 모델 사이에서 adversarial example이 전이되는 transferability 현상을 자연스럽게 설명하였다.
- 데이터셋으로부터 robust feature와 non-robust feature를 분리하여 분석하는 방법을 제시하였다.
7.1. The Robust Features Model
논문에서는 robust feature와 non-robust feature를 구분하기 위해 Binary Classification 문제를 고려한다. Feature는 입력 공간 $X$의 데이터를 받아 하나의 실수값을 출력하는 함수이다. 예를 들어 이미지 분류 문제에서 입력 $x$가 이미지라면 다음과 같은 것들이 모두 feature가 될 수 있다.
- 귀의 뾰족한 정도
- 털의 질감
- 특정 방향의 edge 강도
- 특정 CNN neuron의 activation 값
중요한 점은 feature를 사람이 이해할 수 있는 semantic feature로 한정하지 않는다는 것이다. 인간이 직접 해석하기 어려운 통계적 신호 역시 모두 feature로 간주한다. 이제 논문에서 useful feature, robust feature, 그리고 non-robust feature를 어떻게 정의하는지 살펴보자.
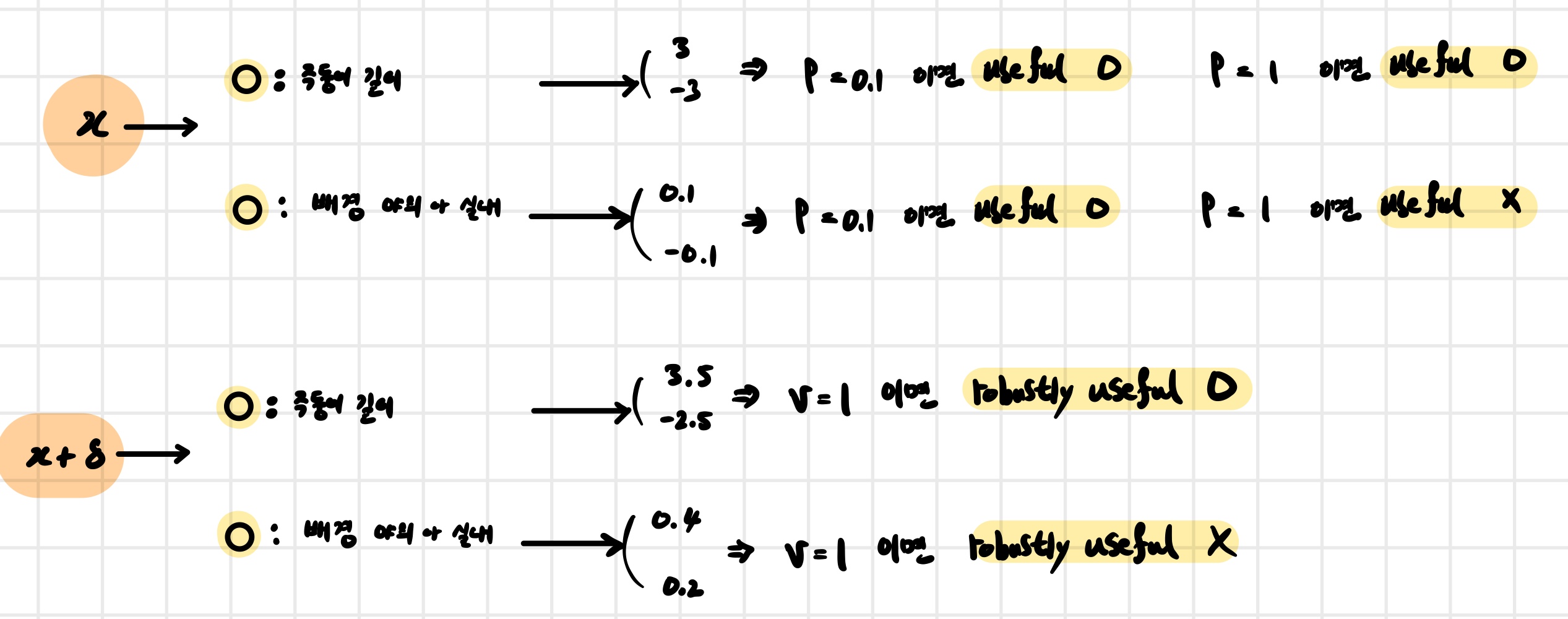
7.1.1. $\rho$-useful features
다음 조건을 만족하는 feature를 $\rho$-useful feature라고 정의한다. \[\mathbb{E}_{(x,y)\sim D}[y \cdot f(x)] \geq \rho\]
이는 feature $f$가 label $y$와 양의 상관관계를 가지고 있음을 의미한다. 즉, 해당 feature가 분류에 유용한 정보를 담고 있다는 뜻이다.
7.1.2. $\gamma$-robustly useful features
다음 조건을 만족하는 feature를 $\gamma$-robustly useful feature라고 정의한다. \[\mathbb{E}*{(x,y)\sim D} \left[ \inf*{\delta \in \Delta(x)} y \cdot f(x+\delta) \right] \geq \gamma\]
여기서 $\Delta(x)$는 허용된 perturbation 집합이다.
이 식은 가능한 모든 adversarial perturbation 중 가장 불리한 경우를 고려하더라도, 해당 feature가 여전히 label 예측에 도움이 되는지를 측정한다. 즉, robustly useful feature는 작은 perturbation이 추가되어도 predictive한 성질이 유지되는 feature이다.
