RNN Transducer Review
in projects / Jekyll on Blog, Github, Pages, Jekyll, Spacy
서론
음성인식을 위해 알아야하는 Alignment 기법들, 그 중
RNN-T에 대해 알아보겠습니다. Alex Graves의 RNN-T 논문을 참고했습니다 (https://arxiv.org/pdf/1211.3711.pdf)
Alignment 란?

그림은 CTC Align 방식의 한 예로, 레이블 hello를 align하는 방법을 보여줍니다. 레이블은 5개의 알파벳으로 이루어졌을 뿐이지만 사람의 음성은 이것보다 복잡합니다. h를 길게 발음하는 사람, 짧게 발음하는 사람 등등 사람마다 발음에서 각각의 개성을 갖습니다. 또한 발음을 하는 중간중간 쉬는 구간의 길이, 위치 또한 다르게 분포합니다.
같은 레이블에 관한 발음이더라도 사람에 따라서 굉장히 다른 음성신호가 나올 수도 있는 것이지요 Alignment 방법들을 이용해 신경망이 사람의 발음, 쉬는 구간들을 학습할 수 있도록 할 수 있습니다.
예로 CTC align는 각각의 구간이 어떤 알파벳이 위치하는지 혹은 쉬는 구간인지 구분이 가능하도록 합니다. 쉬는 구간을 $\epsilon$ 으로 하여 hello의 입력신호를 he$\epsilon$ll$\epsilon$lloo 로 바꾸어 인식합니다.
1. 알파벳 h와 알파벳 e
2. 쉬는 구간 엡실론
3. 두 구간을 차지하는 알파벳 l
...
이번 글에서 소개할 RNN-T는 CTC, Attention 기법과 함께 음성인식에서 가장 흔히 사용되는 Alignment 기법입니다. 2012년에 작성된 논문 Sequence-Transduction-with-Recurrent-Neural-network을 바탕으로 글을 작성했으며, 해당 논문에서는 입력 시퀀스에서 출력 시퀀스로 변환되는 과정을 Transduction으로 정의합니다.
요약
왜곡에 상관없이 동일한 출력을 낼 수 있는가?는 시퀀스를 가공하는데에 있어 주요한 과제 중 하나입니다. 입력의 stretching, shrinking, translating과 상관없는 출력을 낼수 있어야 하지요.
이러한 시퀀스의 왜곡적인 특징들을 학습할 수 있다는 점에서 RNN은 Sequence Transduction에 많이 사용됩니다. 그러나 RNN을 시퀀스 가공에 사용하는데에는 굉장히 큰 제한적인 특징이 있습니다. 학습을 위해서는 입력과 출력 간 미리 정의된 Alignment 정보가 필요하다는 점입니다. Alignment를 찾는 것이 가장 힘들다는 점에서 RNN의 큰 단점이라고 할 수 있지요.
해당 논문은 Alignment 문제를 해결하기 위해서 RNN 기반의 end-to-end probabilistic sequence transduction system을 소개합니다. 어떠한 유한한 입력에도 고정된 출력으로 바꾸어 주도록 설계된 시스템입니다.
1. 들어가며
시퀀스를 우리가 원하는 방식으로 가공 시키는 것은 AI를 위해 필요한 가장 중요한 단계 중 하나입니다. 이 과정에서 직면한 가장 큰 문제는 시퀀스를 가공하는 것입니다. 시퀀스 왜곡에 영향을 받지 않거나 영향이 최소화 되도록 시퀀스 정보를 가공할 필요가 있습니다.
시퀀스 정보를 가공하기 위해 가장 좋은 구조는 RNN을 이용한 구조 입니다. 그러나 RNN을 사용하기 위해서는 입력과 출력간의 Alignment가 주어진 경우에만 사용될 수 있다는 큰 제한이 있습니다.
우리는 이 Alignment 정보를 구하기 위해서 두가지 확률 분포를 사용할 것입니다.
