Transformer Decoder
서론
Decoder Layer는 Encoder Layer과 비슷합니다.
![]()
Output Embedding
Encoder에서와 동일하게 Standard Embedding와 Positional Embedding를 사용합니다.
Masked Multi-Head Attention
Encoder에서 사용하는 Multi-Head Attention 계층과 다른 점은 Encoder에서는 <pad> 토큰에 대한 마스킹만 하지만 Decoder에서는 target sequence에 대한 마스킹을 해줍니다. \[\begin{matrix} 1 & 0 & 0 & 0 & 0\\ 1 & 1 & 0 & 0 & 0\\ 1 & 1 & 1 & 0 & 0\\ 1 & 1 & 1 & 1 & 0\\ 1 & 1 & 1 & 1 & 1\\ \end{matrix}\]
위 mask가 target sequence에 대한 mask입니다. Train 때는 target sequence가 주어지지만 Test에는 하나 하나 학습하면서 알아가야 합니다. 학습단계에서 이러한 일종의 치팅 행위를 막기 위해서 trg_pad를 사용해줍니다.
\(\begin{matrix} 1 & 0 & 0 & 0 & 0\\ 1 & 1 & 0 & 0 & 0\\ 1 & 1 & 1 & 0 & 0\\ 1 & 1 & 1 & 0 & 0\\ 1 & 1 & 1 & 0 & 0\\ \end{matrix}\) 위 마스크는 trg_mask에 src_mask까지 적용된 mask입니다. 우리는 위 mask를 이용해 multi-head attention을 진행할 것입니다.
Multi-Head Attention
#encoder attention
_trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask)
Query로 decoder에서의 self-attention 결과를, Key로 encoder에서의 self-attention 결과를, Value로 encoder에서의 self-attention 결과를 사용해 encoder 입력과 decoder 입력 사이의 attention을 구합니다. 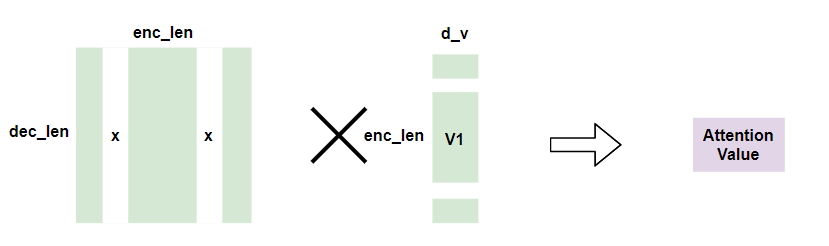 decoder의 입력이 encoder의 어느부분에 집중해야 하는지 구할 수 있습니다.
decoder의 입력이 encoder의 어느부분에 집중해야 하는지 구할 수 있습니다.
