Weight Decay: L1 & L2 Regularization
in projects on Optimizer, Deeplearning, MachineLearning
Weight Decay는 딥러닝에서 가중치의 크기를 제한하여 모델의 복잡도를 조절하는 대표적인 정규화 기법이다. 단순히 파라미터를 작게 만드는 방법처럼 보이지만, 실제로는 데이터가 특정 방향으로 얼마나 잘 관측되었는지에 따라 학습의 민감도를 조절하는 역할을 한다. 특히 선형 모델 관점에서 보면 Weight Decay는 데이터 행렬의 singular value 분포, 즉 스펙트럼 구조에 따라 서로 다른 방향을 다르게 처리하는 것으로 해석할 수 있다. 또한 이러한 정규화는 Bayesian 관점에서도 해석할 수 있다. 가중치에 Gaussian prior를 가정하면 L2 regularization과 동일한 형태의 MAP estimation으로 이어지며, Laplacian prior를 가정하면 L1 regularization과 같은 형태로 연결된다. 즉 정규화 기법은 단순한 heuristic이 아니라, 가중치에 대한 사전 확률 가정을 반영한 추론 과정으로 볼 수 있다. 따라서 다양한 데이터 조건과 prior 가정 하에서 Weight Decay 및 L1/L2 정규화가 모델의 안정성과 일반화 성능에 어떤 방식으로 기여하는지를 단계적으로 살펴본다.
1. Weight Decay 란?
딥러닝은 입력과 정답 레이블 쌍 $(x, y)$이 주어졌을 때, 비선형 모델 $f_\theta(x)$가 정답 $y$를 잘 근사하도록 학습하는 과정이다. 이를 위해 손실 함수 $\mathcal{L}(f_\theta(x), y)$를 정의하고, 이 값을 최소화하도록 모델 파라미터 $\theta$를 최적화한다. Weight Decay는 학습 과정에서 가중치 $\theta$가 과도하게 커지는 것을 방지하기 위해, 가중치의 크기를 작게 유지하도록 유도하는 정규화 기법이다. 이는 모델이 지나치게 복잡한 해보다 상대적으로 단순하고 안정적인 해를 선호하도록 만드는 inductive bias를 학습 과정에 반영한다. 결과적으로 모델의 복잡도를 제어하고 일반화 성능을 향상시키는 데 도움을 준다.
딥러닝 모델은 일반적으로 Gradient Descent를 통해 손실 함수를 최소화한다. \[\theta_{t+1} = \theta_t - \alpha \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y)\]
여기서 $\theta_t$는 $t$ 시점의 가중치이며, $\alpha$는 learning rate이다. Weight Decay를 적용하면 매 업데이트 단계에서 가중치가 원점 방향으로 수축되며, 파라미터는 다음과 같이 갱신된다. \[\theta_{t+1} = (1 - \lambda)\theta_t - \alpha \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y)\]
여기서 $\lambda \in [0,1]$는 decay rate이다. $(1-\lambda)\theta_t$ 항은 매 업데이트마다 가중치의 크기를 일정 비율만큼 감소시키는 역할을 한다. 따라서 Weight Decay는 큰 가중치가 형성되는 것을 억제하여 모델이 과도하게 복잡한 함수를 학습하는 것을 방지하고, 보다 단순한 해를 선호하도록 유도한다.
2. Weight decay 기법이 어떻게 정규화에 도움이 될까?
모델의 가중치가 매우 크다면 입력의 작은 변화에도 출력이 크게 변할 수 있다. 이 경우 모델은 데이터의 본질적인 패턴뿐만 아니라 노이즈나 우연한 변동까지 과도하게 학습하게 될 수 있다. 결과적으로 훈련 데이터에는 높은 성능을 보이지만, 보지 못한 데이터에서는 성능이 저하되는 과적합이 발생할 수 있다. Weight Decay는 가중치의 크기를 제한함으로써 이러한 현상을 완화하고 모델이 보다 단순한 함수를 학습하도록 유도한다.
