Noisy Student Traning for ASR 논문 리뷰
in projects on Blog, Github, Pages, Jekyll, Spacy
서론
크기가 큰 딥러닝 모델에서 좋은 성능을 보이고 있는 Noisy Student Training 에 대해 알아본다.
Improving Noisy Sutdent Training for Automatic Speech Recognition을 리뷰해 볼 것이다. 논문을 바탕을 한 모델은 현재 LibriSpeech 벤치마크에서 현재(2022.05) 1위와 4위를 기록하고 있다.
이번 글에서는LibriSpeech Benchmark에서 4번째에 위치하고 있는 기법에 대해 알아본다. ImageNet에서 성능향상을 본 Noisy Student Training을 음성 모델에 사용해 SOTA를 기록한 기법이다.
포스트는 음성인식이 이미지 분류와 다른, 어떤한 기법들이 데이터 필터링과 밸런싱에 적용되는지에 주목한다.
Conformer + Wav2vec 2.0 + SpecAugment-based Noisy Student Training with Libri-Light은 모델을 NST 기법으로 훈련했을 뿐만 아니라 컨포머를 Wav2Vec의 훈련방식을 적용해 LibirSpeech에서 SOTA를 달성했다. Semi-supervised 방식과 self-supervised 방식을 같이 사용한 훈련방식이며 이와 관련된 Wav2vec 훈련방식은 추후 포스팅할 예정이다.
ImageNet에서의 NST 소개
라벨링 되지 않은 데이터는 라벨링이된 데이터보다 흔하게 볼 수 있으며 훨씬 많은 양을 차지한다. 라벨링된 데이터 뿐만 아니라 라벨링 되지 않은 데이터들을 모델 학습에 사용하는 방법은 NST 논문이 제시될 당시 이미지 분류에서 SOTA를 달성하였다.
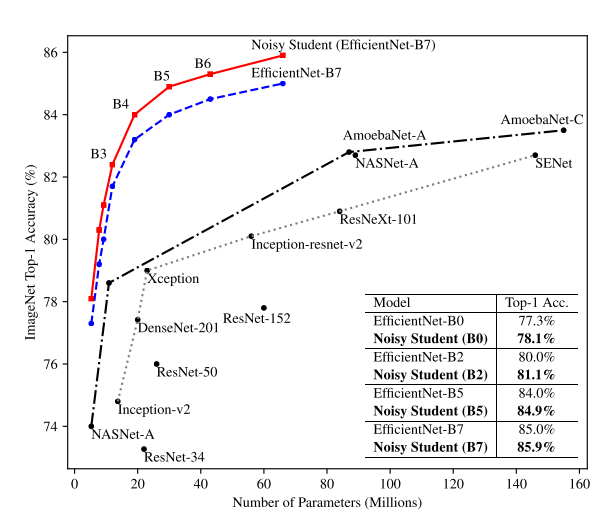
NST는 self-training과 distillation을 확장시킨 학습 방식으로 풍부한 양의 이미지로 학습되면서 노이즈에 강한 모델을 만드는 것을 목표로 한다.
Used Dataset
음성인식에서 NST의 효과를 입증하기 위해 두가지 실험을 진행한다.
- LibriSpeech-LibriLight ( Librispeech 데이터 기반 모델 성능 향상 )
| Type | Dataset | Size |
|---|---|---|
| Labeled | Librispeech Datset | 970h |
| Unlabeled | LibriLight-60k Dataset | 50000h |
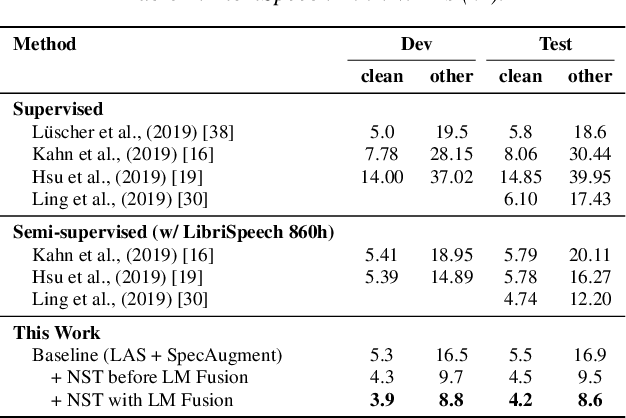
기존 1.9/4.1% 을 1.7/3.4% 로 모델 성능을 향상
- LibriSpeech 100-860 ( 제한된 데이터 기반 모델 성능 향상 )
| Type | Dataset | Size |
|---|---|---|
| Labeled | Librpseech Datset | 100h |
| Unlabeled | Librpseech Dataset | 870h |
기존 4.7/12.2% 을 4.2/8.6% 로 모델 성능을 향상
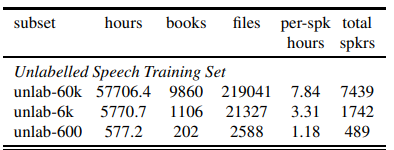
LibriLight Dataset
NST 학습과정
학습과정은 논문에서 1페이지만 차지하는 것으로 불 수 있듯이 그렇게 복잡하지 않다.
