Transformer-Encoder
in projects on Blog, Github, Pages, Jekyll, Spacy, Transformer
서론
다음 글을 참고해 작성했습니다.
Preparing The Data에서는 데이터 셋의 토큰화 및 정수 인코딩 주었습니다. 그 다음 과정인 트랜스포머의인코더`를 구현해 볼 것입니다.
전체적인 그림은 다음과 같습니다. 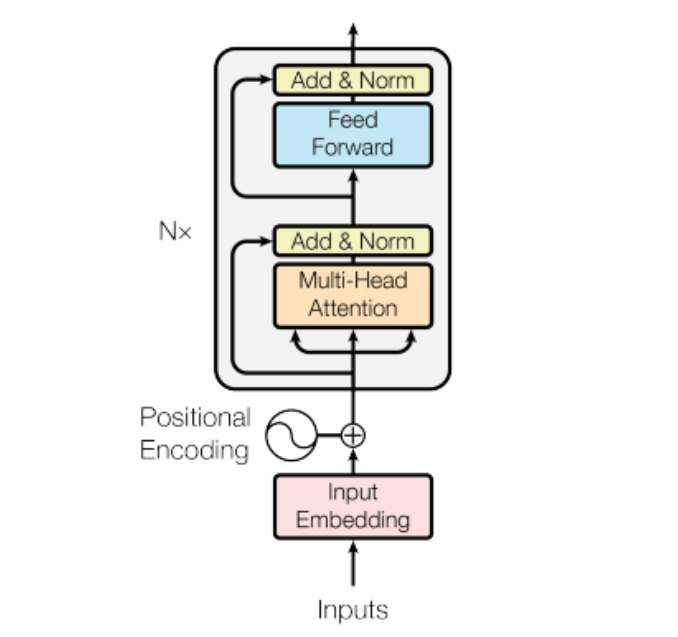
목차
- -
Input Enbedding
입력이 주어지면 처음 거치는 과정이 임베딩 과정입니다. Transformer에서는 두가지 임베딩 과정을 진행합니다. standard embedding과 positional embedding입니다.
Standard Embedding 임베딩 층의 입력으로 정수 인코딩된 단어를 사용합니다. 입력 정수를 밀집 백터(dense vector)로 매핑 해주는 것이 임베딩의 과정입니다. 우리는 이 단계에 PyTorch에서 제공하는 임베딩 함수를 사용하겠습니다.

임베딩 함수를 사용하게 되면 그림에서 보시다시피
임베딩 테이블이 생성 됩니다. 우리 예제에서는 단어가 3개를 6차원 밀집백터로 변환하고자 하며 각각의 밀집 백터가 다른 값을 가지고 있음을 알 수 있습니다.이 가중치들은 학습과정에서 모델이 풀고자하는 작업에 맞는 값으로 계속해서 업데이트 됩니다. 이 때 코사인 유사도, PMI, PPMI, SVD가 사용되겠지요. 다음으로 우리가 실습에서 사용할 임베딩 코드입니다.
self.tok_embedding = nn.Embedding(input_dim, hid_dim) # batch_size: 128 # Unique tokens in source (de) vocabulary: 7853 # hid_dim: 512Standard 임베딩 계층에서 [128x7853x52] 임베딩 테이블이 생긴다는 것을 알 수 있습니다.
Positional Embedding Transformer에서는 토큰에 대한 처리가 동시에 일어납니다. 이에 따라 처리과정에서 토큰의 위치정보를 사용할 수 없지요. 이를 해결하고자 Transformer에서 사용하는 것이 Positional Embedding Layer입니다.
Standard Layer에서의 과정과 똑같지만 입력으로 토큰이 들어가는 것이 아니라 토큰의 위치정보가 들어갑니다. 위치정보는
토큰을 0으로 하여 1씩 증가시키며 얻을 수 있습니다. self.pos_embedding = nn.Embedding(max_length, hid_dim)원조 논문인
Attention is All You Need에서는static embedding을 사용했지만 저희는 Bert와 같은 최근 모델에서 사용되는 Positional Embedding을 사용했습니다.static embedding에 대한 자세한 설명은 이곳을 참고하세요.
