Universal Approximation Theorem
in projects on Uav, Deeplearning, MachineLearning
딥러닝 모델은 이미지 분류, 음성 인식, 자연어 처리와 같은 다양한 문제에서 뛰어난 성능을 보여준다. 그렇다면 신경망은 어떻게 이렇게 복잡한 문제들을 해결할 수 있을까? 가장 단순한 형태의 신경망은 입력 벡터 에 대해 선형 변환을 수행한다. 하지만 선형 함수만으로는 XOR 문제조차 해결할 수 없으며, 현실 세계의 복잡한 데이터 관계를 표현하기에는 한계가 있다. 이를 해결하기 위해 신경망은 Sigmoid, ReLU 와 같은 활성화 함수를 사용하여 비선형성을 추가한다. 놀랍게도 이러한 비선형 활성화 함수와 충분한 수의 뉴런만 있다면, 신경망은 우리가 원하는 거의 모든 함수를 원하는 정확도로 근사할 수 있다. 이 사실을 보장하는 이론이 바로 Universal Approximation Theorem (UAT) 이다. 이번 글에서는 간단한 XOR 예제부터 시작하여, 활성화 함수가 어떻게 Rectangular Function을 만들고, 이를 조합하여 복잡한 함수를 근사할 수 있는지 직관적으로 살펴본다.
딥러닝 모델을 학습하는 것은 우리가 모은 학습 데이터 $(x,y)$ 쌍에 대해 $y \cong f_\theta(x)$ 가 성립하도록 함수 $f_\theta(x)$ 의 가중치 $\theta$ 를 찾는 과정이다. \[\min_{\theta} \mathcal{L}(f_\theta(\mathbf{x}),\mathbf{y})\]
모델 $f_\theta(x)$ 는 여러 레이어의 선형 변환 $ \hat{\mathbf{x}} = W\mathbf{x}+\mathbf{b} $ 을 겹겹이 쌓은 형태로 구성된다. 만약 선형 변환만 사용한다면 여러 레이어를 쌓더라도 결국 하나의 선형 변환과 동일하다. \[W_2(W_1\mathbf{x}+\mathbf{b}_1)+\mathbf{b}_2 = (W_2W_1)\mathbf{x}+(W_2\mathbf{b}_1+\mathbf{b}_2)\]
따라서 선형 함수만으로는 복잡한 비선형 관계를 표현할 수 없다. 이 문제를 해결하기 위해 Sigmoid, ReLU 와 같은 활성화 함수(activation function)를 각 레이어 사이에 삽입한다. 활성화 함수가 추가되면 모델은 비선형 함수를 표현할 수 있게 된다. 예를 들어 XOR 함수를 생각해보자.
| $x_1$ | $x_2$ | XOR |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
XOR 는 선형 분리가 불가능하므로 선형 모델만으로는 표현할 수 없다. 하지만 ReLU 활성화를 사용하면 다음과 같이 표현할 수 있따. \[\text{XOR}(x_1,x_2) = \text{ReLU}(x_1-x_2) + \text{ReLU}(x_2-x_1)\]
이를 2-layer 신경망 형태로 작성하면 다음과 같다.
1번째 레이어 (Hidden Layer)
\[\hat{\mathbf{x}} = W_1\mathbf{x} ,\qquad W_1= \begin{bmatrix} 1 & -1\\ -1 & 1 \end{bmatrix}\]활성화 함수
\[\tilde{\mathbf{x}} = \text{ReLU}(\hat{\mathbf{x}})\]2번째 레이어 (Output Layer)
\[y = W_2\tilde{\mathbf{x}} ,\qquad W_2= \begin{bmatrix} 1 & 1 \end{bmatrix}\]이처럼 활성화 함수를 사용하면 선형 모델로는 표현할 수 없는 함수를 표현할 수 있다.
Universal Approximation Theorem
XOR 예제는 활성화 함수가 선형 모델의 한계를 극복할 수 있음을 보여준다.