3. L1 & L2 regularization은 그러면 뭘까?
지금까지 살펴본 Weight Decay는 매 업데이트마다 가중치를 일정 비율만큼 감소시키는 방식으로 동작한다. 그런데 논문이나 교재를 읽다 보면 Weight Decay 대신 L1 또는 L2 Regularization을 사용하는 경우를 자주 볼 수 있다. 특히 L2 Regularization은 많은 문헌에서 Weight Decay와 거의 같은 의미로 사용되는데, 그 이유는 SGD(Stochastic Gradient Descent) 환경에서 두 방법이 동일한 형태의 업데이트를 생성하기 때문이다. SGD의 기본 업데이트 식은 다음과 같다. \[\theta_{t+1} = \theta_t - \alpha \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y)\]
그리고 L2 Regularization을 적용하면 손실 함수는 다음과 같이 정의된다. \[\mathcal{L}_{\text{Ridge}}(f_{\theta_t}(x), y) = \mathcal{L}(f_{\theta_t}(x), y) + \frac{\lambda_{\text{Ridge}}}{2}||\theta_t||_2^{2}\]
다음으로 이 손실 함수에 대해 SGD를 적용하면 아래와 같이 나온다. \[\begin{aligned} \theta_{t+1} &= \theta_t - \alpha ( \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y) + \lambda_{\text{Ridge}} \theta_t ) \\ &= (1-\alpha \lambda_{\text{Ridge}} )\theta_t - \alpha \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y) \end{aligned}\]
이는 앞서 살펴본 Weight Decay의 업데이트 식과 동일한 형태이다. 즉, SGD를 사용하는 경우 L2 Regularization은 매 스텝마다 가중치를 원점 방향으로 수축시키는 효과를 가지며, 결과적으로 Weight Decay와 동일하게 동작한다.
4. 그렇다면 weight decay와 L1 정규화의 관계는?
L1 정규화는 SGD에서 L2 정규화처럼 Weight Decay와 동일한 업데이트 식으로 변환되지는 않는다. 그러나 가중치의 크기를 억제한다는 관점에서, 일부 논문에서는 L1 정규화 역시 넓은 의미의 Weight Decay로 분류하기도 한다. \[\mathcal{L}_{\text{Lasso}}(f_{\theta_t}(x), y) = \mathcal{L}(f_{\theta_t}(x), y) + \lambda_{\text{Lasso}} ||\theta_t||_1\]
L1 정규화는 가중치의 절댓값 합에 페널티를 부여하기 때문에, 일부 가중치를 정확히 0으로 만드는 희소성(sparsity)을 유도하는 특징이 있다. L1 정규화와 L2 정규화를 함께 사용하는 Elastic Net 역시 같은 맥락에서 이해할 수 있다. \[\mathcal{L}_{\text{Elastic}}(f_{\theta_t}(x), y) = \mathcal{L}(f_{\theta_t}(x), y)+ \lambda_{1} ||\theta_t||_1 + \lambda_{2}||\theta_t||_2^{2}\]
Elastic Net은 L1 정규화의 희소성과 L2 정규화의 안정성을 동시에 활용하기 위해 사용된다.
5. L1 & L2 정규화 효과는?
L1 정규화와 L2 정규화를 적용했을 때 gradient 는 아래와 같다. \[\nabla_\theta \mathcal{L}_{Ridge}(f_{\theta_t}(x), y) = \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y) + \lambda_{\text{Ridge}}\theta_t\] \[\nabla_\theta \mathcal{L}_{\text{Lasso}}(f_{\theta_t}(x), y) = \nabla_\theta \mathcal{L}(f_{\theta_t}(x), y) + \lambda_{\text{Lasso}} \text{sgn}(\theta_t)\]
수식에서 볼 수 있듯이 L2 정규화는 가중치의 크기에 비례하는 페널티를 부여한다. 따라서 큰 가중치는 크게 감소시키고 작은 가중치는 상대적으로 적게 감소시키도록 유도한다. 결과적으로 특정 가중치가 지나치게 커지는 것을 방지하며, 전체 가중치가 보다 균형 있게 분포하도록 만든다.
