ContextNet 논문 리뷰
in projects on Blog, Github, Pages, Jekyll, Spacy
서론
현재 시점(2021.08) Librispeech 벤치마크에서 3번째와 7번째를 차지하고 있는 ContextNet 모델에 대해 알아본다. 다음 논문에서 ContextNet이 처음 제시되었다. https://arxiv.org/abs/2005.03191
이번 글에서는 LibriSpeech Benchmark에서 7번째에 위치하고 있는 ContextNet 모델에 대해 알아본다. 벤치마크 3번째(ContextNet + SpecAugment-based Noisy Student Training with Libri-Light)의 경우 ImageNet에서 성능향상을 보인 NST 훈련방식으로 ContextNet 모델을 학습한 결과이다. 추후 이에 대해 포스팅할 예정이다.
- 목차
ContextNet 소개
음성 프레임의 Alignment 정보를 학습하는데 주로 Connectionist Temporal Classification(CTC) 혹은 RNN Transducer(RNN-T)를 사용한다. ContextNet은 이 방식들 중 RNN Transducer를 사용한 음성인식 모델이다.
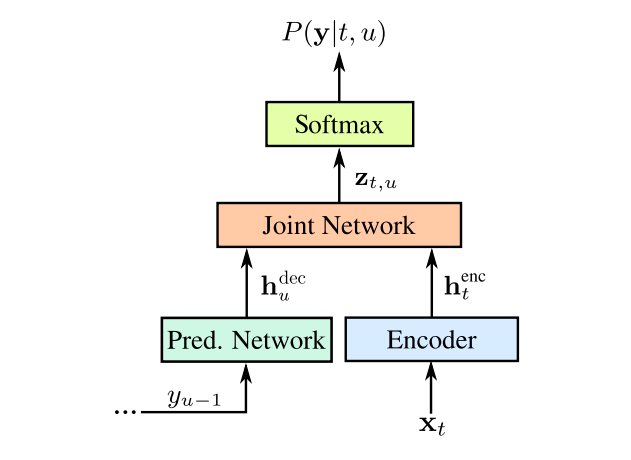
기존 RNN-T 논문과의 차이점은 인코더를 LSTM으로 구성하는 대신 Squeeze-and-Excitation Network(SENet)와 Depthwise Seperable Convolution로 구성한다는 점이다.

SENet을 통해 제한된 문맥 정보만 접근할 수 있는 CNN의 단점을 보완하고 Depthwise Seperable Convolution을 사용해 파라미터 수를 효과적으로 줄일 수 있었다.
LM을 사용하지 않은 경우 2.1%/4.6%, LM을 사용한 경우 1.9%/4.1% WER로 논문이 제시될 당시 SOTA를 달성했다.
사용된 기술들로는 다음과 같다
- Squeeze-and-Excitation Network (SENet)
- Swish Activation
- RNN Transducer (RNN-T)
- Depthwise Seperable Convolution
- SpecAugment
- Language Model
사용된 기술들을 구체적으로 알아보자.
Squeeze and Excitation Network
음성 정보의 인코딩를 인코딩하는데 흔히 Bidirectional RNN, Transformer, CNN 기반 모델들을 사용한다. 각각의 장단점은 다음과 같다
Bidirectional RNN Model:
주변 음성 정보를 파악하는데 효과적이지만 장기의존성 문제 때문에 멀리있는 음성
정보들까지는 파악하지 못한다
Transformer Model:
전체적인 음성 정보들과의 관계를 파악하는데 효과적이지만 CNN 혹은 RNN에 비해 주변
음성 정보들을 인코딩하는데 제약이 있다
CNN Model:
제한된 커널 사이즈에 의해 주변의 음성 정보들과의 관계만 파악이 가능하다
ContextNet은 기본 CNN 모델이 시퀀스의 전체적인 문맥 정보를 인코딩하지 못한다는 단점을 보완하고자 Squeeze-and-Excition 계층을 추가로 사용한다. 2017년 ILSVRC에서 우승한 모델인 SENet에서 SE Block이 처음 제시되었으며 채널들 간의 관계를 더 잘 인코딩하기 위해 사용되었다. ContextNet에서 사용되는 1D SE Block의 구성은 다음과 같다.

