Noisy Student Traning 논문 리뷰
in projects on Blog, Github, Pages, Jekyll, Spacy
서론
컴퓨터 비전, 음성인식 모델에서 좋은 성능을 보이고 있는 Noisy Student Training 에 대해 알아본다 NST 기법이 처음 제시된 논문
Self-training with Noisy Student improves ImageNet classification을 리뷰해 볼 것이다. https://hoya012.github.io/blog/Self-training-with-Noisy-Student-improves-ImageNet-classification-Review/ 참고
이번 글에서는ImageNet Benchmark에서 24번째에 위치하고 있는 NST 학습 방법에 대해 알아본다. 현재 Librispeech 음성인식 모델에서 SOTA를 차지하고 있는 모델 Conformer + Wav2vec 2.0 + SpecAugment-based Noisy Student Training with Libri-Light에 대해 알아보기 전에, 모델이 기반으로 하고 있는 학습 방법인 NST에 대해 먼저 알아보려고 한다.
Noisy Student Training 소개
라벨링이 되지 않은 데이터는 라벨링이된 데이터보다 흔히 볼 수 있으며 훨씬 많은 양을 차지한다. 논문에서는 라벨링된 데이터 뿐만 아니라 라벨링 되지 않은 데이터들을 모델 학습에 사용할 방법을 제시하고 이 학습방법을 사용해 그 당시 ImageNet Classification에서 SOTA를 달성하였다.

NST는 self-training과 distillation을 확장시킨 학습 방식으로 풍부한 양의 이미지로 학습되면서 노이즈에 강한 모델을 만드는 것을 목표로 한다.
Used Dataset
NST 학습을 위해 라벨링된 데이터셋과 라벨링되지 않은 데이터셋이 필요하다. 본 논문에서 사용하는 데이터 셋은 다음과 같다
| Type | Dataset | Size |
|---|---|---|
| Labeled | ImageNet Datset | 14M |
| Unlabeled | JFT Dataset | 300M |
JFT Dataset에서 제공하는 라벨은 NST 학습에서 사용되지 않는다.
NST 학습과정
학습과정은 논문에서 1페이지만 차지하는 것으로 불 수 있듯이 그렇게 복잡하지 않다.
- Labeled 이미지로 Teacher 모델 학습
- Unlabeled 이미지에 대한 Pseudo-Label 생성 (Hard or Soft)
- Data Filtering & Balancing 으로 Pseudo-Label 가공
Data Filtering과정, Confidence 높은 라벨들 필터링하여 사용Balancing과정, Psudo-Label과 Label의 클래스 별 분포도가 같도록 수정
- Labeled 데이터와 Pseudo-Label 데이터로 모델 학습
- Noise를 추가해 Student 모델 학습
- Student 모델을 Teacher 모델로 하여 2-5 과정 반복
본 논문에서는 Hard Label 보다 Soft Label을 사용한 것이 더 좋은 결과를 보인다.

NST는 semi-supervised learning과 knowledge distillation을 확장한 학습 방식이다. Knowledge distillation과 다른점 다음 두 가지이다
노이즈를 추가해 학습된 Student 모델 노이즈가 추가된 상태에서 이전 모델과 동일하게 예측해야 하므로 노이즈에 점점 강한 모델이 만들어진다.
Teacher 모델 보다 크거나 같은 Student 모델 더 큰 모델로 증진된 데이터셋에 대해 더 다양하게 정보를 추출할 수 있다.
그리고 위 두가지를 성능 향상에 대한 핵심이유로 논문에서 설명한다
Noisy 학습
Student 모델은 노이즈가 더 강하게 첨가된 이미지로 Teacher 모델과 같은 결과를 예측해야 한다. Student 모델은 세대가 지날수록 노이즈에 점점 강해진다고 볼 수 있다. RandAugment, Dropout, Stochastic Depth를 noise로 사용한다.
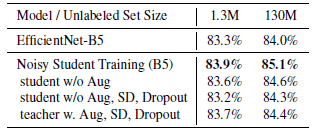
각각의 noise에 대한 설명은 yeomko.tistory.com/42 에 자세히 설명되어 있다.
