Machine Learning
시험 전 정리
- problem define
- data collection
- Analysis & Cleaning & Transform
- Train (Machine Learning)
- Test (performance evaluation)
- Deploy
K-fold Cross Validation
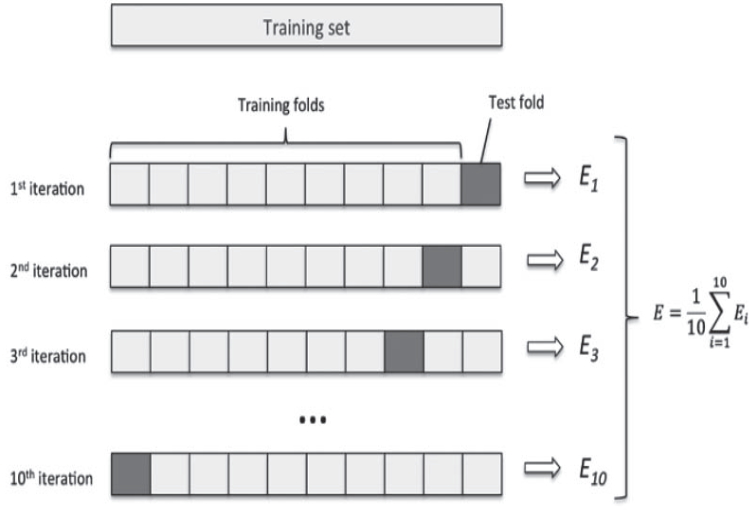 데이터가 충분하지 않은 경우 validation dataset을 별도로 만들어줄 수 없다 이 경우
데이터가 충분하지 않은 경우 validation dataset을 별도로 만들어줄 수 없다 이 경우 cross-validation을 사용한다
- 데이터를 k개 그룹으로 분할
- k-1 그룹의 데이터를 훈련 데이터로 사용
- 데이터의 나머지 부분에 대해 검증
- 검증 데이터 그룹을 달리하여 2,3 과정을 반복
- k번 검증된 결과의 평균을 측정
Cross-Entropy
Inforation theory에서 사용하는 entropy의 정의와 비슷하다 \(I(x) = log\frac{1}{p(x)}\) 확률이 낮을 수록 더 높은 정보를 가지고 있을 것이라는 식이다
Cross-Entropy Loss
\(CE = -\sum t_i log(s_i)\) $t_i$ 는 ground truth, $s_i$는 각 클래스에 대한 점수이다 크로스 엔트로피는 예측과 달라서 생기는 loss이다
Binary Cross-Entropy
\(loss = - ylog(\hat{y}) - (1-y)log(1-\hat{y})\)
Categorical Cross Entropy
 Softmax activation 뒤에 Cross-Entropy Loss를 붙인 형태이다. Softmax loss 이라고도 불린다 \[CE = \sum -P(x) log(Q(x))\]
Softmax activation 뒤에 Cross-Entropy Loss를 붙인 형태이다. Softmax loss 이라고도 불린다 \[CE = \sum -P(x) log(Q(x))\]
원래 분포 P(x)에 예측된 Q(x)가 얼마나 떨어져 있는지 수치화한 값이다.
[출처]
- https://angeloyeo.github.io/2020/10/27/KL_divergence.html
- https://wordbe.tistory.com/entry/ML-Cross-entropyCategorical-Binary%EC%9D%98-%EC%9D%B4%ED%95%B4
One Versus Rest
하나와 나머지, 하나와 나머지를 class의 종류만큼 비교한다 그 모든 classification 결과들을 이용해 결과를 출력한다
각각에 대한 score을 따로 구하고 따로 train을 따로따로 해준다고 볼 수 있다.
Softmax Calssification

Stocastic Gradient Descend
Batch 내에 모든 데이터들을 이용해 Loss를 구하지 않고 mini-batch를 이용해서 Loss를 구하는 방법이다 Batch의 모든 데이터들을 이용하는 것은 비용이 크게 발생한다
Performance
Regression
R2 Score \(1 - \frac{\sum(y-\hat{y})^2}{\sum(y-\bar{y})^2}\)
- $\hat{y}$ : 예측 값
- $\bar{y}$ : 평균 값
평균에서 멀리 떨어져있는 값일 수록 performance의 비중을 낮춘다 평균에 가까울수록 정확도가 높아야 한다
classification
static performance
- Confusion Matrix
Recall : 원래의 것을 얼마나 잘 예측했는지 나타낸다 Precision : 예측된 것들이 얼마나 잘 예측된지 나타낸다
dynamic performance TPR true positive rate와 FPR false positive rate를 사용해 ROC Curve(Reciever Operating Characteristic)를 그린다
ROC Curve의 AUC(Area Under Cover)를 사용해 performance를 측정한다 TPR와 FPR가 완전히 나누어져 있는 것이 좋으므로 AUC 값이 클 수록 좋다
[참고] https://angeloyeo.github.io/2020/08/05/ROC.html
Regularization
Ridge Regularization (L2 Regularization) \(loss = MSE(W) + \alpha \frac{1}{2} ||W||_2^2\)
weight가 큰 feature들을 줄이면서 정규화를 한다
Lasso Regularization (L1 Regularization) \(loss = MSE(W) + \alpha |W|\) weight가 작은 feature들을 없애면서
중요한 feature을 찾는데 사용한다Elastic Net L1과 L2를 모두 사용한다
Imbalance problem
over-sample과 under-sample을 사용한다. SMOTE와 BoarderlineSMOTE를 이용해 over-sample을 한다
SVM
SVM은 linear 데이터 뿐만 아니라 non-linear 데이터에도 사용할 수 있다 Gaussian RBF kernel을 사용한다. sample들에 landmark를 만들어 차원을 높여준다. feature을 늘려 linearly seperable 하도록 만든다
원래 필요했던 일
- 모든 점들을 차원변환한다
- 모든 점들 간의 inner product를 구한다
Kernel function을 이용하면 차원변환 없이 classifier 학습이 가능하다 Complexity가 샘플의 수에 따라 달라진다
SVR
epsilon-insensitive loss를 사용한다
Search
grid search GridSearchCV(model(), params, cv=3, n_jobs)
random search RandomizedSearchCV(model, random_grid, cv=3, n_job=-1)
default로 niter = 10을 가지고 있다 즉, 10개를 랜덤하게 갖는다
Ensemble Method
여러개의 모델들로 학습된 결과를 이용한다
hard voting 모델들의 predict를 사용하여 결과로 적절한 값을 추출한다
soft voting 모델들의
predict_proba를 사용한다- bagging
- 여러개의 decision tree들로 나누어 학습한다
- 중복을 허용해 n개의 샘플을 추출한다
- overfitting을 줄인다
- Parallel하게 진행된다
- 중복을 허용하지 않고 해줄 경우 37%의 데이터들이 한번도 사용되지 않는다. 이를 validation에 사용한다.
- Pasting
- 중복을 허용해 샘플을 추출한다
- boosting
- 틀린 부분에 weight를 더 크게 주어 decision Tree 재실행한다
- Serial하게 진행한다
처음에 한 결과가 약간은 유지된다
- adaBoost
- 처음에 sample들은 모두 같은 가중치를 나누어 갖는다 (1/N)
- 학습 후 가중치를 업데이트 한다.
- 잘못 예측된 값들의 가중치를 높게 설정한다
- Tree를 합칠 때 얼만큼 반영할지 계산한다
- Gradient Boost
- residual error 을 사용한다
- mse와의 차이들을 이용해 decision tree를 다시 한다
- Tree에 대한 가중치 또한 계산된다
