Information Theory 3
정보이론 연구 분야
대표적으로 정보이론이 활용되는 분야는 다음고 같다.
- MPEG-4, JPEG와 같은 압축 기술의 베이스가 되는
소스코딩 - 노이즈가 있는 채널에서 정확한 정보를 보내기 위한 기술인
채널코딩 - 최근 암호화 분야에서 연구되고
양자암호
우리는 이 중 채널코딩을 중심을 공부해본다.
채널 코딩
3가지 가정을 기반으로 이론들이 설명된다.
- 입력은 유한하며 independent and identically distributed(i.i.d)의 연속균등분포
- 메시지가 앞선 가정이 되도록 채널에는 모듈레이터오 디모듈레이터를 포함
- 채널이 주어진다고 가정
Discrete Memoryless Channel (DMC)
\[P_{Y_k|X_1,...,X_K, Y_1, ...,Y_{K-1}}(y_k| x_1,...,x_k, y_1,...,y_{k-1}) = P_{Y|X}{Y_k|X_k}\]현재 출력 $y_k$ 는 현재 입력 $x_k$ 에만 연관(dependent)되어 있다 채널은 $x_k$와 $y_k$ 의 값에 따라서 변하지 않고 일정하다.
언급하지 않는다면 항상 피드백 링크가 없다고 생각하며 그럴 경우 다음 식이 성립한다. \[P(y_1,...,y_n | x_1,...,x_n) = \Pi^n_{k=1} P_{Y|X}(y_k|x_k)\]
연속된 k 정보를 전송하는 것은 독립적인 정보를 k 번 전송한 것과 같다고 생각할 수 있다. 즉, 각각의 사건을 독립사건으로 표현할 수 있다.
채녈 용량 (Channel Capacity)
채널의 불확실성을 이겨낼 수 있는 인코딩 기법이 필요하다. 채널의 랜덤한 성격 때문에 전송된 $X_n$ 과 수신된 $Y_n$ 의 값이 다르더라도 메시지를 정확히 수정할 필요가 있다. 이러한 코딩 기법을 제한하는 것이 Channel Capacity Theorem 이다.
구체적인 채널 캐패시티 이론에 들어가기에 앞서 채널 캐패시티를 구하는 방법을 알아본다. \[C = max{I(X;Y)}\]
여러가지 채널의 캐패시티
- Noiseless Binary Channel
상호의존정보의 최대값이 X 엔트로피의 최대값과 같다. 이산 채널은 확률이 연속균등분포일 때 엔트로피가 최대가 된다. \[maxH(x) = H(\frac{1}{2}, \frac{1}{2}) = 1\]
Symmetric example 7-12 p1 과 p3 는 통과하는 채널의 상태가 같기 때문에 동일한 확률을 부여해야 한다 어느 한쪽에 더 많이 준다면 엔트로피가 줄어들 것이다. (?) 이게 맞나?
오류없는 전송을 위해서(reliable) 채널을 위해서 여러번 사용해서 보내야한다.
n이 상당히 큰 값이어야 한다 n : 수십~수천으로 setting 할 수 있다. 시나리오에 따라 적절히 설정
n=2 => X = { 00, 01, 10, 11 } n=3 => X = { 000, 001, 010, 100, … }
출력을 보고 입력을 추론할 수 있었던 typewriter에서와 같이 채널 코딩에서도 적용해보고자 한다.
수신된 $Y^n$ 은 $2^{nH(Y|X)}$ 가 된다. -> 하나의 $X^n$ 을 전송했을 때 $Y^n$의 집합의 크기
typical sequence의 개수: $2^{nH(Y)}$ -> $Y^n$ 으로 올 수 있는 (주로 나오는) 시퀀스
disjoint set의 개수: $X^n$ 과 $Y^n$ 쌍의 개수 부분집합이 몇개 존재하는지 알 수 있다 \[\frac{2^{nH(Y)}}{2^{nH(Y|X)}} = 2^{nI(X;Y)}\]
n 비트 전송을 통해서 nI(X;Y) 만큼의 전송 용량을 확보 1 비트에 I(X;Y) 만큼의 전송이 가능하게 함(disjoint set)
Definition
\(R = \frac{logM}{n}\)
Definition
n 이 무한대로 가면 $\lambda ^{n}$ 이 0 으로 수렴하는 경우 $(\lceil 2^{nR} \rceil, n)$ 코드들이 achievable 하다고 할 수 있다.