더 일반적으로 Universal Approximation Theorem(UAT)은 적절한 활성화 함수를 사용하는 신경망이 충분히 많은 뉴런을 가질 경우 임의의 연속 함수를 원하는 정확도로 근사할 수 있음을 보장한다.
예를 들어 1-hidden-layer 신경망이 있다고 하자. \[f_\theta(x) = W_2 \sigma(W_1\mathbf{x}+\mathbf{b}_1)\]
충분히 많은 hidden neuron 을 사용하면 $f_\theta(\mathbf{x})$ 는 대부분의 연속 함수를 원하는 정확도로 근사할 수 있다. 그렇다면 왜 이런 일이 가능할까?
직관적으로는 활성화 함수를 조합하여 작은 구간 함수(rectangular function)를 만들 수 있고, 이러한 함수들을 많이 쌓으면 복잡한 함수를 근사할 수 있기 때문이다.
Sigmoid로 Rectangular Function 만들기
Sigmoid 함수 $\sigma(x)$ 를 생각해보자. \[\sigma(x) = \frac{1}{1+e^{-x}}\]
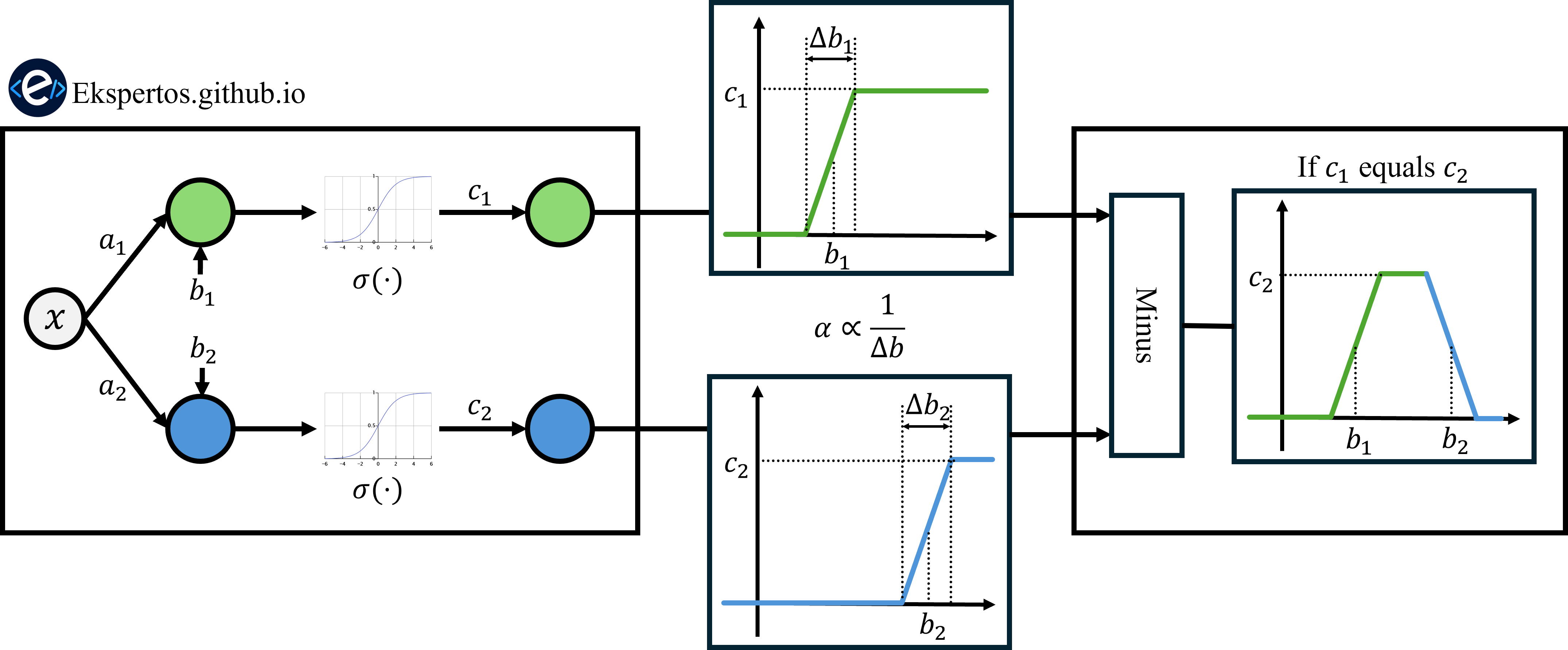
기울기 $b$ 를 크게 하면 아래와 같이 Unit Step Function 을 근사할 수 있다. \[u(x-a) = \lim_{b\to\infty} \sigma(b(x-a))\]
그리고 이런 Unit Step Function 두개를 사용하면 $a_1$ 과 $a_2$ 사이에서만 값이 $c$ 인 Rectangular Function 을 만들 수 있다. \[\text{rect}(x;a_1,a_2,c) = c\,u(x-a_1) - c\,u(x-a_2)\]
이때 $b$ 가 커질수록 더욱 직사각형에 가까워진다.
