KsponSpeech: Korean Spontaneous Speech Corpus for ASR
in projects / Jekyll on Blog, Github, Pages, Jekyll, Spacy
ETRI에서 공개한 한국어 음성 인식 관련 논문이다
AI 허브에서 공개한 한국어 대화 데이터(KsponSpeech) 데이터셋을 사용한다
[논문] KsponSpeech: Korean Spontaneous Speech Corpus for ASR
[Link] https://www.mdpi.com/2076-3417/10/19/6936
Introduction
논문은 AIHub에서 제공하는 969h 데이터셋을 이용한다. 대략 2000명이 녹음에 참여했으며 두명이 조용한 환경에서 하는 대화가 녹음되었다
논문은 RNN과 Transformer 모델을 비교한 후 다음 목록들에 대해 알아본다
- SpecAugment의 유효성(effectiveness)
- 적합한 한국어 sub-word 수
- large 모델 아키텍처의 유효성
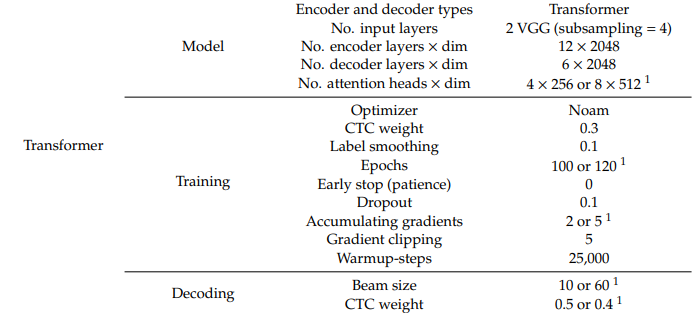
사용된 음성인식 모델은 다음과 같다
CTC/Attention Model
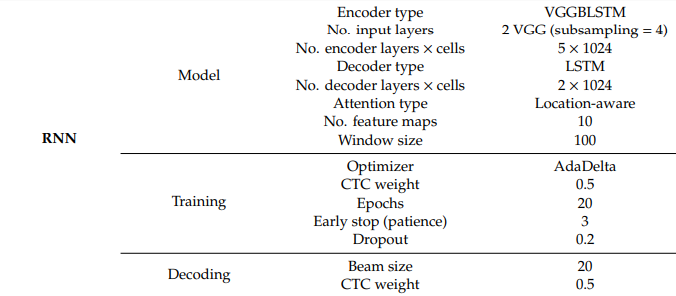
CTC/Transformer Model
KsponSpeech Corpus
ETRI에서 녹음된 대화를 이용해 진행한 post-preprocess 과정을 소개한다 긴 대화 파일을 여러 파일들로 분할한 방식을 설명하고 Dev, Train, eval-clean, eval-other을 어떤 방식으로 분할한지 설명한다.
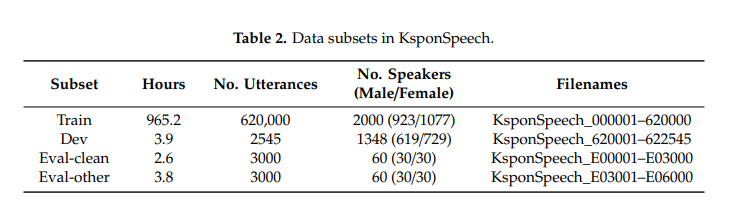
Dev 파일들은 end-to-end model에서 최적의 파라미터를 찾기 위해 사용된다. 학습 데이터셋으로 3-gram 언어모델을 구축한 후 speaker utterance perplexity 기준으로 eval과 other 데이터셋으로 분할한다.