Definition
Capacity는 모든 달성 가능한 Rate 중에 상한값이다.
Jointly Typical Sequences
디코더는 $Y^n$ 을 보고 $Y^n$ 과 jointly typical 한 시퀀스 $X^n(i)$ 를 송신신호라고 판별함.
독립적으로 매핑되는 $Y^n$ 과 $X^n$ 을 jointly typical set 이라고 부를 수 있다. \[A_{\epsilon}^{(n)} = \{ (x^n, y^n) \in : \textit{X}^n \times \textit{Y}^n : \\ |-\frac{1}{n}log{p(x^n)} - H(\textit{X})| < \epsilon, \\ |-\frac{1}{n}log{p(y^n)} - H(\textit{Y})| < \epsilon, \\ |-\frac{1}{n}log{p(x^n,y^n)} - H(\textit{X,Y})| < \epsilon \}\]
$\epsilon, n$ 값에 따라서 특정 시퀀스가 typical sequence인지 아닌지 달라지게 된다.
Theory 7.6.1 joint AEP
jointly typical sequence들은 다음과 같은 성질을 만족 시킨다
iid 하다고 가정하면 \(p(x^n, y^n) = \Pi_{i=1}^n p(x_i, y_i)\)
$ Pr((X^n, Y^n) \in A_{\epsilon}^{(n)}) \rightarrow 1$ as $n\rightarrow \infty$ n 이 무한대로 발산하는 경우 X^n과 Y^n은 무조건 jointly typical 하다?
$ A_{\epsilon}^n \leq 2^{H(X,Y)+\epsilon}$ - if $ (\tilde{X^n}, \tilde{Y^n}) \sim p(x^n)P(y^n)$, $\tilde{X^n}$ 과 $\tilde{Y^n}$이 독립적이라는 의미이다 시퀀스가 독립적이면서 typical sequence인 경우 \(Pr((\tilde{X^n}, \tilde{Y^n}) \in A_{\epsilon}^n) \leq 2^{-n(I(X;Y)-3\epsilon)}\) 충분히 큰 n 값을 갖는 경우 \(Pr((\tilde{X^n}, \tilde{Y^n}) \in A_{\epsilon}^n) \geq (1-\epsilon)2^{-n(I(X;Y)+3\epsilon)}\)
랜덤하게 고른 쌍이 jointly typical 할 확률은 다음과 같다. \[\frac{2^{nH(X,Y)}}{2^{nH(X)} \times 2^{nH(Y)}} = 2^{n(H(X,Y) - H(X) - H(Y))} = 2^{-nI(X;Y)}\]
$2^{nI(X;Y)}$ pair 중 하나만 jointly typical 하다?
Shannon’s Channel Coding Theorm
0이 아닌 작은 확룰의 에러를 가정한다
채널을 여러번 사용하면 lln 의 효과를 사용할 수 있다
코드북들 중에 임의의 코드북을 선택해서 전송 적어도 하나의 좋은 코드가 존재함을 보일 수 있다 -> 에러가 0으로 수렴하는 것을 보이는 것이 난해한 부분 중 하나이지만 -> 3번을 사용하면 에러분석을 상당히 간단하게 만들 수 있다.
1,2 관련된 코딩 기법은 repretetion 코드를 들 수 있다. 0 -> 0000… -> 01000010… 1 -> 1111… -> 11101011… n이 커질 수록 코딩 에러 확률을 0으로 보낼 수 있지만 완전히 0으로 만들 수는 없다
\(R = \frac{logM}{n}\) 1번을 달성할수는 있지만 n이 커지면 R은 0으로 수렴하여 결국에는 rate를 0 밖에 전송하지 못한다는 문제점이 발생한다.