반면 L1 정규화는 가중치의 크기와 무관하게 일정한 크기의 페널티를 부여한다. 따라서 작은 가중치들은 상대적으로 더 쉽게 0으로 수렴하게 되며, 결과적으로 많은 가중치가 정확히 0이 되는 희소한(sparse) 모델을 유도한다. 그래서 L2 정규화는 가중치의 크기를 전반적으로 줄이는 효과가 있는 반면, L1 정규화는 중요하지 않은 가중치를 제거하여 보다 희소한 표현을 만드는 경향이 있다..
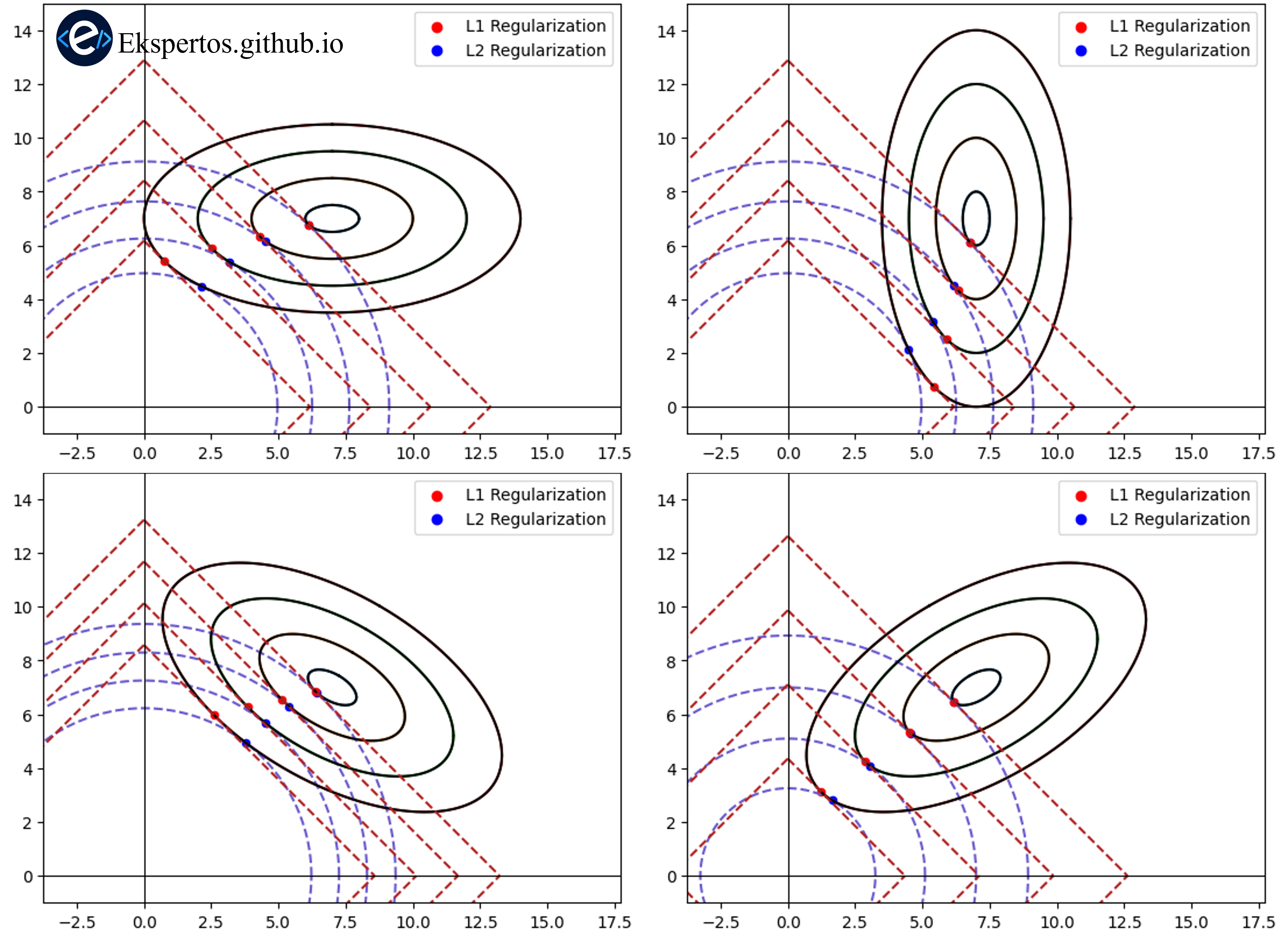
그림에서 볼 수 있듯이 L1 정규화와 L2 정규화는 모두 가중치의 크기를 줄이는 방향으로 작용한다. 그러나 L1 정규화의 경우 제약 영역이 다이아몬드 형태를 가지기 때문에 최적해가 좌표축과 만나는 지점에서 발생할 가능성이 높다. 이로 인해 일부 가중치가 정확히 0이 되거나 0에 매우 가까워지는 현상이 나타나며, 결과적으로 희소성이 유도된다. 반면 L2 정규화는 원형 형태의 제약 영역을 가지므로 모든 방향에서 균등하게 수축이 발생하며, 가중치 전체가 작아지지만 특정 성분이 정확히 0이 되는 경우는 상대적으로 드물다.
6. Bayesian Estimation 관점에서 본 L1 & L2 정규화
지금까지는 정규화를 가중치의 크기를 제한하는 관점에서 살펴보았다. 그러나 정규화는 Bayesian Estimation 관점에서도 자연스럽게 해석할 수 있다. 특히 L1 정규화와 L2 정규화는 각각 서로 다른 prior distribution을 가정한 Maximum A Posteriori(MAP) Estimation과 밀접한 관련이 있다.