- eval-clean : perplexity of
444 - eval- other : perplexity of
3106
perplexity 펄 플렉서 티(perplexity)는 언어 모델을 평가하기 위한 내부 평가 지표이다. 보통 줄여서 PPL이 라고 표현한다 .PPL은 선택할 수 있는 가능한 경우의 수를 의미하는 분기 계수(branching factor)이다. PPL은 언어 모델이 특정 시점에서 평균적으로 몇 개의 선택지를 가지고 고민하고 있는지를 의미한다. [https://settlelib.tistory.com/55]
Speech Recognition Result
80-차원 log-mel feature와 3-차원 pitch feature을 합해 83 차원 feature을 사용한다
3.2 Evaluation Metric
해당 논문은 한국어 대상 오류 측정 기법 “sWER(space-normalized WER)”을 제안한다. “한국어 맞춤법 규정에서 복합어 띄어쓰기는 상당히 복잡하고 모호한 문제이다.” 한국어는 다른 언어들과 달리 띄어쓰기 규칙에 모호한 부분이 많다. label 하는 과정에서 존재하는 이러한 모호함을 없애주기 위해 space-normalized WER을 사용한다.
hyp을 space-normalize 과정을 통해 reference와 띄어쓰기가 동일하게 되도록한 후 둘 사이의 WER을 계산한다


3.3 Comparision of RNN and Transformer Architectures
RNN과 Small-Transformer 모델을 비교한다. 두 모델 모두 2906개의 sub-word가 사용된다. 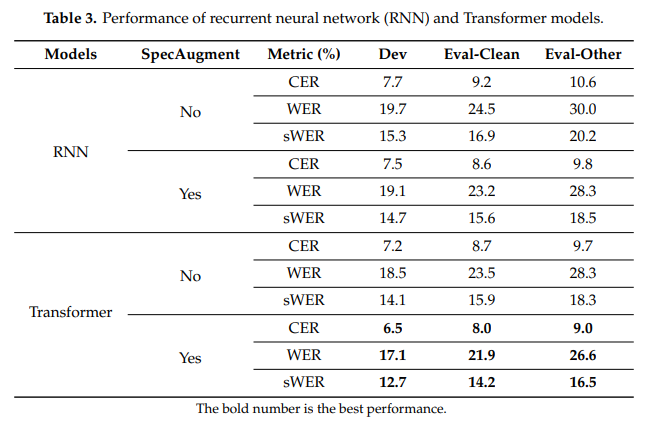 sWER을 이용해 띄어쓰기가 다른 두 문장을 같은 문장으로 처리함으로써 WER와의 큰 퍼포먼스 차이을 볼 수 있다. 따라서 한국어는 띄어쓰기가 중요한 문제로
sWER을 이용해 띄어쓰기가 다른 두 문장을 같은 문장으로 처리함으로써 WER와의 큰 퍼포먼스 차이을 볼 수 있다. 따라서 한국어는 띄어쓰기가 중요한 문제로 sWER이 WER 보다 한국어에 적합한 metric이라고 볼 수 있다.
3.4 Number of Sub-Word Units
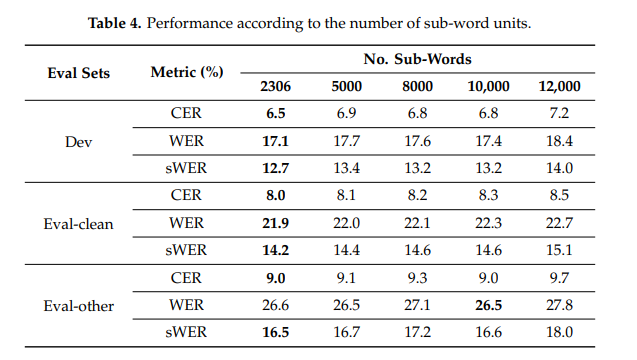
SPnet에서 기본 제공하는 unigram algoritm을 사용해 sub-word들을 만든다. 한국어와 동일하게 음절단위를 이용하는 관화(대만 지방의 방언)는 음절 단위의 학습이 sub-word 단위의 학습보다 더 좋은 성능을 보였다는 연구가 있다. 저자들은 다음에 이에 대한 실험을 진행할 것이라고 한다.
3.5 Size of Transformer Model
![]()