ReLU로 Rectangular Function 만들기
ReLU 함수 를 사용해도 비슷한 구조를 만들 수 있다. \[\sigma_{\text{ReLU}}(x) = \max(0,x)\]
먼저 아래와 같이 Unit Step Function 을 만들 수 있다. \[u(x-a) = \lim_{\epsilon\to0} \frac{ \sigma_{\text{ReLU}}(x-a+\epsilon) - \sigma_{\text{ReLU}}(x-a) } {\epsilon}\]
그리고 동일한 과정을 통해 Unit Step function을 구성할 수 있다. \[\text{rect}(x;a_1,a_2,c) = c\,u(x-a_1) - c\,u(x-a_2)\]
Sigmoid 의 경우 Rectangular Function 하나를 만드는 데 2개의 뉴런이 필요하지만, ReLU 의 경우 Step Function 을 먼저 구성해야 하므로 더 많은 뉴런이 필요하다는 것을 볼 수 있다.
함수를 근사하는 방법
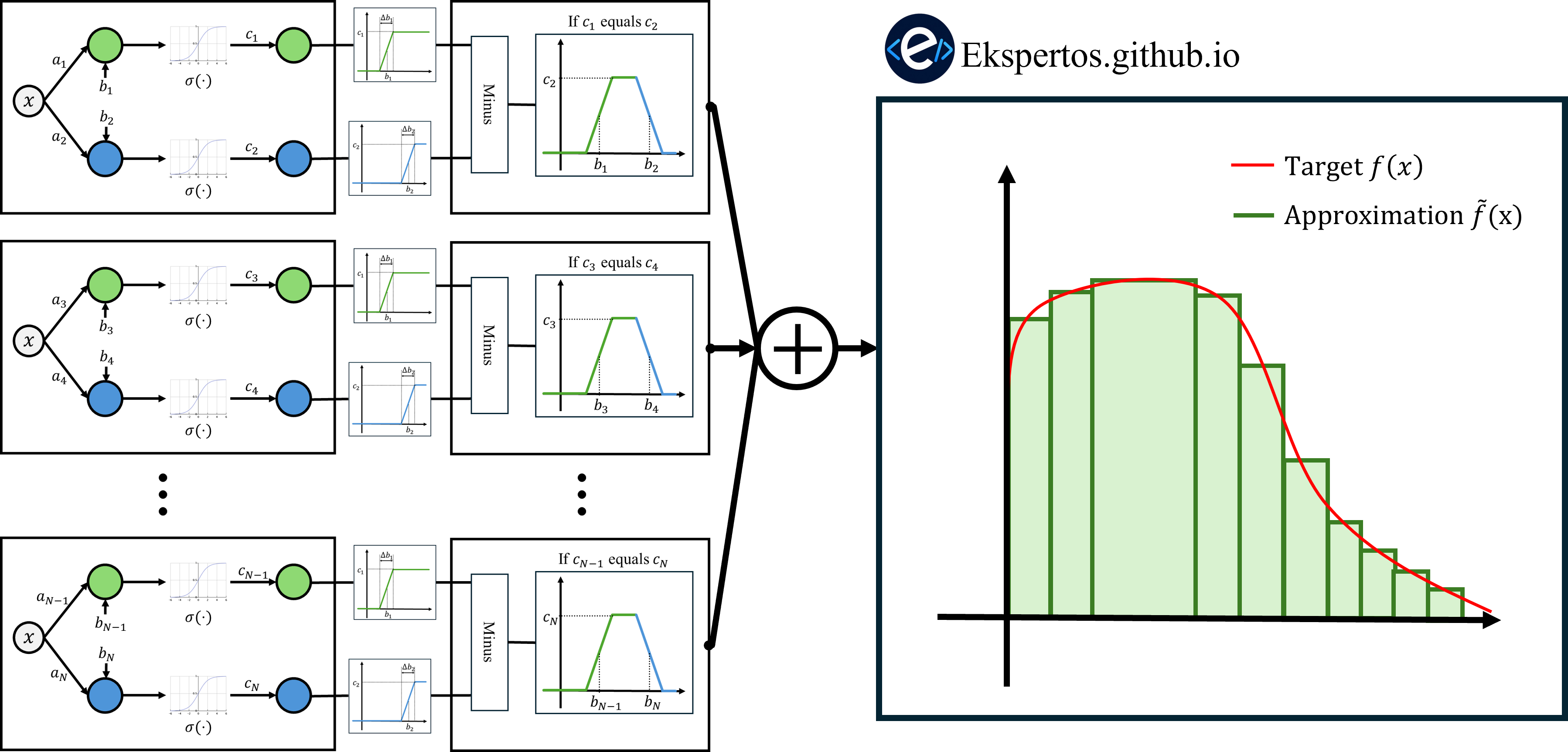