- Combined 우리가 학습에 사용할 백터는 토큰과 그 위치정보가 모두 포함되어 있어야 합니다. 두가지 임베딩 과정에서 구해진 백터를 합쳐주면 구할 수 있겠지요.
여기서 중요한 점은 우리는 구해진 백터에 scaling factor을 곱해줍니다. \(scaling factor: sqrt(d_{model})\)
d_model은 밀집백터의 차원 수와 같습니다. 왜 이것을 사용할까요? 임베딩 과정에서의분산값이 낮아입니다. 분산을 줄이므로서 보다 더신뢰성 있는 학습을 할 수 있는 것이지요.
Multi-head Attention
Transformer를 빛내주는 기법인 Self-Attention 기법이 사용되는 계층입니다. 핵심 계층이고 Transformer 구조에서 3가지 입력에 사용됩니다. Encoder Input, Decoder Input, between Encoder-Decoder의 데이터에 대한 self-attention을 구하는데 사용됩니다.
Scaled Dot-Product Attention
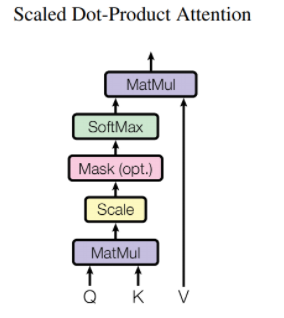 Self Attention의 연산을 해주는 부분입니다. 입력으로
Self Attention의 연산을 해주는 부분입니다. 입력으로 Q(query),K(key),V(value)변수를 받습니다.연산은 다음과 같습니다. \(\text{Attention}(Q, K, V) = \text{Softmax} \big( \frac{QK^T}{\sqrt{d_k}} \big)V\) \(d_k = d_{model} /{(number of head)}\)
한마디로 요약하지면, 모든
Query에 대해 ‘Key’와 의 연관성Attention energy를 구하고Value값들과 곱하여Attention Value를 구하는 것입니다.MatMul: Query값들과 각 key값의 행렬곱을 구합니다Scale:Mask: 중요하지 않다고 생각하는 토큰들은 Attention Value에 포함되지 않도록 즉, Softmax 계층의 출력이 0에 가깝게 나오도록 해줍니다.SoftMax: 각각의 Query에 대해 얼마나 연관이 있는지 상대적인 값으로 나타내줍니다MatMul: Attention value를 구해줍니다
Multi-Head Attention 앞의 연산에서 사용되는
d_k값은head_dim : 각 head의 차원을 뜻하며, head은 간략히 말하면Scaled Dot-Product Attention의 개수 입니다.self.hid_dim = hid_dim self.n_heads = n_heads self.head_dim = hid_dim // n_heads각 토큰은 임베딩되에
d_model512크기를 갖게되며,head의 개수8개의 ` Scaled Dot-Product Attention으로 나누어 처리됩니다. 그리고 이 경우에 각각의 layer에서d_k`의 크기 64씩 데이터가 처리됩니다.식의로 표현하면 다음과 같습니다.

d_model의 차원이d_k의 차원n_head개로 나뉩니다.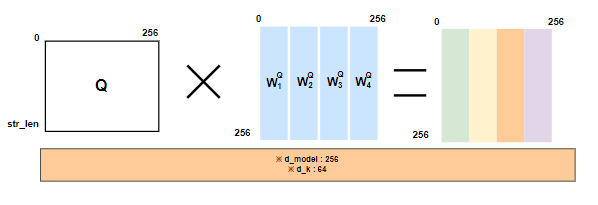 그림에서 볼 수 있듯이 d_model 크기의 데이터를 이용해 d_k의 데이터를 만듭니다 각각 나뉘에 처리가 됩니다.