모델 구조 및 학습방법
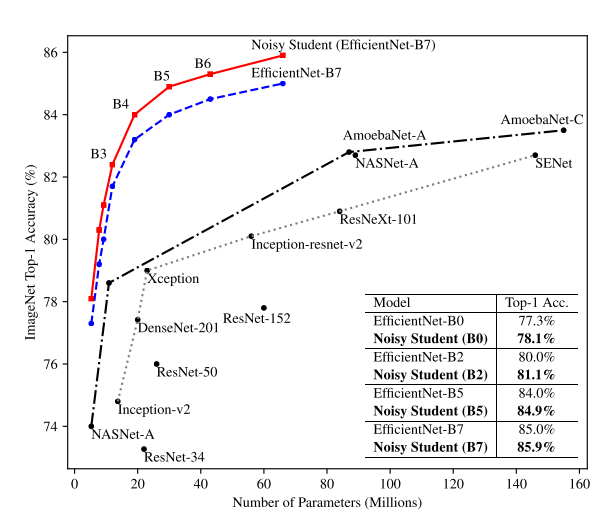
베이스로 사용된 Efficient 모델은 각각 이름이 B7,L0,L1,L2 이며 뒤로 갈수록 모델의 크기가 커지는 것을 의미한다. SOTA를 달성하기 위해 사용한 모델의 자세한 구조는 다음과 같다. 
논문에서 Iteration 마다 사용한 모델은 다음과 같다.
| 0th | 1st | 2nd | 3rd | 4th | |
|---|---|---|---|---|---|
| Teacher | B7 | B7 | L2 | L2 | L2 |
| Student | B7 | L2 | L2 | L2 | L2 |
Iteration 마다 사용되는 Unlabeled Data에 대한 Batch 크기는 다음과 같습니다.
Unlabed Data의 batch size보다 14배 큰 batch size를 1,2 iteration에서 사용한다.
EfficientNet 모델에 효과적인 학습 방식으로 알려진 fix train-test resolution discrepancy 또한 사용된다.
fix train-test resolution discrepancy
Fixing the train-test resolution discrepancy 논문에서 제시된 훈련방법이다 https://yeomko.tistory.com/43 참고
학습 단계에서 보이는 물체의 해상도와 검증 단계에서 보이는 물체의 해상도가 다르다는 문제점을 극복하기 위해 제시된 학습 방식이다. 
흔히 Image Classification에서는 Train과 Test에서 사용되는 이미지는 다음과 같다.
Train: 랜덤하게 이미지의 특정 부분을 잘라내서 224x224 크기로 키워서 학습에 사용Test: 이미지의 중앙에서 224x224 크기만큼 잘라내어 사용
위 그림에서 Standard Pre-Processing을 보게되면 Train과 Test 시 인식하는 말의 크기가 다르다는 것을 확인 할 수 있다. 이 단점을 해결하기 위해 두가지 방안을 제시한다
- Train 시 잘라낸 이미지의 해상도를 낮춰서 훈련
- Test 시 잘라낸 이미지의 해상도를 키워서 검증
이 두가지 기법들을 다양한 실험들을 통해 검증하였고, 최종적으로 Train 시에 475x475, Test 시에는600x600 크기의 해상도로 학습한 FixEfficientNet 모델이 SOTA를 달성한다
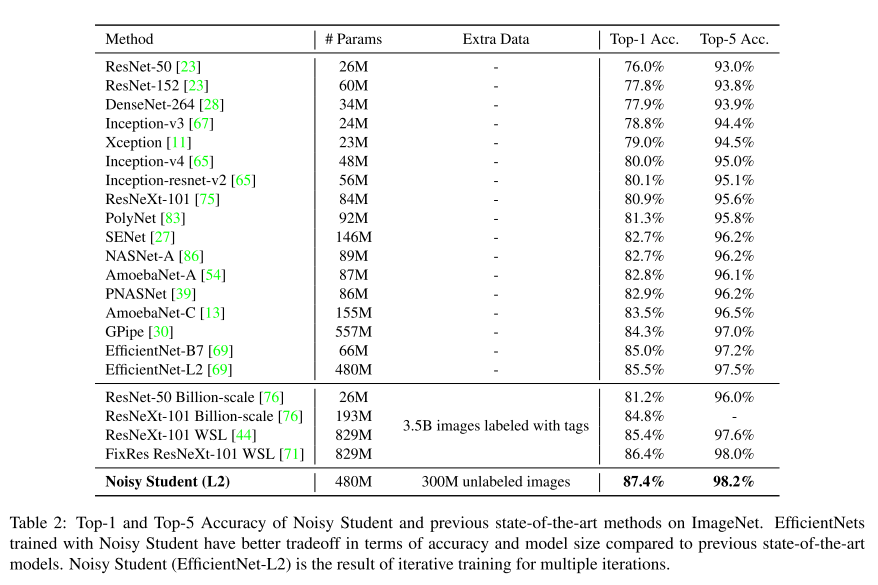
실험결과