Conformer
in projects on Blog, Github, Pages, Jekyll, Spacy, Transformer
서론
Librispeech 데이터셋에서 8위에 위치한 conformer에 대해 알아본다 https://paperswithcode.com/paper/conformer-convolution-augmented-transformer https://github.com/espnet/espnet/blob/master/espnet2/asr/encoder/conformer_encoder.py
Introduction
시퀀스를 모델링하는데 Transformer 구조(self-attention을 사용한 기법), convolution 구조가 최근 많이 사용된다
Transformer, Convolution, RNN 모두 각각 장단점이 있다
- Transformer : long distance interactions, high training efficiency 서로 다른 두 지점 간의 interaction을 한다
- Convolution : capture local context efficiently 커널 범위 내 지점들 간의 interaction을 한다. edge와 shape에 관한 feature들을 뽑아낼 수 있다.
- RNN : wide range interactions 전체 시퀀스 간의 interaction을 한다
단점
- Transformer :local feature pattern을 파악하기 어렵다
- Convolution : global 정보들을 파악하기 위해 더 많은 layer와 parameter가 필요하다
최근에 self-attention과 convolution을 결합하므로써 이러한 단점들을 개선할 수 있다고 알려졌다
본 논문은 음성의 global한 정보와 local한 정보들을 모두 capture할 수 있는 Conformer model을 소개한다
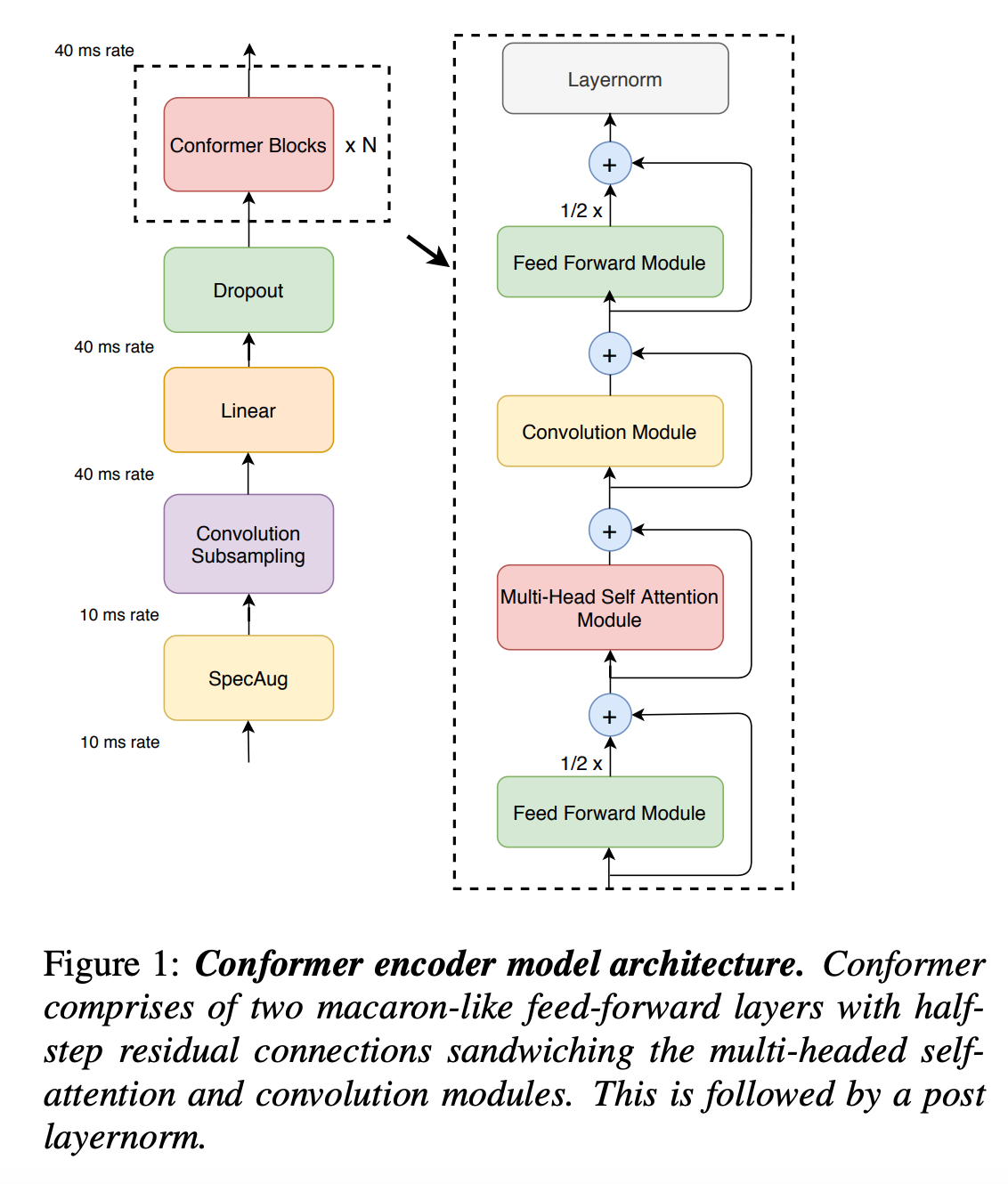
Conformer Model 구조
- SpecAug
- convolution subsampling Layer
- Linear
- Dropout
- Conformer Blocks
- macaron-style FeedForward Module
- multi-head self Attention Module
- Convolution Module
- macaron-style FeedForward Module
Subsampling Layer
[논문의 음성 feature extraction 방식]
80-channel filterbanks features computed from 25ms window with a stride of 10ms
10ms 마다 뽑아낸 데이터들을 1/4 크기로 sub-sampling 한다. stride 크기가 2인 convolution 블록을 2개 사용해 구현한다
Feed Forward Module
residual connection, pre-norm, swish 활성화 함수, dropout을 함께 사용한다 
첫번 째 linear layer 에서 feature을 4배로 증가시킨 후 두번 째 linear layer에서 다시 원래대로 돌려놓는다
Multi-Headed Self-Attention Module
Transformer-XL 논문에서 제안한 relative positional embedding이 포함된 multi-head self-attention(MHSA)을 사용한다.
self-attention이 다양한 말뭉치 길이를 받아들일 수 있도록 사용한다.
[관련 논문]
Relative Positional Encoding for Speech Recognition
and Direct Translation
https://arxiv.org/pdf/2005.09940.pdf
Transformer-XL: Attentive Language Models
Beyond a Fixed-Length Context
https://arxiv.org/pdf/1901.02860.pdf
정규화를 위해 추가적으로 pre-norm, residual, dropout을 사용한다
기존 트랜스포머는 Post-norm인데 반해, pre-norm 적용하며, 이전 연구들에서 pre-norm은 깊은 모델 학습이 원활하게 되도록 도와주는 효과가 있다고 알려진다
Convolution Module
Depthwise-Seperable Convolution와 비슷한 방식을 사용한다. 두가지 convoultion, depthwise와 pointwise convolution을 사용한다.
Depthwise Convolution
 feature 단위로 분리해 Conv1d를 따로따로 해준 후 나온 결과들을 합친다
feature 단위로 분리해 Conv1d를 따로따로 해준 후 나온 결과들을 합친다Pointwise Convolution
 Depthwise를 통해 채널의 개수를 바꿀 수 없으므로 1x1 kernel을 이용한 conv1d를 통해 출력 채널의 개수를 바꾸어준다
Depthwise를 통해 채널의 개수를 바꿀 수 없으므로 1x1 kernel을 이용한 conv1d를 통해 출력 채널의 개수를 바꾸어준다
[o_channel, i_channel, W, H] 크기의 필터가 필요하던 기존의 convolution에 비해 적은 파라미터를 사용해 구현 불가능하다