C = 1-H(p) 인 BSC(Binary Symmetric Channel) 채널 \[M = 2^{n(1+H(p))}\]
Message size도 2의 지수승으로 커져야 채널 커패시티를 달성할 수 있다
송신단은 Random Code Selection, 수신단은 jointly typical sequence decoding 수행
Jointly Typical Sequence일 확률 $2^{-nI(X;Y)}$
2^{nI(X;Y)} 보다 적은 시퀀스를 보내게 되면,
송신 시퀀스가 고르게 퍼져있어 Y^n에 맞는 X^n을 구할 수 있다
Theorm 7.7.1 (Channel coding theorm)
C 보다 작은 rate는 달성 가능하다
maximum error 확률이 0 으로 수렴하면 다른 메시지의 에러확률도 0으로 수렴한다 -> channel coding theorm의 achievability
역으로, 어떠한 코드를 만들더라도 0으로 만들기 위해서는 code rate가 C보다 같거나 작아야 한다. 이 이상의 Rate로는 전송할 수 없다.
Codebook Generation
메시지가 $2^{nR}$ 개 있으므로 그에 대응하는 codeword를 랜덤하게 만들어준다
채널 인코딩 -> 메시지와 codeword를 대응 시키는 과정
특별한 규칙없이 랜덤하게 generation하고 순서대로 메시지에 대응시켰기 때문에 랜덤코딩 이라고 한다.
행렬을 통해서 메시지와 코드의 대응관계를 볼 수 있다.
n과 R에 따라 코드의 사이즈가 달라진다. p(x)에 따라서 iid하게 생성된다 \[Pr(C) = \Pi_{w=1}^{2^{nR}} \Pi_{i=1}^{n} p(x_i(w))\]
인코딩 디코딩 과정
- 수신단이 코드북을 알고있어야 한다.
- p(y|x)를 수신단에서 알고 다고 가정한다 채널을 송수신단이 미리 알고 있다고 가정 송신단 측면에서 채널을 알아야지 multial information 최대화 시키는 p(x)를 구하기 수월 수신단 측면에서 jointly typical sequence를 판단하기 위해 필요하다
실제 유무선 채널 환경을 생각해보면, 송신단 자신이 보내고자하는 데이터 뿐만 아니라 수신단이 채널을 수정할 수 있도록 하는 파일럿 신호를 같이 보내기 때문에 수신단은 대부분의 경우 채널을 상당히 정확히 알고 수신을 하게 된다.
송신단이 채널의 상태를 알기 위해서는 feedback이 필요하다.
메시지를 선정하는 것은 uniform distribution을 따른다. $ Pr(W=w) = 2^{-nR} $
codeword에서 w번째 행을 골라서 전송하게 된다.
채널에 의해서 결정되는 Transition probability에 따라서 길이가 N인 y^n 시퀀스를 수신하게 된다
6. maximum likelihood 또는 maximum a posteriori 방법을 사용해 디코딩할 수 있지만
ML과 MAP는 하나하나 비교해서 가장 적합한 값을 골라야하기 때문에 복잡한 연산이 필요하다 (수학적으로 분석하기 어렵다) 따라서 Jointly Typical Decoding을 사용해 분석한다 LLN을 이용해서 상대적으로 성능을 분석하기 수월하도록 하고, n이 무한대로 갈수록 optimal에 가까운 성능을 낸다
- $X^n(\hat{W}), Y^n$ 이 jointly typical 하다
- $\hat{W}$ 외의 다른 메시지에 대응되는 codeword 들은 $Y^n$ 과 jointly typical 하지 않다 위 두 조건을 만족하지 않는다면 에러가 발생하게 된다.
이러한 이벤트를 $\mathcal{E}$ 로 표시한다.