MAP Estimation은 관측된 데이터 $x$가 주어졌을 때 posterior probability를 최대화하는 파라미터 $\theta$를 찾는 방법이다. 이때 MAP Estimation은 다음과 같은 최적화 문제로 정의된다. \[\theta_{\text{MAP}} = \arg\max_\theta p(\theta|x)\]
Bayes 정리에 의해 posterior probability는 likelihood와 prior의 곱으로 분해될 수 있다. 이를 수식으로 나타내면 다음과 같다. \[p(\theta|x) = \frac{p(x|\theta)p(\theta)}{p(x)}\]
여기서 $p(x)$는 $\theta$에 의존하지 않는 상수이므로, MAP Estimation은 다음과 같이 단순화할 수 있다. \[\theta_{\text{MAP}} = \arg\max_\theta p(x|\theta)p(\theta)\]
이를 다시 로그 형태로 변환하면 곱셈 구조가 덧셈 구조로 바뀌어 다음과 같이 표현된다. \[\theta_{\text{MAP}} = \arg\max_\theta \left[ \log p(x|\theta) + \log p(\theta) \right]\]
여기서 첫 번째 항은 데이터에 대한 likelihood를 의미하고, 두 번째 항은 파라미터에 대한 prior distribution을 의미한다. 즉 MAP Estimation은 데이터에 잘 맞는 파라미터를 찾는 동시에, 사전적으로 더 그럴듯한 파라미터를 선호하도록 하는 최적화 과정이다.
