CLIP(Contrastive Language–Image Pre-training) 논문 리뷰
in projects on Blog, Github, Pages, Jekyll, Spacy
서론
OpenAI에서 최근(2021.2)에 Vision Language Transformer(VIT)로 CLIP 모델을 공개하였다.
같이 공개된 DALL:E(이미지 생성 모델)에 비해 큰 관심을 받지 못했지만, VIT 분야에 한정해서는 현재(2022.05) 1066회 인용되었으며 VIT에서 가장 영향력 있는 모델로 보여진다.
논문 링크: https://arxiv.org/abs/2103.00020
일반적인 이미지 분류 모델(ResNet, EfficientNet, etc.)은 이미지만을 보고 어떤 대상에 대한 사진인지 추론한다. 반면, CLIP은 이미지 정보 뿐만 아니라 관련된 텍스트 정보 를 입력으로 사용해 이미지 분류 작업을 수행한다.
CLIP은 이미지와 함께 There is a lot of [class]s in the photo의 템플릿을 모델 입력으로 사용하며, 텍스트 빈칸에 들어가기 가장 적합한 클래스를 예측하는 추론방식이다.
CLIP은 어떤 템플릿을 사용하는가에 따라서 모델의 성능이 달라지게 된다.
[class]This is a photo of [class]There is a lot of [class]s in the photo
3번째와 구체적인 템플릿을 사용하면 위의 그림에서는 더 좋은 성능을 보이겠지만, 사용할 수 있는 이미지의 범위가 한정되게 된다. 어떻게 보면 prompt engineering, 즉 템플릿을 어떻게 구성하는지가 CLIP을 사용하는데에 있어 매우 중요한 부분 중 하나이다.
CLIP의 핵심 내용은 다음과 같다.
훈련방식(Costrative-Loss)
서론에서 살펴본 것과 같이 CLIP 은 여러 문장들 가운데 이미지와 유사도가 높은 문장들을 순서대로 뽑아낸다. 즉, 제대로 추론되기 위해서, 이미지 를 인코딩한 결과와 이미지에 대한 설명 을 인코딩한 결과가 굉장히 유사해야 한다.
CLIP은 특별한 학습 방식, Constative Learning을 활용하여 위의 목적을 달성한다.
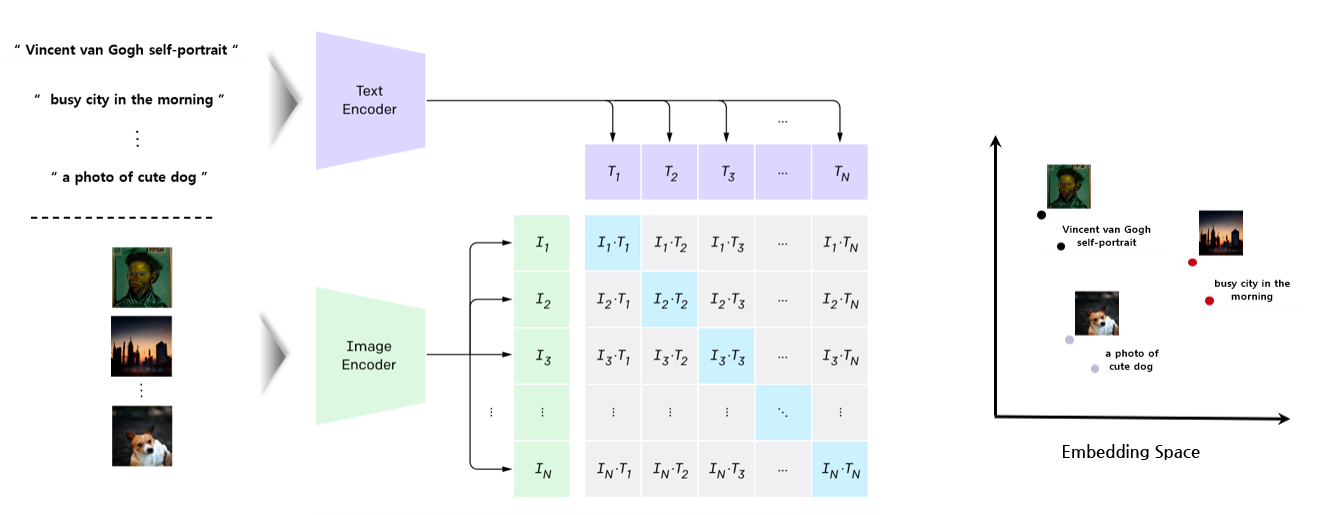
그림1과 텍스트1의 코사인 유사도를 높이면서, 그림1과 텍스트2, 텍스트3의 코사인 유사도를 낮추는 방식으로 모델이 학습된다. 각각의 그림과 텍스트를 같은 임베딩 스페이스에 매핑하는 것으로 생각할 수 있다.