에러 확률 분석
하나의 코드에 대한 에러 확률을 고려하기 보다는 모든 랜덤코드의 평균 에러 확률을 고려한다. \[Pr(C) = \Pi_{w=1}^{2^{nR}} \Pi_{i=1}^{n} p(x_i(w))\]
n=2, R=0.5 일 경우 ($2^{nR} = 2$ ) 생성될 수 있는 코드북을 보면,
[ C_0 = \left[ {\begin{array}{ccccc} a_{0} & a_{0}
a_{0} & a_{0}
\end{array} } \right] ] [ C_1 = \left[ {\begin{array}{ccccc} a_{1} & a_{0}
a_{0} & a_{0}
\end{array} } \right] ] … [ C_{16} = \left[ {\begin{array}{ccccc} a_{1} & a_{1}
a_{1} & a_{1}
\end{array} } \right] ] 의 16가지 code를 가질 수 있다.
code 생성 과정이 symmetric (i.i.d)하기 때문에, 에러확률은 message 인덱스에 dependent 하지 않음 \[P(\mathcal{C}) = \sum_{i=1}^{16}P(\mathcal{E}|C_i)P(C_i)\]
모든 코드의 평균에러 확률을 고려할 예정이다.
iid 하게 전송하기 때문에 에러확률은 code 내 모든 메시지에서 동일하다.
그래서 우리는 첫번째 메시지를 보낸다고 가정하고 에러를 분석할 예정이다 (without loss of generality)
에러가 발생하는 상황
- 받은 신호 Y^n과 jointly typical한 X^n이 없는 경우 n 이 무한대로 가면 LLN에 의해서 jointly typical 한 X^n은 무조건 존재한다고 볼 수 있다
- jointly typical codeword가 여러개 있을 경우 Y^n을 송신한 X^n(1)과 다른 X^n(i) 중에 Y와 jointly typical할 확률은 다음과 같다 -> iid 로 생성되므로 X^n(1)과 X^n(i)는 independent 하다 -> X^n(i)는 Y^n 은 independent 하다
\(Pr((\tilde{X}^n, \tilde{Y}^n) \in A_{epsilon}^{(n)}) \leq 2^{-n(I(X;Y)-3\epsilon)}\) 각 codeword가 jointly typical할 확률
송신 codeword 수를 $2^{n(I(X;Y)-3\epsilon)}$ 보다 작게 송신하면
\(R < I(X;Y) - 3\epsilon\) 2번 에러를 0에 가깝게 만들 수 있다 ( 잘 모르겠다.. )
에러 확률 계산
모든 codebook의 모든 codeword를 고려한 평균 에러 확률을 고려함. \[2^{nR} \times |C| = 2^{nR} |X|^{n\times 2^{nR}}\]
|X| : cardinarity matrix가 [nx2^{nR}] 로 구성되며 각 matrix 요소를 |X| 에서 선택된다 codeword수 x codebook수
\(Pr(\mathcal{E} | W = 1) = P(E_1^c \cup E_2 \cup...\cup E_{2^{nR}} | W=1 )\) \(\leq P(E_1^c|W=1) + \sum_{i=2}^{2^{nR}} P(E_i| W=1)\)
P(AUB) <= P(A) + P(B) 를 사용한 결과이다 \[\leq P(E_1|W=1) = Pr((X^n, Y^n) \in A_{epsilon}^{(n)}) \geq (1-\epsilon)\]
\(\therefore P(E_1^c|W=1) \leq \epsilon\) 구해진다 \[Pr((\tilde{X}^n, \tilde{Y}^n) \in A_{epsilon}^{(n)}) \leq 2^{-n(I(X;Y)-3\epsilon)}\] \[P(E_i| W=1) \leq 2^{-n(I(X;Y)-3\epsilon)}\] \[P(E_1^c|W=1) + \sum_{i=2}^{2^{nR}} P(E_i| W=1)\] \[\leq \epsilon + \sum_{i=2}^{2^{nR}}2^{-n(I(X;Y)-3\epsilon)}\] \[= \epsilon + (2^{nR}-1)2^{-n(I(X;Y)-3\epsilon)}\]
-1을 없애주고 지수승을 묶어주면, \[\leq 2\epsilon\] \[R < I(X;Y) - 3\epsilon\]
이라면, n이 무한대에 감에 따라 뒤에 식은 0으로 수렴하므로 항상 입실론보다 작다고 생각할 수 있다
R이 mutual information 보다 작다면, 평균 에러확률이 2x입실론보다 작은 입실론과 n을 무조건 구할 수 있다
Maximum error 확률이 0으로 간다는 것을 보이자
mutial information을 최대화 시키는 p*(x)로 가정하고 푼다. \[C = max_{P(i)}I(X;Y)\]
앞에서 평균에러가 $2\epsilon$ 보다 작은 코드가 최소 하나 존재한다는 것이 증면 됬다.