- 모든 출력 길이의 시퀀스에 대한 확률분포 출력 길이가 주어질 경우에는 그 길이에 맞는 시퀀스들 간의 확률분포를 시용하면 되지만 그렇지 않기 때문에 모든 길이의 시퀀스에 대한 확률분포가 필요합니다.
- 입력과 출력 사이의 가능한 모든 Alignment에 대한 확률분포 출력 시퀀스를 구했더라도 입력과 출력간의 Alignment 정보를 구하기 위해서 가능한 모든 alignment에 대한 확률분포가 필요합니다.
해당 논문에서 사용하는 모델은 기존에 사용되던 Conntectionist Temporal Classification(CTC) 모델의 두가지 단점을 보완했습니다.
- 입력보다 긴 출력 길이를 가질 수 있습니다
- input-input, output-output의 상호의존성을 포함하며 이를 엮어서 만든 모델입니다
CTC의 경우에는 출력의 길이가 입력보다 긴 TEXT-TO-SPEECH의 경우를 배제하며 출력 시퀀스 간의 상호의존 정보를 사용하지 못합니다.
2. Recurrent Neural Network Transducer
\(x = (x_1, x_2,...,x_T), y = (y_1, y_2,...,y_U)\) T개의 음성신호를 갖는 $x$, 그에 대응하는 U개의 label 정보를 가지는 $y$를 사용합니다.
각각의 $x_t$와 $y_u$는 고정된 크기의 백터로 표현됩니다. $x_t$의 경우에는 mel-spectrogram로 표현된 백터, $y_t$의 경우에는 각각의 레이블을 인코딩한 one-hot-vector일 것입니다.
$\bar{y} = y \cup \varnothing$ 이라는 extended output space도 정의해줄 것입니다. $\bar{y} \in (y_1, \varnothing, \varnothing, y_2, \varnothing,…,y_U)$ 로 표현될 수 있습니다. 음성 $x$와 레이블 $y$간의 가능한 모든 Alignment들이 $\bar{y}$에 표현되어 있다고 볼 수 있습니다. 잎의 CTC예제에서 설명한 $\epsilon$의 역할과 비슷하다고 볼 수 있지요.
$x$가 주어졌을 때 RNN Trasducer는 다음과 같은 조건부확률을 구합니다. \(P(y \in Y^* | x) = \sum_{a\in\Beta^{-1}(y)}{P(a|x)}\) 모든 경우의 $y$, $Y^*$ 중에서 $y=(y_1,y_2,y_3,…,y_U)$가 나올 확률은 $y$에 $\varnothing$이 포함된 $\bar{y}$의 모든 경우에 대한 확를을 합한 값이다.
- $x$가 주어졌을 때 나올 수 있는 모든 $y$ 레이블들 $Y^*$라고 하겠습니다
$ (y_1,y_2,y_3),(y_2,y_1,y_2,y_3),(y_3,y_1,y_5,y_6,y_7)… \in Y^* $
- 이 레이블들 중 하나인 $y$가 출력일 확률이 $ P(y \in Y^* | x) $입니다
$ y = (y_1, y_2, y_3) $
- 그 $y$에 $\varnothing$이 포함된 집합이 $a\in\Beta^{-1}(y)$입니다
$ (y_1,\varnothing,y_2,\varnothing,y_3),(y_1,\varnothing,\varnothing,y_2,\varnothing,y_3)… \in Beta^{-1}(y) $
- $\varnothing$이 포함된 가능한 모든 $a$값의 확룰을 합하면 입력이 $x$일때 $y$가 출력일 확률이 됩니다
이 확률분포를 구하기 위해서 RNN-T는 두가지의 RNN을 사용합니다.
- Transcription Network 입력 $x$에 대한 입력 시퀀스 $f = (f_1,…f_T)$를 생성합니다. Input-Input dependencies를 포함합니다.
- Prediction Network 출력 $y$에 대한 출력 시퀀스 $g = (g_0,…g_U)$를 생성합니다. Input-Input dependencies를 포함합니다.