7.1.3. Useful, non-robust features
$\rho$-useful feature이지만 $\gamma$-robustly useful feature가 아닌 경우를 useful but non-robust feature라고 정의한다. 즉, 원래는 label 예측에 유용하지만 adversarial perturbation에 의해 그 예측력이 쉽게 무너지는 feature를 의미한다. 다시 말해 adversarial example은 모델이 강하게 활용하는 이러한 non-robust feature를 조작함으로써 생성된다.
7.2. Disentangling Robust and Non-Robust Features
Adversarial training은 모델이 non-robust feature에 의존하지 않도록 학습시키는 방법으로 해석할 수 있다. 그렇다면 robust feature와 non-robust feature를 실제로 분리한 데이터셋을 만들 수 있을까?
논문에서는 먼저 adversarially trained model의 feature extractor $g(x)$를 사용한다. Adversarially trained model은 robust feature를 주로 활용하므로, $g(x)$는 입력 이미지의 robust feature를 잘 반영한다고 볼 수 있다.
이제 원본 이미지 $x$와 동일한 robust representation을 가지는 새로운 이미지 $x_r$를 찾는다. 이를 위해 다음 objective를 최소화한다. \[\min_{x_r} \| g(x_r) - g(x) \|_2\]
즉, feature space에서 원본 이미지와 동일한 representation을 갖도록 이미지를 최적화하는 것이다.
Adversarially trained model의 representation은 주로 robust feature를 반영하므로, 이렇게 생성된 $x_r$는 원본 이미지의 robust feature는 유지하면서 non-robust feature는 제거된 이미지로 볼 수 있다. 이를 이용해 논문은 robust dataset $D_R$과 non-robust dataset $D_{NR}$을 구성한다.
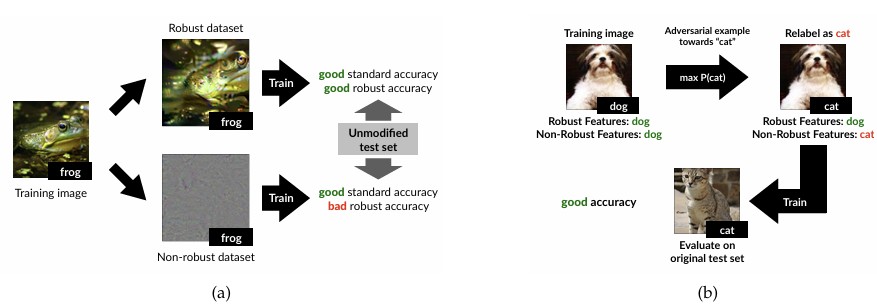
흥미로운 점은 non-robust feature만 포함된 $D_{NR}$로 학습하더라도 높은 standard accuracy를 얻을 수 있다는 것이다. 이는 non-robust feature 역시 label 예측에 충분히 유용한 정보를 담고 있음을 보여준다.
또한 $(b)$의 실험에서는 dog 이미지에 cat의 non-robust feature를 주입한 뒤 해당 이미지를 cat으로 라벨링하여 학습시켰다. 그 결과 모델은 실제로 cat을 인식하는 방향으로 학습되었다. 이는 모델이 인간이 인식하는 semantic 정보보다 non-robust feature를 적극적으로 활용하고 있음을 보여주는 결과이다.
다음은 $D_{R}$ 과 $D_{NR}$ 로 각각 학습한 모델의 성능이다.
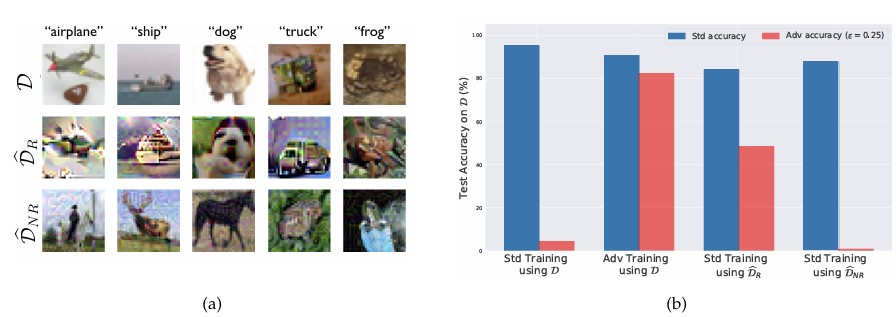
$D_R$ 로 학습한 모델은 adversarial training을 수행하지 않았음에도 높은 adversarial accuracy를 보인다. 반면 $D_{NR}$ 로 학습한 모델은 standard accuracy는 높지만 adversarial perturbation에 매우 취약하다. 이는 adversarial robustness가 데이터에 포함된 robust feature와 밀접하게 연관되어 있음을 시사한다.
아래 그림은 adversarial example의 transferability를 보여준다.
![]()
논문은 이러한 transferability 역시 non-robust feature 관점에서 설명한다. 서로 다른 모델들이 데이터셋에 존재하는 동일한 non-robust feature를 학습하기 때문에, 한 모델을 공격하여 생성한 adversarial example이 다른 모델에서도 동일하게 동작한다는 것이다.
또한 모델의 standard accuracy가 높을수록 transferability 역시 증가하는 경향을 보인다. 이는 성능이 좋은 모델일수록 데이터에 존재하는 predictive한 non-robust feature를 더 효과적으로 학습하기 때문으로 해석할 수 있다.