그런 코드 중에 하나를 C* 라고 하자.
앞에서 살펴본 랜덤코드 생성으로 만든 다음에 $2\epsilon$ 보다 작은지 일일히 찾아봐야 한다. \[Pr(\mathcal{E}|C*) = \sum_{i=1}^{2^{nR}}{\lambda_i(C*)p(i)}\]
uniform distribution 이므로, \[= \frac{1}{2^{nR}} \sum_{i=1}^{2^{nR}}{\lambda_i(C*)}\]
좋자 않은 Codeword들을 절반을 버린다고 가정하겠다 \[Pr(\mathcal{E}|C*) \leq \frac{1}{2^{nR}} \sum_{i=1}^{2^{nR}}{\lambda_i(C*)} \leq 2 \epsilon\]
안좋은 codeword들을 버렸기 때문에 남아있는 codeword들은 $4\epsilon$ 보다 무조건 작게된다.
$2^{nR-1}$ codeword를 사용하게 될 것이며 $R-\frac{1}{n}$의 rate을 가질 것이다. n이 커질수록 negligible 하다
codeword 중 절반을 버릴 경우에 최대 에러도 0에 가깝게 만들 수 있다
Random Coding의 의미
최대 에러 확률을 0으로 가게 만드는 code가 존재한다는 것을 증명하는데 쓰일 뿐, 실제 사용되는 coding 기법은 아니다.
| X | ^{n x 2^{nR}} 만큼의 lookup table이 필요한데 이것은 거의 불가능하다. |
capacity에 거의 근접하는 코드들: Turbo 코드, LDPC 코드, Polar 코드 등등
Turbo - 4G, LDPC, polar - 5G
Converse 증명
어떠한 기법을 쓰더라도 에러 확률이 0이 되려면 capacity 이상 보낼 수 없다
$ W -> X^n(W) -> Y^n -> \hat{W} $
fano’s inequality estimator가 틀릴 확률에 대한 bound를 제시한다. $P_e$ 가 최소 몇 이상이 되는지 알려준다 \[1+P_e log|X| \geq H(P_e) + P_e log |X| \geq H(X|\hat{X}) \geq H(X|Y)\]
따라서 위의 식을 통해 다음의 식을 구할 수 있다 \[H(W|\hat{W}) \leq 1 + P_e^{(n)} nR\]
joint entropy가 각각의 엔트로피의 합보다 항상 작거나 같다
mutual information은 항상 C보다 작거나 같다 \(I(X^n;Y^n) \leq nC\)
n이 큰 값이고 최대 에러 확률이 0으로 수렴하면 \[R \leq C\]
위와 같은 식을 얻을 수 있다 \[P_e^{(n)} \geq 1 - \frac{C}{R} - \frac{1}{nR}\]
의 식으로도 쓸 수 있으며, R 이 C 보다 크다면 에러 확룰이 무조건 0보다 크게 됨을 알 수 있다.
Differential Entropy
가우시안 채널의 커패시티를 구할 때 사용된다 contious random variable로 정의되는 엔트로피가 필요하다 \[h(X) = - \int{f(x)logf(x)dx}\]
음수값을 가질 수도 있으며, 무한대 값을 가질 수 있다.