2.1 Prediction Network
Prediction Network는 RNN으로 입력 레이블에 $\varnothing$을 호함한 U+1 크기의 입력을 받습니다. \(\hat{y} = (\varnothing,y_1, y_2,...,y_U)\) 각각의 입력은 K크기의 one-hot-vector로 $\varnothing$은 0으로 채워진 백터로 인코딩되어 포합됩니다. 예로, 알파벳으로 별로 인코딩을 하는 경우 26크기의 one-hot-vector이 되며 $\varnothing$은 26개의 0으로 채워진 백터가 됩니다. 이것은 단순한 예로 패딩, 구두점들이 포함되지 않은 인코딩입니다.
입력은 RNN을 통과하여 K+1 크기의 prediction vector $g_u$들을 출력합니다. \(g = (g_0,g_1,g_2,...g_u)\) 26 크기 인코딩을 사용했다면, 각각의 출력 백터들이 27 크기를 갖습니다. 0번째는 $\varnothing$, 1번째는 alphabet a, 2번째는 alphabet b에 관련된 값을 갖습니다. 앞에서 말했다싶이 알파벳별로 토큰화를 시켰다면 이렇게 되는 것이지요.
2.2 Transcription Network
Prediction Network과 동일하게 RNN을 이용하며 음성 시퀀스 $x$를 입력으로 시용합니다. \(x = (x_1, x_2, x_3,...,x_T)\) Transcription Network 또한 Prediction Network와 동일하게 K+1 크기의 백터를 출력합니다. \(f = (f_1,f_2,f_3,...,f_U)\)
2.3 Output Distribution
다음으로 Transcription 백터 $f_t$와 Prediction 백터 $g_u$를 이용하여 출력 밀도 함수를 정의합니다. \(h(k,t,u) = exp(f_t^k + g_u^k)\) 그리고 위 정보들을 이용해 출력분포를 정의해 줄 수 있습니다. \(P(k \in \bar{y}|t,u) = {h(k,t,u)}/{\sum_{k^f\in\bar{y}}h(k^f,t,u)}\) 시간 $t$와 레이블 $u$에서 값이 $k$일 확률입니다 softmax값을 구하는 것과 같지요.
그리고 우리는 보기 편하도록 다음과 같이 둘 것입니다. \(y(t,u) = P(y_{u+1}|t,u) \\ \varnothing(t,u) = P(\varnothing|t,u)\)
$y(t,u)$는 $u$번쨰 레이블에 입력된 값 $y_{u+1}$이 올 확률입니다. $y_{u+1}$에서 $u+1$인 prediction network에서 $u$는 $0$부터 시작하고 실제 레이블 $y$는 $1$부터 시작하기 떄문입니다. 이와 같이 확률을 표현하므로 아래 lattice의 Transition Probability들을 표현할 수 있습니다.