만약 가중치 $\theta$가 평균이 0인 Gaussian 분포를 따른다고 가정하면, prior는 다음과 같이 표현된다. \[p(\theta) \propto \exp \left( -\frac{\lambda}{2} \|\theta\|_2^2 \right)\]
이때 log prior는 다음과 같이 정리된다. \[\log p(\theta) = -\frac{\lambda}{2} \|\theta\|_2^2 + C\]
따라서 MAP Estimation은 L2 정규화(Ridge Regression)와 동일한 형태의 목적함수를 갖게 된다.
반면 가중치 $\theta$가 Laplace 분포를 따른다고 가정하면 prior는 다음과 같이 주어진다. \[p(\theta) \propto \exp \left( -\lambda \|\theta\|_1 \right)\]
이 경우 log prior는 다음과 같이 표현된다. \[\log p(\theta) = -\lambda \|\theta\|_1 + C\]
따라서 MAP Estimation은 L1 정규화(Lasso Regression)와 동일한 목적함수를 갖게 된다.
즉 Bayesian 관점에서 보면, L2 정규화는 가중치가 Gaussian 분포를 따른다는 사전 가정을 반영한 것이고, L1 정규화는 가중치가 Laplace 분포를 따른다는 사전 가정을 반영한 것으로 해석할 수 있다.
prior는 데이터 생성의 진실을 설명하는 것이 아니라, 동일한 training loss를 만족하는 여러 해 중에서 어떤 해를 더 좋은 해로 볼 것인지 정의하는 inductive bias이다.
L2 regularization은 Gaussian prior에 해당하며, 파라미터가 0 근처에 있을수록 더 선호되고 크기가 커질수록 부드럽게 페널티가 증가하는 구조를 만든다. 그 결과 optimizer는 작은 크기의 weight를 가진 dense한 해를 선호하게 된다.
반면 L1 regularization은 Laplace prior에 해당하며, 파라미터 공간에서 희소한(sparse) 구조를 더 높은 확률로 두는 방식이다. 그 결과 optimizer는 많은 parameter를 정확히 0으로 만드는 sparse한 해를 선호하게 된다.
7. 그렇다면 Adam Optimizer에서는 L2 Regularization을 사용할까?
SGD에서의 Weight Decay는 모든 파라미터에 동일한 decay coefficient를 적용하여 각 가중치를 현재 값에 비례해 감소시킨다.
반면 Adam은 각 파라미터마다 서로 다른 adaptive learning rate를 적용한다. 따라서 손실 함수에 L2 regularization term을 추가하면, regularization에 의해 발생한 gradient 역시 Adam의 adaptive scaling을 함께 받게 된다.
즉 Adam에서의 L2 regularization은 \[\nabla_\theta \mathcal{L} + \lambda \theta\]
를 사용하는 것이지만, 실제 업데이트는 \[\theta_{t+1} = \theta_t - \alpha \frac{m_t}{\sqrt{v_t}+\epsilon}\]
형태로 이루어진다. 따라서 regularization term인 $\lambda\theta$ 역시 각 파라미터의 $\sqrt{v_t}$에 의해 서로 다른 크기로 조정된다.
결과적으로 Adam에서 L2 regularization은 SGD에서의 Weight Decay처럼 모든 가중치를 동일한 비율로 감소시키는 효과를 갖지 않는다. 다시 말해, SGD에서는 L2 regularization과 Weight Decay가 동등하지만 Adam에서는 더 이상 동등하지 않다.
이를 기하학적으로 해석하면, SGD는 Euclidean geometry 상에서 동일한 비율의 shrinkage를 적용하는 반면, Adam은 adaptive preconditioning을 통해 최적화 공간 자체를 변형한다. 따라서 L2 penalty가 유도하는 shrinkage 역시 파라미터마다 서로 다른 크기로 적용된다.
이 문제를 해결하기 위해 제안된 방법이 AdamW이다. AdamW는 L2 regularization을 gradient에 포함시키지 않고, \[\theta \leftarrow (1-\lambda)\theta\]
를 별도의 연산으로 적용한다.