uniform distribution
\[h(X) = - \int_0^a{\frac{1}{a}log\frac{1}{a}dx} = log a\]a 가 1보다 작으면 entropy가 음수로 나온다
normal distribution
외워주면 좋다 \(N(\sigma^2, \mu) = \frac{1}{\sqrt{2\pi\sigma^2 }}e^{-(\frac{x-\mu}{\sqrt{2\sigma^2}})^2}\)
확률 및 불규칙 신호론
다중 랜덤변수 기대값
다중 랜덤변수들의 함수에 대한 기대값 \[\tilde{g} = E(g(X_1,...,X_N)) = \int...\int g(x_1,...,x_N)f_{X_1,...,X_N}(x_1,...,x_N) dx_1...dx_N\]
단일 랜덤변수 함수에 대한 기대값 \[\tilde{g_1} = E(g_1(X_1)) = \int...\int g_1(x_1)f_{X_1,...,X_N}(x_1,...,x_N) dx_1...dx_N\] \[= \int g_1(x_1) \{ \int... \int f_{X_1,...,X_N}(x_1,...,x_N) dx_2...dx_N \} dx_1 = \int g_1(x_1)f_{X_1}(x_1)dx_1\]
2차 모멘트 $m_{11}=E[XY]$ 를 X와 Y의 상관(Correlation) 이라 부르고 $R_{XY}$ 로 표시한다. \[R_{XY} = m_{11} = E[XY] = \int\int xyf_{X,Y} (x,y) dx dy\]
uncorrelated 일 경우 \[R_{XY} = E[X]E[Y]\]
상관관계가 없다고 해서 독립이라고는 할 수 없다.
ex> \(P((X,Y)=(-1,1)) = 1/4 \\ P((X,Y)=(0,0)) = 1/2 \\ P((X,Y)=(1,1)) = 1/4\)
인 경우 상관관계가 없지만 독립은 아니다.
$ P((X,Y)=(0,0)) \neq P(X=-1)P(Y=1) = 1/8 $
correlation 이 0 이라면 직교라고 할 수 있다.
다중 랜덤 확률 변수의 기대값을 사용해 단일 랜덤함수에 대한 기대값으로 바꿀 수 있다.
원점에 관한 결합 모멘트
두개의 랜덤 변수에 대한 결합 모멛트 \(m_{nk} = E[X^nY^k] = \int\int x^ny^k f_{X,Y}(x,y) dx dy\)
Covariance 란?
공분산이라고 할수 있고 보통 Cov라고 한다. 공분산은 두 개 또는 그 이상의 랜덤 변수에 대한 의존성을 의미한다.
어떤 특정 샘플의 X라는 특징이 X의 평균보다 크고, 그 샘플의 Y라는 특징이 y의 평균보다 크다면, 둘다 양수가 될 것이다.
그 말은 X가 큰값을 가질 때도 Y도 큰 값을 가진다는 의존성을 보여준다
이러한 경향이 크게 나타난다면 자연스럽게 반대 방향도 함께 일어난다.
X가 증가할 때 Y도 증가하려고 하고, X가 감소할때 Y도 감소하려고 하는 것이다.
의존성이 낮은 상황 : 서로 독립인 상황
그저 공분한은 X와 Y의 곱의 평균이 될 수 있고, 이렇게 되었을 때 위에서 말한 직관이 그대로 적용되며, 선형 관계가 된다.
따라서 독립이라는 조건은 보다 강력한 조건이 된다.
https://blog.naver.com/sw4r/221025662499
모멘트란?
확률에서 모멘트는 확률분포에 있어서 매우 많은 것을 나타낸다.
n 차 모멘트는, 확률 변수 X에 대한 대표값(평균,분산,왜도,첨도 등)을 보다 일반화 시킨 것이다
확률분포 상의 여러 통계랭을 일원적으로 살펴볼 수 있다.
0차 모멘트 : PDF 면적 1차 모멘트 : 평균 2차 모멘트 : 분산 3차 모멘트 : 비틀림 4차 모멘트 : 첨도 5차 모멘트, 6차 모멘트가 존재한다.