SE Block은 Global 정보와 Local 정보가 모두 파악하기 위해 global context vector와 local feature vector를 함께 사용한다.
- Average Pooling과 Fully Connected를 통해 전체적인 문맥정보
global context vector파악 - Local 정보를 인코딩하고 있는
Local Feature Vector와의 Pointwise 곱
Conv 계층들을 통해 Local 정보를 파악하고 마지막에 SE Block을 통해 Global 정보를 파악한다.
Swish Activation Function
\(Act(x) = x \cdot \sigma(\beta x) = \frac{x}{1+exp(-\beta x)}\) $\beta =1$ 를 사용한다. Swish Activation을 사용한 것이 ReLU Activation 보다 꾸준히 더 높은 성능을 보였다
Depthwise Seperable Convolution
다음 블로그들을 참고해 작성되었다 https://wingnim.tistory.com/104 https://towardsdatascience.com/a-basic-introduction-to-separable-convolutions-b99ec3102728
Deep Learning with Depthwise Separable Convolution (F Chollet, 2016) 에서 처음으로 제시된 방법으로 경량화를 필요로하는 모델들에서 정말 많이 사용된다.
- Mobilenets (AG Howard, 2017), 12930회 인용
- MobilenetV2 (J HU, 2018), 12489회 인용
- Efficientnet (M Tan, 2019), 6355회 인용
- Conformer (A Gulati, 2020), 604회 인용
- ContextNet (W Han, 2020), 135회 인용
다음과 같이 많은 유명한 논문들에서 인용되고 있다.
Depthwise Seperable은 depthwise convolution과 pointwise convolution 두 가지의 컨볼루션을 함께 사용한다. depthwise가 필터 별로 관계를 파악한다면, pointwise에서는 필터 사이의 관계를 파악한다.
- DepthWise Convolution 채널마다 서로다른 컨볼루션 필터를 갖는다. 각 채널마다 분리된 컨볼루션 결과를 출력하고 마지막에 그 값들을 합쳐준다. 채널들 사이의 관계는 파악하지 못하지만 각 채널 내에서 데이터들 간의 관계를 파악한다.

- PointWise Convolution Depthwise에서 파악하지 못한 채널들 사이의 관계를 인코딩하기 위해 사용한다.
1x1xo_ch필터를 사용한다. Depthwise에서 channel 개수를 바꿔주지 못하기 때문에 1x1 필터를 통해 출력의 채널 개수를 바꾸는 역할도 한다.
Depthwise-Seperable Convolution은 성능에 영향을 주지 않으면서 파라미터 수를 대폭 줄일 수 있다는 장점이 있다.
에시 3x3 필터를 사용해 2차원 입력을 4차원 출력으로 바꾸는 컨볼루션을 설계하고 싶다.
기존 컨폴루션: 3x3x2x4 필터
Depthwise-Separable 컨볼루션:
- Depthwise : 3x3 필터 2개
- Pointwise : 1x1x2x4
가존 컨볼루션은 72개 파라미터를 필요로하는 반면 Depthwise-Seperarable은 26개 파라미터 만을 필요로 한다
ContextNet에서는 주파수를 채널로 하여Depthwise 컨볼루션을 진행해준 뒤에 1x1 필터를 통해 원하는 채널 개수로 맞춰준다

$\alpha$ 에 따라 달라지는 채널 수를 pointwise 컨볼루션으로 맞춰준다. $\alpha$ 값이 {0.5,1,2} 일 때를 Small, Medium, Large ContextNet으로 사용한다.

Progressive Down Sampling
모델의 훈련속도를 증가시키기 위해서 stride 값이 2인 컨볼루션 블록을 3개 사용해 프레임 길이를 1/8배로 줄여준다

ContextNet 실험 결과