위에서 구한 Rectangular Function 을 여러 개 배치하면 Piecewise Constant Function 을 만들 수 있다.
그리고 Rectangular Function 의 개수를 늘릴수록 원하는 함수에 더욱 가까워진다.
아래는 이러한 방식으로 $sin(x)$ 와 $sin(x)+cos(3x)$ 를 근사한 예시이다.
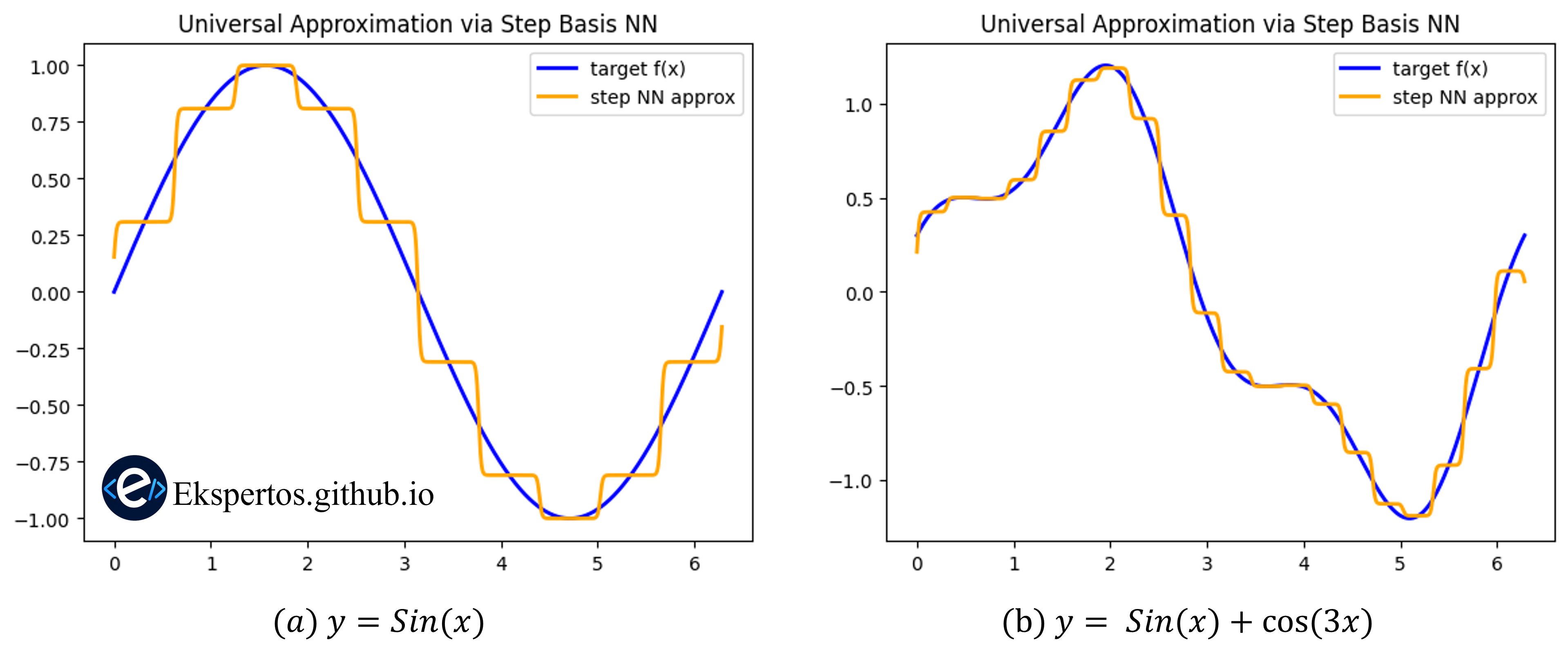
이것이 Universal Approximation Theorem 의 핵심 직관이다. 활성화 함수로 구성된 뉴런들을 충분히 많이 사용하면 복잡한 함수도 원하는 정확도로 근사할 수 있다.
UAT 관점에서 unit function을 만들기 위해 큰 b를 사용하면 saturation 문제가 더욱 심해진다. 이러한 saturation 특성은 sigmoid 계열 활성화 함수의 근본적인 단점이며, 깊은 신경망에서는 gradient vanishing을 유발할 수 있다. ReLU는 양수 영역에서 gradient가 유지되기 때문에 이러한 문제를 완화할 수 있어 현대 딥러닝에서 더 널리 사용된다.