- Labeled 이미지로 Teacher 모델 학습
- Unlabeled 이미지에 대한 Pseudo-Label 생성 (Hard or Soft)
- Data Filtering & Balancing 으로 Pseudo-Label 가공
Data Filtering과정, Confidence 높은 라벨들 필터링하여 사용Balancing과정, Psudo-Label과 Label의 클래스 별 분포도가 같도록 수정
- Labeled 데이터와 Pseudo-Label 데이터로 모델 학습
- Noise를 추가해 Student 모델 학습
- Student 모델을 Teacher 모델로 하여 2-5 과정 반복
본 논문은 하드 라벨로 인공 라벨을 추출해 다음 모델 학습에 사용한다.
Data Filtering & Balancing
모델이 예측하는 클래스에 대한 정확도가 음성 인식 모델에서 적용될 수 있는 데이터 필터링과 데이터 밸런싱 기법을 제시한다.
Data Filtering
이전 세대 모델에서 출력되는 인공 라벨로 다음 세대의 모델이 훈련된다. 모델이 완벽하지 않은 만큼 인공적으로 생성된 라벨 또한 완벽하지 않으며, 이상한 라벨들을 필터링 해줄 필요가 있다.
이미지 분류는 소프트맥스 함수에서 출력된 예측 확률을 사용해 불량 라벨들을 필터링 해주지만 음성인식에서는 예측된 텍스트의 길이가 고정되어 있지 않기 때문에 동일한 기법의 필터링이 불가능하다.
텍스트가 선택될 확률로 라벨들을 필터링한다면 길이가 긴 라벨들은 모두 필터링되어 없어질 것이며, 그렇다고 예측될 확률을 라벨의 길이로 나누어 준다면, 짧은 라벨들이 모두 필터링되어 없어질 것 이다.
논문에서는 이러한 문제점을 해결해기 위해 예측된 라벨의 길이에 따라 예측 확률을 달리하여 필터링 한다.
즉, 비슷한 길이의 라벨들을 묶어서 상대적으로 예측 확률이 작은 라벨들을 필터링 한다.
라벨의 길이에 비해 상대적으로 더 정확하게 예측된 라벨을 구분해 주기 위해 로그 확률(log probability) S와 리벨의 길이 l을 파라미터로 하는 선형 회귀(linear regression) 모델을 훈련한다. \[s(S,l) = (S - \mu l - \beta) / (\sigma \sqrt{l})\]
같은 길이의 라벨들이 갖는 평균 로그 확률에 비해 컷오프 보다 높은 라벨들만 선택해 다음 모델 훈련에 사용한다. \[s(S,l) > s_{cutoff}\]
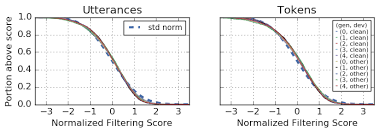
선형회귀 모델은 dev 데이터로 학습되며, 필터링이 제대로 되는지 확인하기 위해 dev 데이터에 대해서 컷오프를 달리하여 라벨의 WER을 측정한 결과를 제시한다.
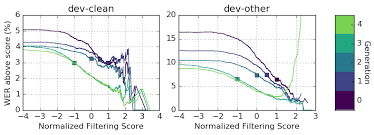
첫번 째 모델에서 $ s > 1 $ 의 라벨은 필터링되지 않은 라벨보다 약 10% 높은 WER 을 보임으로써 필터링 점수가 클 수록 더 정확한 레이블임을 알 수 있다.