추론방식(Zero-Shot)
그림이 매핑된 공간과 가장 유사하게 매핑된 텍스트를 선택하는 방식으로 추론이 진행된다.
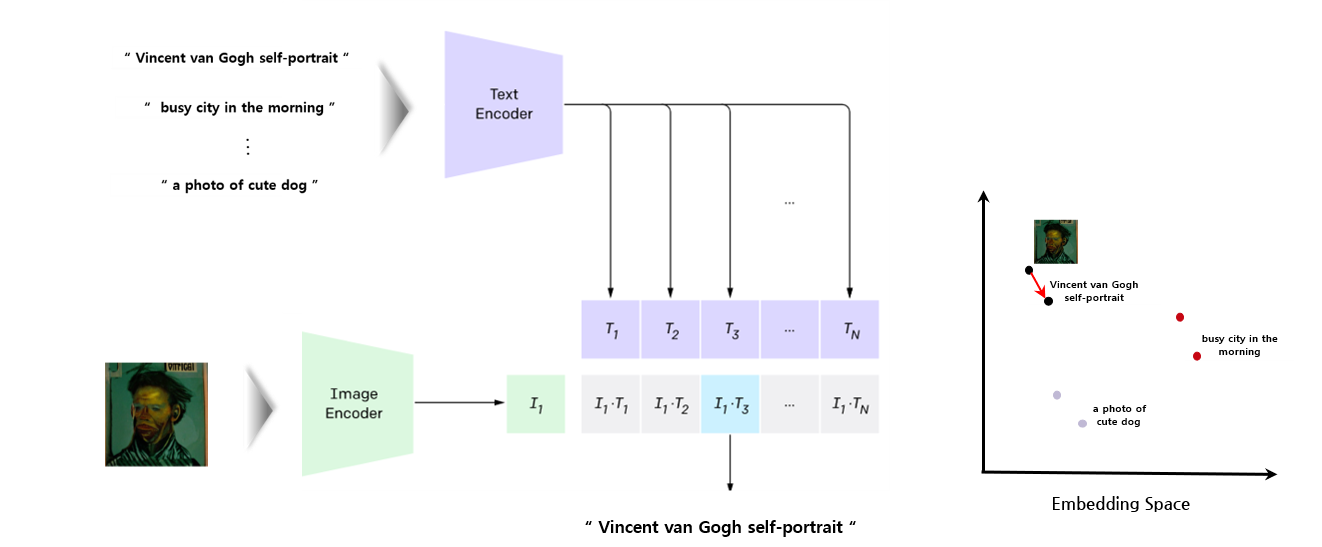
물론
이 과정에
N개의 클래스들 중에서 이미지에 대응되는 클래스를 찾기 위해서 CLIP 모델은 이미지 1개와
클래스 N개를 입력으로 사용해 확률분포를 추론한다.
이미지와 텍스트를 일일히 비교해서 유사할수록 더 큰 값으로 추론된다.
텍스트와 이미지 사이의 코사인 유사도(cosine similarity)를 사용해 확률분포를 추론한다.
텍스트 입력에 사용하는 템플릿에 따라 추론 결과가 달라지게 된다.
`6마리의 [] 사진이다` 라는 템플릿을 사용하면 더 좋은 추론을 할 것이라고 예상할 수 있다.
한번의 이미지 입력만으로 확률분포를 구하는 방식과 달리 CLIP은 n개 (이미지,텍스트) 쌍을 입력으로하여 확률분포를 추론한다.
CLIP은 일반적인 이미지 분류 모델들과 다르게 이미지와 텍스트를 모두 입력으로 사용해 이미지를 분류한다. 논문에서는 이미지 분류 모델 중 하나인 ResNet-50과의 비교를 통해 CLIP이 ResNet보다 이미지를 이해하는 능력이 뒤쳐지지 않음을 입증한다.