검증을 해보자면, 아래는 시그모이드 활성화 함수를 사용한 모델로 $sin(x)$ 함수를 학습한 결과이다.
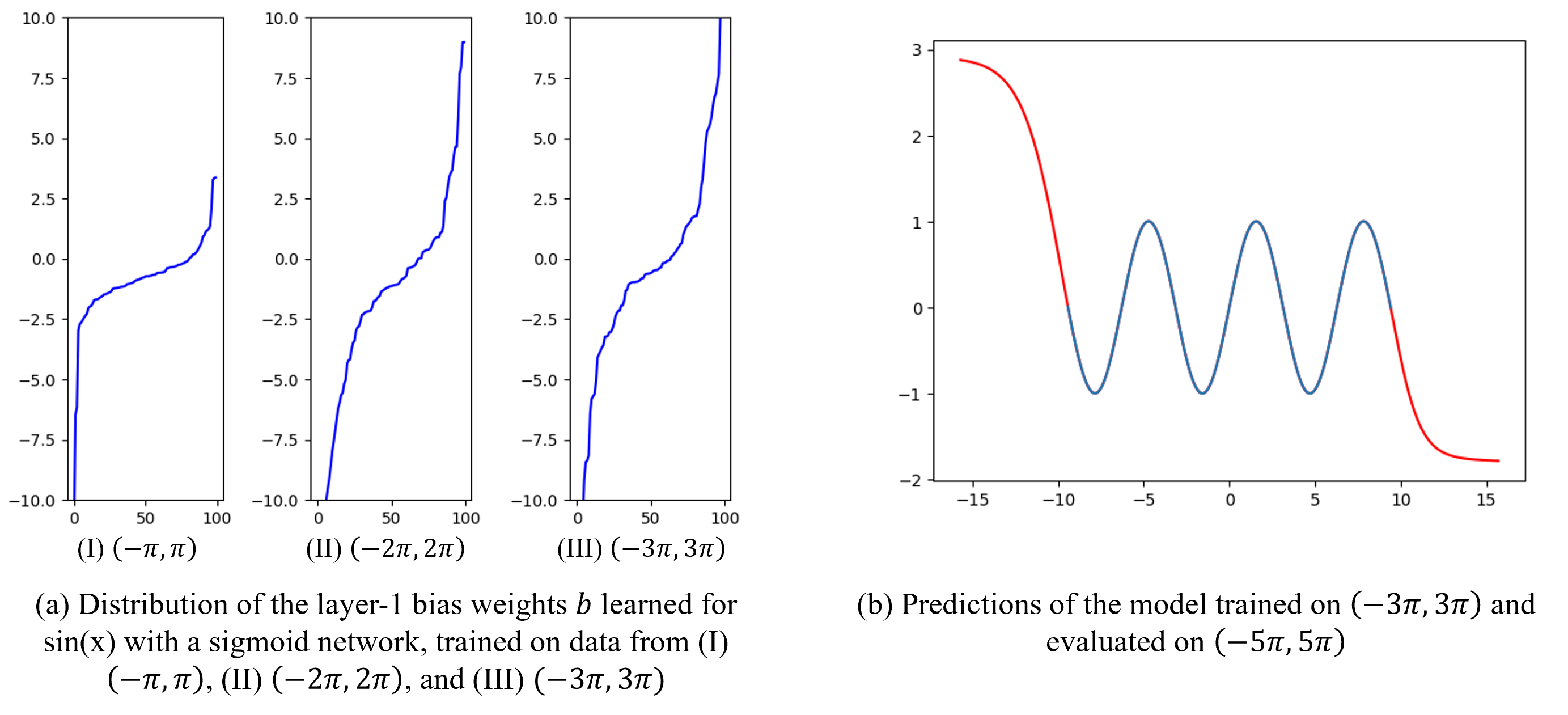
$(a)$는 각각 $\text{I. } (-\pi,\pi)$, $\text{II. } (-2\pi,2\pi)$, $\text{III. } (-3\pi,3\pi)$ 범위의 데이터로 학습된 모델의 첫 번째 레이어 bias $b$ 분포를 나타낸다. 입력 범위가 넓어질수록 bias 분포 역시 더 넓은 영역으로 확장되는 경향을 확인할 수 있다.
$(b)$는 $(-3\pi,3\pi)$ 범위의 데이터로 학습된 모델을 더 넓은 입력 구간에서 평가한 결과이다. 학습에 사용된 구간에서는 원래 함수를 잘 근사하지만, 학습 범위를 벗어나면 오차가 증가하는 것을 확인할 수 있다. 이는 sigmoid 뉴런의 transition point가 주로 학습 데이터가 존재하는 영역에 형성되기 때문이며, 그 결과 학습 범위 밖에서는 충분한 표현력을 제공하지 못하기 때문이다.
Q & A
Q1. $W$가 작다는 건 Universal Approximation 관점에서 unit step function을 완만하게 만든다는 말 아닌가? 그런데 Weight Decay는 $W$를 작게 만들어서 함수를 완만하게 만드는 것 아닌가? 그렇다면 여러 unit step function의 합으로 해석하는 것이 잘 맞지 않는 것 아닌가?
A1.
어느 정도는 맞는 해석이다. Sigmoid 활성화 함수를 사용할 경우 hidden unit은 \[\sigma(w^T x+b)\]
의 형태를 가지는데, $w$의 크기가 커질수록 sigmoid의 전이 구간이 좁아져 step function에 가까워진다. 반대로 $w$가 작아질수록 보다 완만한 형태의 함수를 표현하게 된다.
Weight Decay는 큰 weight에 패널티를 부여하므로 이러한 급격한 전이를 만드는 것을 억제하는 효과가 있다.
따라서 Weight Decay는 결과적으로 sharp한 basis function보다 상대적으로 smooth한 basis function을 선호하도록 만드는 inductive bias로 해석할 수 있다.