다음은 n 차 원점 모멘트를 계산하는 식이다. 원점 모멘트는 원점을 중심으로 하는 n차 모멘트이다. \[m_n = E[X^n] = \int x^n f_x(x) dx\]
f(x)의 면적 \(m_0 = E[X^0] = \int x^0 f_x(x) dx = \int f_x(x) dx = 1\)
평균에 대한 기대값 \(m_1 = E[X^1] = \int x^1 f_x(x) dx\)
분산에 대한 기대값 \(m_2 = E[X^n] = \int x^2 f_x(x) dx\)
4차 모멘트: 왜도에 대한 기대값 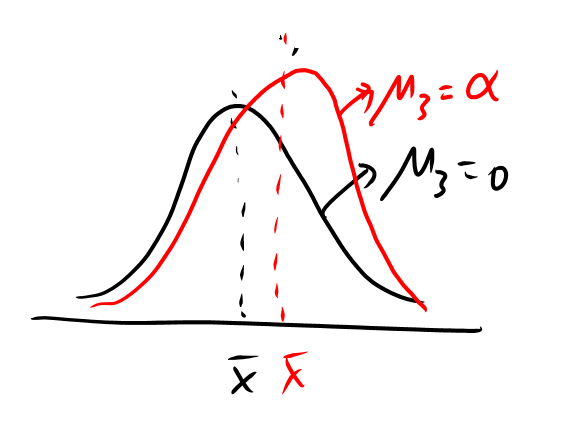
분포의 비대칭 정도의 측도
5차 모멘트: 첨도에 대한 기대값
분포의 뾰족한 정도의 측도
중심 모멘트는 평균값을 중심으로 하는 n차 모멘트이다. \[\mu_n = E[(X-\tilde{X})^n] = \int (x-\tilde{x})^n f_x(x) dx\]
0차 중심 모멘트는 “1”,1 차 중심 모멘트는 “0” 이다
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=pro_000&logNo=220981470419
http://www.ktword.co.kr/test/view/view.php?m_temp1=5121
결합 중심 모멘트(joint central moments)
결합 중심 모멘트 식: \[\mu_{nk} = E[(X-\tilde{X})^n(Y-\tilde{Y}^k)]= \int \int (x - \tilde{X})^n(y - \tilde{Y})^k dx dy\]
n과 k의 값을 합한 값이 차수가 된다.
2차 중심 모멘트 : $ \mu_{02} , \mu_{11} , \mu_{20} $
$\mu_{02}, \mu_{20}$ : 각각 X와 Y의 분산 값이다
$\mu_{11}$ : Covariance 공분산 을 뜻한다.
공분산은 두 개 또는 그 이상의 랜덤 변수에 대한 의존성을 의미한다. 증가할 때 똑같이 증가하고 감소할 때 똑같이 감소하는 정도. \[C_XY = \mu_{11} = E[(X-\tilde{X})(Y-\tilde{Y})] = E[XY] - E[X]E[Y] = R_{XY} - E[X][Y]\]
X와 Y가 독립이거나, 상관관계가 없을 경우 covariance가 0을 가는다.
X와 Y가 직교하면 covariance는 -E[X]E[Y] 값을 갖는다
- 직교하면선 E[X] 또는 E[Y]가 0 이면 uncorrelated
https://www.youtube.com/watch?v=152tSYtiQbw
The Convariance Matrix: Data Science Basics
degree to where two go together (다른 정도)
covariance & correlation
covariance : -1~1 에 한정되지 X correlation : -1~1에 한정됨
Covariance shows you how the two variables differ, whereas correlation shows you how the two variables are related
https://www.simplilearn.com/covariance-vs-correlation-article
####Comparison
Definition Covariance: 두 확률 분포가 서로에게 얼마나 dependent 한지 수치적으로 측정한다 correlation: 두 변수가 얼마나 관련되어 있는지를 수치적으로 측정한다
- values covariance : -inf ~ inf Correlation -1 ~ 1
Change in scale scale을 변화 시키는 것은 covariance에는 영향을 주지만 correlation에는 영향을 주지 않는다
- unit free meature Covariance: No Correlation: yes
However, when it comes to making a choice between covariance vs correlation to measure relationship between variables, correlation is preferred over covariance because it does not get affected by the change in scale.
상관계수 (Correlation coefficient)
그냥 correlation 이다 \[\rho = \frac{C_{X,Y}}{\sigma_X \sigma_Y} = \frac{\mu_{11}}{\mu_{02}\mu_{20}}, -1 \leq \rho \leq 1\]
Correlation coefficient
X가 증가할 때 똑같이 Y도 증가하는 경우 $\rho = 1$ X가 증가할 때 똑같이 Y도 감소하는 경우 $\rho = 1$
Strength of linear relation between two variables strong relationship -> close to 1/-1 weak relationship -> close to 0
https://www.youtube.com/watch?v=11c9cs6WpJU