그림에서 볼 수 있듯이 d_model 크기의 데이터를 이용해 d_k의 데이터를 만듭니다 각각 나뉘에 처리가 됩니다. .PNG)
- Encoder에서의 Self-Attention
#self attention _src, _ = self.self_attention(src, src, src, src_mask)
key와 query, value 모두 같은 input source를 사용합니다.
class MultiHeadAttentionLayer(nn.Module): def __init__(self, hid_dim, n_heads, dropout, device): super().__init__() assert hid_dim % n_heads == 0 self.hid_dim = hid_dim self.n_heads = n_heads self.head_dim = hid_dim // n_heads self.fc_q = nn.Linear(hid_dim, hid_dim) self.fc_k = nn.Linear(hid_dim, hid_dim) self.fc_v = nn.Linear(hid_dim, hid_dim) self.fc_o = nn.Linear(hid_dim, hid_dim) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device) def forward(self, query, key, value, mask = None): batch_size = query.shape[0] Q = self.fc_q(query) K = self.fc_k(key) V = self.fc_v(value) Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) #energy = [batch size, n heads, query len, key len] energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale # mask == 0일 경우 energy를 0으로 설정 #src_mask = [batch size, 1, 1, src len] if mask is not None: energy = energy.masked_fill(mask == 0, -1e10) attention = torch.softmax(energy, dim = -1) x = torch.matmul(self.dropout(attention), V) #x = [batch size, n heads, query len, head dim] x = x.permute(0, 2, 1, 3).contiguous() x = x.view(batch_size, -1, self.hid_dim) x = self.fc_o(x) return x, attention Attention Energy
.PNG)
- Masking
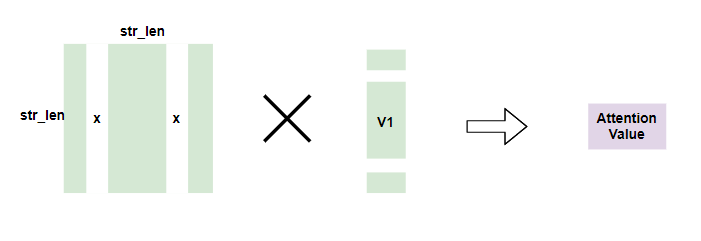
Dropout & Normalization
Normalization 정규화는 Layer Normalization을 이용하며, 각각의 입력 백터의 크기(hid_dim) 마다 정규화를 해줍니다.
- Dropout 무작위로 선택된 뉴런들을 무시해줍니다.
## Point-wise Feedforward Layer  Position 마다, 즉 개별 단어마다 적용되기 때문에
Position 마다, 즉 개별 단어마다 적용되기 때문에 position-wise라고 합니다. Linear Transformation 두 번과 활설화 함수 ReLU로 이루어져 있습니다. BERT는 ReLU 대신 GeLU 활성화 함수를 사용합니다. \(FFN(x) = max(0, xW_1 + b_1)W_2 + b_2\) 보통 pf_dim은 hid_dim보다 큰 값을 가지며 논문에서의 Transformer는 pf_dim으로 2048 크기를 사용합니다.
# 512 -> 2048
self.fc_1 = nn.Linear(hid_dim, pf_dim)
x = self.dropout(torch.relu(self.fc_1(x)))
#2048 -> 512
x = self.fc_2(x)
self.fc_2 = nn.Linear(pf_dim, hid_dim)
0이상의 값들만 가지고 드롭아웃을 해준 후 decoder 계층으로 전달해줍니다.
[참고] Attention is all you need paper 뽀개기 [https://pozalabs.github.io/transformer/] 6 - Attention is All You Need [https://github.com/bentrevett/pytorch-seq2seq/blob/master/6%20-%20Attention%20is%20All%20You%20Need.ipynb]