이는 고주파(high-frequency) 성분을 표현하는 능력을 어느 정도 희생하는 대신 보다 부드러운 함수를 선호하도록 만드는 효과와 연결된다.
다만 이것이 step-function 스타일의 표현을 사용할 수 없다는 뜻은 아니다.
예를 들어 \[\sum_{i=1}^{100} a_i \sigma(x-b_i)\]
와 같이 각 hidden unit이 비교적 완만한 sigmoid를 사용하더라도, bias를 적절히 배치하고 충분한 수의 hidden unit을 사용하면 상당히 복잡하거나 급격하게 변하는 함수도 근사할 수 있다.
보다 정확히 말하면 UAT는 네트워크의 표현력(expressivity)에 대한 결과이다. 반면 Weight Decay는 학습 과정에서 특정한 표현을 선호하도록 만드는 regularization 기법이다. 따라서 Weight Decay가 있다고 해서 UAT가 성립하지 않는 것은 아니다. 단지 동일한 함수를 표현할 수 있는 여러 해 가운데 상대적으로 작은 weight를 사용하는 해를 선호하게 된다.
실제로 sharp한 함수를 근사해야 하는 경우에는
- 일부 weight가 커질 수도 있고,
- hidden unit 수가 증가할 수도 있으며,
- 두 현상이 동시에 나타날 수도 있다.
즉 Weight Decay는 step-like 표현을 금지하는 것이 아니라, 그러한 표현의 비용을 증가시키는 역할을 한다고 이해하는 것이 적절하다.
Q2. 노이즈가 없는 입력으로 step 함수처럼 기울기가 큰 함수를 학습하면 $W$ 값이 매우 크게 나올까?
A2.
그럴 가능성이 높다. Step 함수에 가까운 급격한 변화를 표현하려면 hidden unit의 전이 구간이 매우 좁아져야 하며, sigmoid 계열 활성화 함수에서는 이를 위해 큰 weight가 필요한 경우가 많다. 예를 들어 $\sigma(wx+b)$ 에서 $w$가 커질수록 sigmoid는 점점 step function에 가까워진다.
다만 반드시 큰 weight만 사용하는 것은 아니다. 충분한 수의 hidden unit을 사용하면 여러 개의 완만한 unit을 조합하여 유사한 형태를 표현할 수도 있다. 또한 입력에 노이즈가 존재하는 경우에는 큰 weight가 입력의 작은 변화까지 증폭시킬 수 있으므로, Weight Decay나 Early Stopping과 같은 regularization 기법이 더욱 중요해진다.
Q3. UAT에 따르면 DNN만으로도 충분하지 않을까?
UAT에 따르면, 하나 이상의 비선형 활성화 함수를 가진 충분히 큰 신경망은 매우 넓은 범위의 함수를 원하는 정확도까지 근사할 수 있다. 그렇다면 DNN은 이미 충분한 표현력을 가진다는 말 아닌가?
그런데 실제 이미지 처리 문제에서는 여전히 CNN이 널리 사용된다. 이는 CNN의 표현력이 DNN보다 뛰어나서라기보다는 이미지 데이터에 적합한 inductive bias를 제공하기 때문이라고 볼 수 있다.
그렇다면 다음과 같은 생각을 해볼 수 있다. 만약 DNN의 표현력 자체에는 큰 문제가 없다면, CNN이 학습 과정에서 획득한 feature representation을 DNN에 전달하여 DNN이 더 쉽게 학습하도록 만들 수는 없을까? 즉 CNN의 inductive bias를 통해 얻은 지식을 DNN으로 전달하여 학습 효율을 높일 수는 없을까?
만약 이러한 접근이 가능하다면 학습 단계에서는 CNN의 inductive bias를 활용하고, 추론 단계에서는 상대적으로 단순한 DNN을 사용하여 더 빠른 inference를 수행할 수 있을 것처럼 보인다.
A3.