leyernorm, GLU 활성화함수, batchnorm, swish 활성화함수, dropout을 함께 사용해 Convolution Module을 형성한다
PointWise에서 feature을 2배로 증가시킨다
Conformer Block

Transformer 논문에서 한개의 FFN을 사용한 반면 본 논문에서는 Macaron-Net에 영감을 받아 2개의 FFN을 샌드위치처럼 쌓은 구조를 사용한다 FFN 모듈에 half-step residual connection을 사용한다.
Experiment
구현 환경
- log-mel spectrogram : 80-channel filterbank
- window : 20ms
stride : 10ms
- SpecAugment
- frequency : F = 27
- time : $m_t$ = 10, p = 0.05, T = (utterance x p)
Conformer Transducer
- encoder models : small(10M), medium(30M) and large(118M)
- decoder : single LSTM layer
- dropout : $P_{drop}$ : 0.1
- L2 Regularization : $l_2$ : 0.06
- Transformer Learning rate schedule
- Warm-up : 10k
- peak lr : 0.05/$\sqrt{d}$ (
d: model dimension in conformer encoder)

Result on LibriSpeech
다른 모델들과의 비교

구성 요소들 중요도

구성 요소들 중요도

Attention-Head 개수 비교

depthwise convolution kernel size 비교

32 kernel size까지 학습 결과가 지속적으로 좋아지는 것을 확인 할 수 있다.