LibriSpeech 100-860에 대해서는 위와 같이 필터링을 달리하면 엄청난 차이를 보이지만.
첫 번째 모델에서 filtering score가 1이 넘는 라벨에 대해 WER이 1.5% 로 기존 3.0% 보다 1.5% 밖에 향상되지 않는다.
데이터 필터링에 대해 분포를 보면 다음과 같다.
Data Balancing
첫 번째 모델의 훈련에 사용된 라벨된 데이터셋과 토큰 분포를 같게 해주기 위해 데이터 밸런싱을 진행한다. Sub-modular 함수로 표현될 수 있으며 Submodular Optimization으로 밸런싱을 해준다.
모델 구조 및 학습방법
LibriSpeech-LibriLight
모델 구조
ContextNet 구조를 베이스로 하며, Iteration 이 진행될수록 더 큰 모델로 데이터셋이 학습된다.
ContextNet은 $\alpha$ 파라미터로 모델의 크기를 다양하게 조절 가능하다.
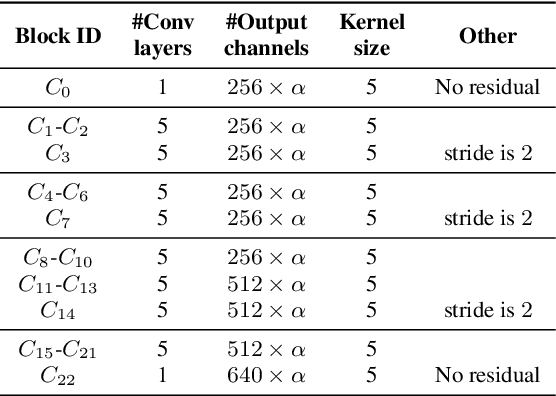 논문에서 Iteration 마다 사용한 모델 $ \alpha $는 다음과 같다.
논문에서 Iteration 마다 사용한 모델 $ \alpha $는 다음과 같다.0th 1st 2nd 3rd 4th Teacher 2 1.25 1.25 1.75 2.25 Student 1.25 1.25 1.75 2.25 2.5 노이즈
Adaptive SpecAugment 의 데이터 증진 기법을 사용한다. F=27, time mask ratio 0.05, time mask 10개
데이터 필터링
LibriSpeech 960h으로 학습된 베이스 모델의 성능이 나쁘지 않기 때문에 별도의 필터링을 사용하지 않는다
데이터 밸런싱
데이터 밸런싱을 사용한다
LibriSpeech 100-860
모델 구조
모든 Iteration에서
LAS-6-1280의 모델 구조를 사용한다.노이즈
0th 1st 2nd 3rd 4th 5th Time Mask (T) - 1 0.5 0 -1 -inf 데이터 필터링
필터링 컷오프를 다음과 같이 설정해 컷오프보다 낮은 라벨들을 필터링한다.
0th 1st 2nd 3rd 4th 5th cutoff - 1 0.5 0 -1 -inf Dev 데이터에 대한 필터링 분포를 보면 다음과 같다.
데이터 밸런싱 별도의 데이터 밸런싱을 사용하지 않는다
실험결과
Iteration에 따라 달라지는 WER은 다음과 같다.
각각의 방식에서 SOTA를 달성한다.
LibriSpeech-LibriLight
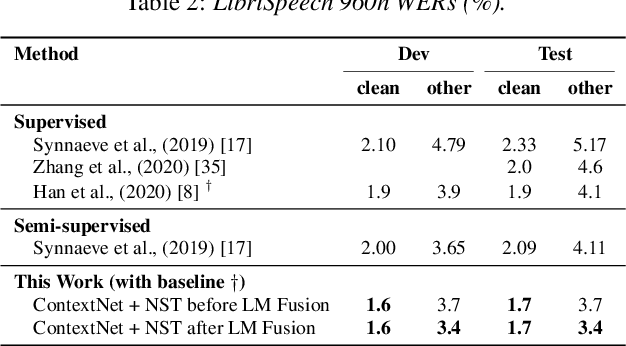
LibriSpeech 100-860