실제로 이와 유사한 아이디어는 오래전부터 연구되어 왔으며, 대표적인 예가 Knowledge Distillation이다. 예를 들어 CNN이 고양이와 강아지를 구분하는 문제를 학습했다고 하자. CNN은 단순히 “정답이 고양이이다”라는 정보만 학습하는 것이 아니라 귀 모양, 눈 주변 패턴, 털의 질감과 같은 다양한 특징을 내부적으로 학습한다.
이때 CNN을 teacher 모델로 사용하고 DNN을 student 모델로 두어 $ f_{\text{DNN}}(x) \approx f_{\text{CNN}}(x) $ 가 되도록 학습시키면 DNN은 정답 레이블뿐 아니라 CNN이 학습한 의사결정 경향까지 함께 전달받을 수 있다. 예를 들어 원래라면 DNN은 귀 모양이 중요한지, 눈 모양이 중요한지, 털의 질감이 중요한지를 스스로 탐색해야 한다. 반면 CNN이 이미 학습한 정보를 제공하면 이러한 탐색 과정을 일부 줄일 수 있다.
하지만 여기에는 중요한 한계가 있다. CNN의 강점은 단순히 좋은 feature를 학습했다는 점만이 아니다. CNN은 locality와 weight sharing을 이용하여 동일한 패턴이 이미지의 어느 위치에 나타나더라도 효율적으로 인식할 수 있다. 반면 일반적인 DNN은 입력을 하나의 긴 벡터로 취급한다. 따라서 CNN이 자연스럽게 활용하는 공간적 구조를 직접 학습해야 하며, 이를 위해 더 많은 파라미터와 데이터가 필요할 수 있다. 즉 CNN이 학습한 feature를 DNN에 전달하는 것은 가능하지만, CNN이 가진 inductive bias 자체를 완전히 전달하는 것은 쉽지 않다.
결국 문제는 표현력의 부족이 아니라 학습 효율성의 차이이다. DNN도 충분히 큰 규모라면 CNN이 학습한 함수를 근사할 수 있다. 그러나 CNN은 이미지에 적합한 inductive bias 덕분에 동일한 함수를 훨씬 적은 데이터와 파라미터로 효율적으로 학습할 수 있다. 그래서 실제 연구에서는 CNN을 완전히 DNN으로 대체하기보다는, CNN이 학습한 지식을 더 작은 모델로 압축하는 방향이 주로 연구되고 있다.
실습 코드
import numpy as np
import matplotlib.pyplot as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# -------------------------
# USER FUNCTION HERE
# -------------------------
def f_target(x):
return np.sin(x) + 0.3 * np.cos(3*x) # <- 바꿔도 됨
# domain
x = np.linspace(0, 2*np.pi, 2000).reshape(1, -1)
# resolution (basis size)
K = 20
sharp = 80
# interval boundaries
a = np.linspace(0, 2*np.pi, K, endpoint=False)
b = np.linspace(2*np.pi/K, 2*np.pi, K, endpoint=True)
mid = (a + b) / 2
# sample target function
w = f_target(mid)
# -------------------------
# Hidden layer: step detectors
# -------------------------
W1 = np.zeros((2*K, 1))
b1 = np.zeros((2*K, 1))
for i in range(K):
# left step
W1[2*i, 0] = sharp
b1[2*i, 0] = -sharp * a[i]
# right step
W1[2*i+1, 0] = sharp
b1[2*i+1, 0] = -sharp * b[i]
H = sigmoid(W1 @ x + b1) # (2K, N)
# -------------------------
# Output layer: linear combination
# -------------------------
W2 = np.zeros((1, 2*K))
for i in range(K):
W2[0, 2*i] = w[i]
W2[0, 2*i+1] = -w[i]
y = W2 @ H
y = y.flatten()
# true function
y_true = f_target(x.flatten())
# plot
plt.plot(x.flatten(), y_true, label="target f(x)", linewidth=2, color='blue')
plt.plot(x.flatten(), y, label="step NN approx", linewidth=2, color='orange')
plt.legend()
plt.title("Universal Approximation via Step Basis NN")
plt.show()