논문에서 이미지 분류 모델 중 하나인 ResNet-50과의 성능 비교를 통해 CLIP 성능을 보이기 위해 이미지 분류 모델들 중 하나인 ResNet-50 모델과 비교해 . 이미지의 특성을 파악한다는 점에서
이미지 하나의 입력에 대해서 이미지와 관련된 그게 무엇인지 확인하는 것이 아니라 이미지와 텍스트 사이의 유사성을 통해 이 그림이 어떤 텍스트와 가장 유사한지 확인하는 과정이다.
A Photo of a Dog
phrase에 따라서 더 좋은 결과가 나올 수 있다. “dog” “cat” 보다
“a photo of a cat” <-> “a photo of a cat” 을 비교하는게 더 좋을 수 있다
어떻게 보면 prompt engineering을 해야한다고 볼 수 있다.
[CLIP 논문에서 데이터셋 증진을 했음을 제시]
[CLIP 논문이 generalization이 잘 되어 있는지 검증하기 위해 그림 사용]
다음 그림은 CLIP 모델과 ResNet-50 모델의 성능을 비교한 그림이다. 파인튜닝이 되지 않은 CLIP 과 지도학습(Supervised Learing)된 ResNet-50 이 사용된 결과이다.
finetuning보다는 성능 면에서는 안좋을 것이지만 이미지를 Representation이 정확한지 확인 할 수 있다.
ImageNet에서 훈련된 ResNet-50을 새로운 태스크에 대해서 linear probing을 진행한다.
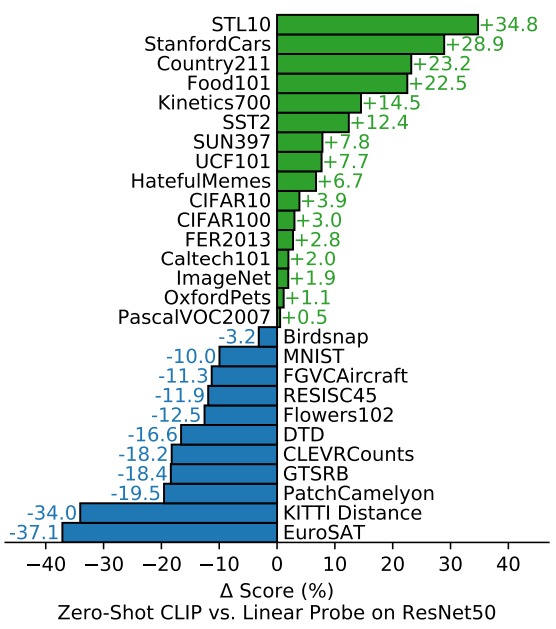
모델이 이미지에 대해 일반화(generalization)가 잘 되어 있는지를 눈문은 Zero-Shot CLIP 결과를 통해 검증한다.
ResNet 모델이 픽셀 정보만을 사용해 이미지 분류하는 것과 다르게, CLIP 모델은 픽셀 정보 뿐만 아니라 이미지와 연관된 텍스트 정보를 추가적으로 사용해 이미지 분류를 한다.

다음 그림을 보면 ‘a photo of [], a type of food’ 이라는 템플릿이 제시된 상태에서 분류하는 것이 예측다면 모델이 이미지를 분류하기 더 쉬울 것이라고 생각할 수 있다.
- 목차
- Label Smoothing 기법 소개
- Penultimate Layer Representations 시각화
- Model Calibration 효과
- Label Smoothing 구현
- Knowledge Distillation에서의 악영향
실제로 이미지와 텍스트가 어떻게 입력으로 사용되는지 알아보기 위한 강아지 사진 을 예시로 제공한다.
일반적인 이미지 분류 모델 입력 : 이미지 출력 : 개(70%), 늑대(10%), 고양이(5%), …
모델은 이미지에 대한 정보를 인코딩해 이 이미지가 어떤 클래스에 속하는지를 추론한다.