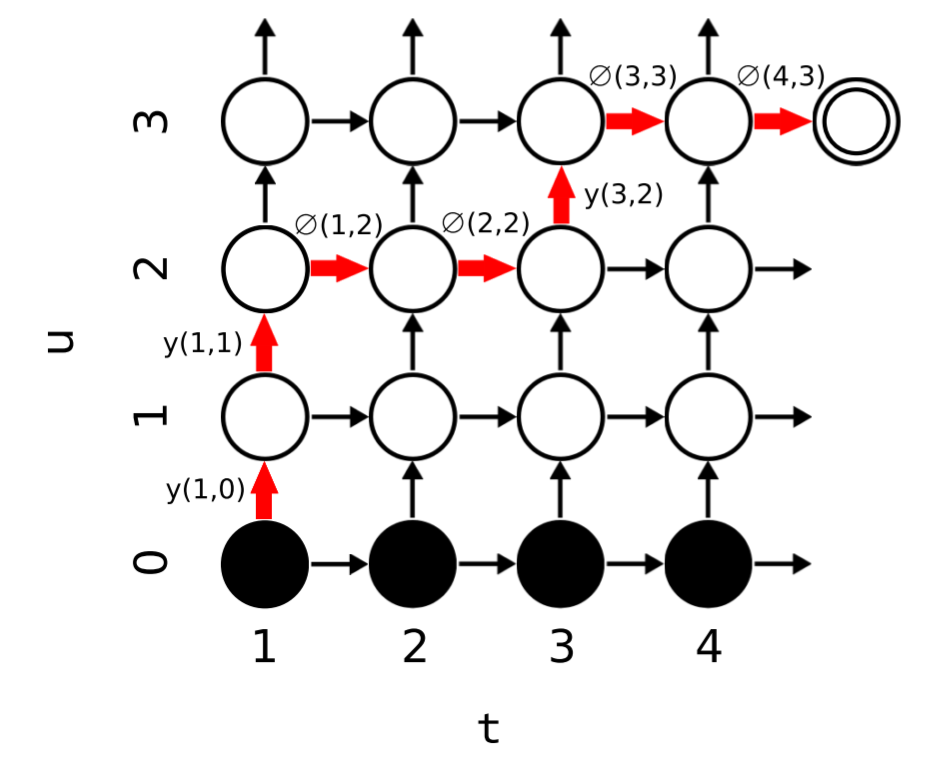
왼쪽 아래부터 오른쪽 위까지의 경로들이 $x$와 $y$ 사이의 Alignment들에 대응합니다. 모든 경로들이 출력될 확률을 합해 $x$가 입력됬을 때 특정한 $y$가 출력될 확률을 구할 수 있습니다.
2.4 Forward-Backward Algorithm
\(forward: \ \ \ a(t,u) = a(t-1,u)\varnothing(t-1,u) + a(t,u-1)y(t,u-1) \\ backward: \ \ \ \beta(t,u) = \beta(t+1,u)\varnothing(t,u+1) +beta(t,u+1)y(t,u)\) initial condition: \(a(1,0) = 1 \beta(T,U) = \varnothing(T,U)\) Probability: \(P(y|x) = a(T,U)\varnothing(T,U)\)
2.5 Training
입력 시퀀스 $x$와 출력 시퀀스 $y^*$가 주어졌을 때 모델을 학습하는 방법 log-loss를 최소화하는 것입니다 \(L = -ln(P(y^*|x))\)
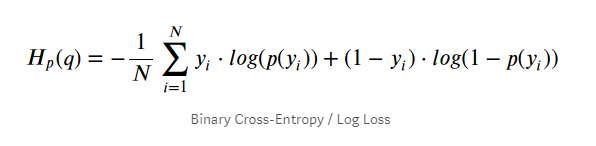 정답레이블에 관해
정답레이블에 관해 binary cross-entrophy를 적용해준 것입니다.
\(P(y^*|x) = \sum_{(t,u):t+u=n}{a(t,u)\beta(t,u)}\) 즉, 앞서 보았던 lattice의 대각선 노드들을 더해준 값입니다.
(1,0)
(1,1)+(2,0)
(1,2)+(2,1)+(3,0)
(1,3)+(2,2)+(3,1)+(4,0)
...
2.6 Testing
테스트 시에는 fixed-width beam search를 이용합니다. beam의 개수가 W=3일 경우, t를 증가시킬 때마다 확률이 가장 높은 3개의 값을 뽑아냅니다. 그리고 그 3개 경우를 이용해 다음 t를 진행합니다
이 알고리즘은 N best search$(N \leq W)$로 확장 될 수 있습니다. t가 진행될 떄마다 W개의 확률들을 뽑아내는 것은 동일하지만 진행될 때 확률이 가장 높은 N개를 따로 저장해줍니다. t가 진행될 때마다 이 값은 더 높은 확률이 등장하면 갱신될 수 있습니다.
이렇게 하므로써 다양한 길이를 가지는 N개의 결과를 가질 수 있을 것입니다.
prediction network의 output은 t가 진행될 떄마다 갱신됩니다. t시간에 beam search를 통해 구한 입력값을 prediction network의 RNN에 넣어주므로써 t+1시간에 사용해줄 prediction vector를 가질 수 있습니다.