즉 업데이트 식은 \[\theta_{t+1} = (1-\lambda)\theta_t - \alpha \frac{m_t}{\sqrt{v_t}+\epsilon}\]
가 된다.
이를 통해 모든 파라미터에 동일한 Weight Decay를 적용할 수 있으며, learning rate와 regularization strength를 보다 독립적으로 제어할 수 있다.
즉 AdamW의 핵심 아이디어는 L2 regularization과 Weight Decay를 분리(decouple)하여 SGD에서의 Weight Decay와 동일한 효과를 복원하는 것이다.
8. 그렇다면 모델 가중치들이 작아진다면 Learning Rate를 높여주어야 할까?
Weight Decay는 학습 과정에서 가중치의 크기를 지속적으로 감소시킨다. 그렇다면 가중치가 작아질수록 gradient의 크기 역시 작아지므로, 이를 보상하기 위해 Learning Rate를 높여주어야 하는 것은 아닐까?
실제로 이러한 현상은 어느 정도 존재한다. 신경망의 역전파 과정에서 gradient는 각 층의 가중치를 거쳐 전달되므로, 가중치의 크기가 작아질수록 이전 층으로 전달되는 gradient 역시 작아질 수 있다. 예를 들어 선형 계층 $h = Wx$ 에 대해 입력으로 전달되는 gradient는 \[\frac{\partial \mathcal{L}}{\partial x} = W^\top \frac{\partial \mathcal{L}}{\partial h}\]
가 된다. 따라서 Weight Decay에 의해 $W$가 작아지면 역전파되는 gradient의 크기 역시 감소하는 경향이 있다. 특히 깊은 네트워크에서는 이러한 효과가 여러 층에 걸쳐 누적될 수 있다.
그러나 그렇다고 해서 Weight Decay를 사용할 때 반드시 Learning Rate를 증가시켜야 하는 것은 아니다. Weight Decay의 목적은 단순히 가중치를 줄이는 것이 아니라, 작은 norm을 갖는 해를 선호하도록 최적화 문제 자체를 변경하는 데 있다.
즉 Weight Decay는 \[\min_\theta \mathcal{L}(\theta)\]
를 푸는 것이 아니라, \[\min_\theta \mathcal{L}(\theta) + \lambda R(\theta)\]
를 푸는 것이다.
따라서 Weight Decay로 인해 가중치와 gradient가 일부 감소하더라도, 이는 새로운 목적함수에서 의도된 효과로 볼 수 있다. 만약 이를 보상하기 위해 Learning Rate를 과도하게 증가시키면 최적화가 불안정해지거나 Weight Decay가 의도한 정규화 효과가 약화될 수 있다.
결과적으로 Learning Rate와 Weight Decay는 서로 영향을 주기는 하지만, 일반적으로는 서로 다른 역할을 수행하는 하이퍼파라미터로 취급한다. Learning Rate는 최적화 속도와 안정성을 조절하고, Weight Decay는 모델의 복잡도와 일반화 성능을 제어한다.
9. Weight Decay는 어떤 경우 효과적일까?
Weight Decay의 효과를 가장 명확하게 이해할 수 있는 경우는 선형 회귀 문제이다. 특히 Ridge Regression은 Weight Decay가 어떤 방향의 불안정성을 억제하는지를 직접적으로 보여준다.