CLIP 모델 입력 : (이미지, “강아지”), (이미지, “늑대”), (이미지, “고양이”), … 출력 : 강아지(70%), 늑대(10%), 고양이(5%), …
모델은
이미지를 인코딩한 정보와텍스트를 인코딩한 정보를 비교해 어떤 텍스트가 이미지를 가장 잘 나타내는지 추론한다. “강아지”를 인코딩한 정보가 이미지를 인코딩한 정보와 가장 높은 유사도를 갖기 때문에 “강아지” 클래스에 소속된 사진임을 추론할 수 있다.
학습에 사용된 모델 ResNet-50 ResNet-101
Broader Impact CLIP allows people to design their own classifiers and removes the need for task-specific training data
CLIP 모델은 자신들만의 classifier들을 설계하는 것을 가능케 하고, Task-Specific 학습데이터 없이도 가능하게 한다
The manner in which these classes are designed can heavily influence both model performance and model biases.
클래스가 설계되는 방식이 모델의 성능과 모델 bias를 달리한다
Fiarface race labels : fairface 데이터셋 ( 인종에 대한 모든 라벨 )
Fiarface race labels과 함께 "criminal", "animal" 과 같이 터무니 없는 라벨들이 주어지는 경우
0-20 세의 터무니 없는 범주의 카테고리를 ~32.3%의 정확도로 예측한다.
그러나 "child" 있을 수 있는 클래스가 주어지면, 성능은 ~8.7%로 감소된다.
https://github.com/openai/CLIP/blob/main/model-card.md
Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is
thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment
demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with
different class taxonomies. This makes untested and unconstrained deployment of the model in any use case
currently potentially harmful.
unconstrainted : 제약이 가해지지 않은
우리가 적용하지 않은 예로 Image Search와 같은 경우
fixed class taxonomy로 철저하게 in-domain 테스팅이 되지 않는 한,
사용하는 것을 추천하지 않는다.
CLIP 논문
Learning Transferable Visual Models From Natural Language Supervision
8. Related Work
image-text retrieval
기존 image-text retrieval에서는 크라우드 소싱 sentence level image caption 데이터셋을 사용하였다.
pascal1K 
Flickr8K 
Flickr30K 
상대적으로 적은 수의 데이터 셋이기 때문에 학습될 수 있는 성능이 제한된다.
그래서 Im2text: Describing images using 1 million captioned photographs 에서는 자동으로 큰 데이터셋을 만들어준 방법을 제시한다.
딥러닝에서도 mithun et al. (2018) 의 인터넷에서 더 많은 (image, text) 쌍을 수집하는 것이 성능 향상에 도움이 된다고 제시하고,
Conceptual Caption, LAIT, OCR-CC 의 논문들이 자동으로 새로운 데이터셋을 만든느 방법을 제시한다.
하지만 이러한 데이터셋들은 여전히 훨씬 더 공격적인 필터링을 사용하거나 또는 OCR과 같은 특정한 작업을 위해 설계된다.
그래서 WIT 보다 더 적은 데이터 개수로 제한된다. (1~10M 학습데이터)
CLIP과 관련된 견해를 갖는 것은 webly supervised learning이다
CLIP과 관련된 아이디어로 Webly Supervised learning을 들 수 있다
image search engines to build image datasets by querying the terms and uses the queries as the labels for the returned images.
classifiers trained on these large but noisily labeled datasets can be competitive with those trained on smaller carefully labeld datasets.
CLIP은 이와 관련된 Search Query를 data 생성 과정에서 사용한다.
그러나 CLIP은 이미지를 검색하는데 사용한 query를 사용하는 것 보다 이미지와 함께 있는 full text sequence를 사용한다.
Learning Everything about Anything: Webly-Supervised Visual Concept Learning
niche(짖궂은) Task
noteworthy : 주목할 만한
- model bias : the amount that a model's prediction differs from the target value, compared to the training data
https://www.mastersindatascience.org/learning/difference-between-bias-and-variance/
bias error results from simplifying the assumptions used in a model so the target functions are easier to approximate.
bias can be introduced by model selection. Data scientists conduct resampling to repeat the model building and derive the
https://www.youtube.com/watch?v=EuBBz3bI-aA
bias and variance
weight에 따라 달라지는 height 값을 예측하고 싶다
difference in fits in dataset - variance
straight line : relatively high bias
relatively low variance
boosting
random forest
bagging