우리는 입력 $X$와 출력 $y$가 주어진 선형 모델을 다음과 같이 가정한다. \[y = Xw\]
이때 기본적인 학습 목표는 예측 오차를 최소화하는 것이다. \[\mathcal{L}(w) = \|Xw - y\|_2^2\]
여기에 Weight Decay를 적용하면 다음과 같은 Ridge Regression 문제가 된다. \[\mathcal{L}_{\text{Ridge}}(w) = \|Xw - y\|_2^2 + \lambda_{\text{Ridge}} \|w\|_2^2\]
이제 우리는 이 목적 함수를 최소화하는 최적의 해 $w^*$를 찾고자 한다. \[\arg\min_w \mathcal{L}_{\text{Ridge}}(w)\]
이를 $w$에 대해 미분하고 0으로 두면 다음의 최적 조건을 얻는다. \[(X^TX + \lambda_{\text{Ridge}} I)w = X^T y\]
따라서 closed-form solution은 다음과 같다. \[w^* = (X^TX + \lambda_{\text{Ridge}} I)^{-1} X^T y\]
이제 이 해를 해석하기 위해 $X$를 SVD로 분해한다. \[X = U \Sigma V^T\]
이를 이용하면 Ridge Regression의 해는 다음과 같이 표현된다. \[w^* = V \operatorname{diag} \left( \frac{\sigma_i}{\sigma_i^2 + \lambda_{\text{Ridge}}} \right) U^T y\]
반면 정규화가 없는 Ordinary Least Squares(OLS)는 다음과 같다. \[w_{\text{OLS}} = V \operatorname{diag} \left( \frac{1}{\sigma_i} \right) U^T y\]
이제 두 결과의 차이를 singular value 관점에서 해석할 수 있다.
OLS에서는 $\sigma_i$가 작은 방향에서 $\frac{1}{\sigma_i}$가 매우 커지면서 해당 성분이 과도하게 증폭된다. 이는 데이터가 그 방향을 충분히 관측하지 못했음을 의미하며, 결과적으로 노이즈에 매우 민감한 추정이 된다.
반면 Ridge Regression에서는 각 방향의 scaling이 다음과 같이 제한된다. \[\frac{\sigma_i}{\sigma_i^2 + \lambda_{\text{Ridge}}}\]
따라서 $\sigma_i$가 매우 작은 경우에도 해당 값은 $\lambda_{\text{Ridge}}$에 의해 bounded되며, 과도한 증폭이 발생하지 않는다.
즉 Weight Decay는 데이터가 충분히 관측되지 않은 방향, 즉 작은 singular value에 해당하는 방향의 영향을 억제한다. 이러한 방향은 일반적으로 불안정하고 노이즈에 매우 민감하기 때문에, Weight Decay는 결과적으로 더 안정적인 해를 유도한다.
Weight Decay가 효과적으로 작동하는 상황을 이해하기 위해, 다음 다섯 가지 경우를 중심으로 그 영향을 살펴본다.
- 데이터 샘플의 개수가 충분하지 않은 경우
- 데이터 행렬의 rank보다 더 큰 표현력을 갖는 모델을 사용하는 경우
- 훈련 데이터에서는 관측되지 않았지만 테스트 시점에서 나타나는 경우
- 입력에 노이즈가 추가되는 경우 ($x + \epsilon_x$)
- 출력에 노이즈가 추가되는 경우 ($y + \epsilon_y$)
9.1 데이터 샘플이 전체 입력 공간을 충분히 표현하지 못하는 경우
데이터 샘플이 전체 입력 공간을 충분히 span하지 못하는 경우를 고려할 수 있다. 이는 전체 입력 공간의 차원이 $d$일 때, 실제 훈련 데이터 $X_s$가 일부 방향의 정보를 충분히 포함하지 못하는 상황을 의미한다.
이러한 상황은 다음과 같이 표현할 수 있다. \[\mathrm{rank}(X) = d\] \[\mathrm{rank}(X_s) < d\]
이 경우 모델은 특정 singular vector 방향에 대한 정보를 충분히 학습하지 못하게 되며, 해당 방향으로 정렬된 입력이 테스트 시 등장하면 일반화 성능이 저하될 수 있다.
그러나 실제 데이터에서는 입력에 노이즈가 포함되기 때문에 $X_s$는 수학적으로 full rank가 되는 경우가 많다. 다만 이 경우의 rank는 실제 정보 차원을 의미하기보다는 매우 작은 singular value를 포함하는 effective rank로 해석하는 것이 더 적절하다.
이러한 작은 singular value 방향은 데이터가 충분히 관측하지 못한 방향으로 해석할 수 있다. Weight Decay는 이러한 방향에서의 파라미터 영향을 줄여 모델이 더 안정적인 해를 갖도록 유도한다.
9.2 데이터의 rank보다 더 큰 표현력을 갖는 모델을 사용하는 경우
모델의 파라미터 수가 데이터가 제공하는 정보 차원보다 큰 경우를 고려할 수 있다. 이 경우 서로 다른 파라미터가 동일한 training loss를 만들 수 있는 여러 해가 존재하게 된다.
특히 선형 모델에서는 해가 다음과 같이 표현될 수 있다. \[\theta = \theta^* + \mathrm{Null}(X)\]
이때 null space 방향의 성분은 training data에 의해 결정되지 않기 때문에, 무수히 많은 해가 존재할 수 있다.
Weight Decay는 이러한 해들 중에서 L2 norm이 작은 해를 선호하도록 작동한다. 따라서 null space 성분이 억제되고 보다 단순한 해가 선택된다.
9.3 훈련 데이터에서 보지 못한 테스트 입력이 등장하는 경우
딥러닝 모델이 선형 변환을 포함하는 경우, 입력의 작은 변화는 출력에 선형적으로 전달된다.
이러한 모델은 다음과 같이 표현된다. \[\hat{y} = W \hat{x} + b\]
테스트 입력이 훈련 데이터와 약간 다르게 주어지는 경우를 고려하자. 즉 입력이 다음과 같이 perturbation을 포함한다고 가정한다. \[\hat{x} = x + \epsilon\]
이 경우 출력은 다음과 같이 변하게 된다. \[\hat{y} = W x + W \epsilon + b\]
따라서 출력 오차는 $W \epsilon$에 의해 결정된다. Weight Decay는 $W$의 크기를 제한함으로써 이러한 입력 perturbation이 출력으로 과도하게 전달되는 것을 줄인다.
결과적으로 Weight Decay는 입력 변화에 대한 모델의 민감도를 감소시켜 보다 안정적인 예측을 유도한다.
9.4 입력에 노이즈가 추가된 경우
입력에 노이즈가 추가되는 경우도 동일한 방식으로 해석할 수 있다.
입력이 다음과 같이 주어진다고 가정한다. \[\hat{x} = x + \epsilon_x\]
이때 출력은 다음과 같이 표현된다. \[\hat{y} = W(x + \epsilon_x) + b\]
이를 전개하면 다음과 같이 분해된다. \[\hat{y} = Wx + W\epsilon_x + b\]
따라서 입력 노이즈 $\epsilon_x$는 weight matrix $W$를 통해 출력으로 전달된다. Weight Decay는 $W$의 크기를 제한함으로써 이러한 noise amplification을 줄인다.
9.5 출력에 노이즈가 추가된 경우
출력에 노이즈가 추가된 경우를 고려하자.
출력이 다음과 같이 생성된다고 가정한다. \[y = Xw + \epsilon_y\]
이때 Ridge Regression의 해는 다음과 같다. \[w^* = (X^TX + \lambda I)^{-1} X^T y\]
이 해를 Singular Value Decomposition을 이용해 해석하면 다음과 같이 표현된다. \[X = U \Sigma V^T\]
따라서 Ridge Regression의 해는 다음과 같이 쓸 수 있다. \[w^* = V \operatorname{diag} \left( \frac{\sigma_i}{\sigma_i^2 + \lambda} \right) U^T (y + \epsilon_y)\]
이때 작은 singular value 방향에서는 scaling factor가 제한되기 때문에 noise가 과도하게 증폭되는 현상이 억제된다.
결과적으로 Weight Decay는 출력 노이즈가 모델 파라미터 공간으로 전달되는 과정에서 특정 방향으로의 과도한 증폭을 줄여 보다 안정적인 추정을 가능하게 한다.
