Normalization Layer
서론
딥러닝을 공부하다보면 Normalization, DropOut, Residual Connection 등이 학습시간을 단축 시키기 위해 사용됩니다. 우리는 그 중에서 딥러닝에서 사용되는
정규화 계층에 대 정리해 볼 것입니다. 정규화 기법들로 Batch Normalization, Layer Normalization, Instance Normalization, Group Normalization이 있습니다.
- 목차
- 정규화는 왜 필요할까?
- Batch Normalization
정규화는 왜 필요할까?
딥러닝에서 발생하는 상황들 중 하나로 vanishing/exploding gradient가 있습니다. Layer 수가 적은 경우 문제가 심각하지 않지만, Layer 수가 많아질 수록 누적되어 나타나기 때문에 심각한 문제가 됩니다.
vanshing/exploding gradient 이 현상이 발생하는 이유가 무엇일까요? 활성화 함수 중 하나인 Sigmoid 함수를 갖고 왔습니다.

시그모이드 함수의 출력은 0과 1 사이로 제한되어, 입력의 절대값이 커질수록 출력은 0 또는 1로 수렴하게 됩니다.
출력값이 수렴한다 뜻은 ``미분값이 ‘0’이라는 말과 같습니다. 미분 값을 통해 학습되는 파라미터들은 학습 속도가 굉장히 느려지겠지요. 이 현상을vanishing gradient`이라고 합니다.
네트워크 각 계층의 입력값들을 정규화 시켜 saturation regeme에 갇히지 않도록 하는 방법이 발표됩니다. 이 벙법이 정규화 기법으로 최근 거의 모든 딥러닝 모델에 사용되고 있습니다.
Covariate Shift
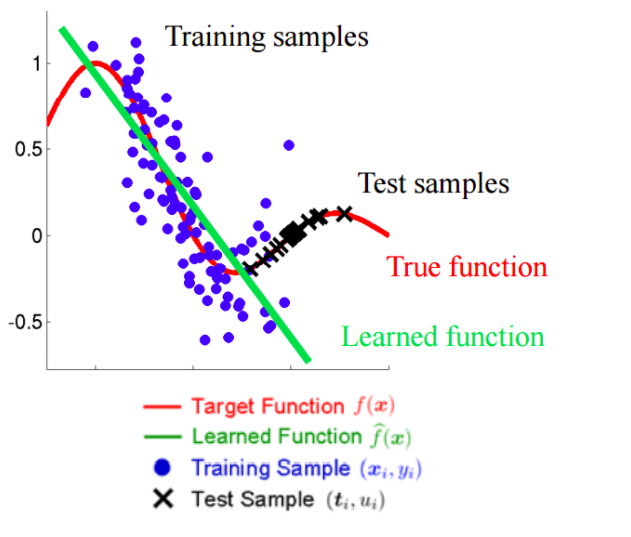 입력의 분포에 따라 학습되는 결과가 다른데 이를 Covariate Shift라고 합니다. 딥러닝에서는 하나의 계층의 출력이 다음 계층의 입력이 됩니다. 이 값에 적용되는 Covatiate Shift를
입력의 분포에 따라 학습되는 결과가 다른데 이를 Covariate Shift라고 합니다. 딥러닝에서는 하나의 계층의 출력이 다음 계층의 입력이 됩니다. 이 값에 적용되는 Covatiate Shift를 Internal Covariate Shift라고 합니다. 우리는 이 현상을 줄이기 위해 Batch Normalization을 이용합니다.
Batch Normalization
2015년에 vanishing gradient를 줄이기 위해 획기적인 방법 두개가 발표되는데 BN(Batch Normalization)과 Residual Network입니다. 우리는 이 중 BN에 대해 알이볼 것 입니다.
전체 traing set을 분석할 수 없으며 미분 가능한 방법으로 normailzation을 선택했습니다. 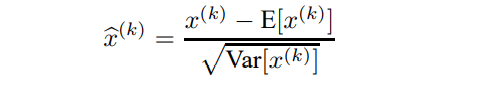 각각의 feature 마다 따로 정규화 해주는 함수입니다.
각각의 feature 마다 따로 정규화 해주는 함수입니다.
feature 마다 decorrelate 시켜줄 수는 없지만` 충분히 학습 속도를 향상 시킬 수 있습니다.
 위 이미지에서 볼 수 있듯이 feature 마다 같은 평균 값을 이용해 정규화를 해줍니다.
위 이미지에서 볼 수 있듯이 feature 마다 같은 평균 값을 이용해 정규화를 해줍니다.
정규화를 해주므로써 saturation regime에 갇히지 않도록 해주었습니다. 그러나 이 것만을 해주면 시그모이드 함수를 사용하는 의미가 없어집니다. 평균값을 0, 분산을 1로 정규화된 데이터는 -1~1(66%), -2~2(99%)사이에 데이터가 분포합니다.
비선형의 특성을 위해 활성화 함수를 사용하는데 -1과 1 사이에 선형적인 특성을 갖기 때문에 활성화 함수를 사용하는 의미가 없어집니다.
.PNG) 이를 해결해주기 위해 BN에는
이를 해결해주기 위해 BN에는 scaling parameter Γ, shift parameter Β를 사용해줍니다.
Layer Normalization
Batch Norm은 mini-batch의 모든 입력을 평균시켜 정규화를 진행합니다. 즉, Batch의 모든 입력 값이 동일한 평균값을 공유한다는 것입니다.
예를 들어, 딥러닝을 통해 이미지를 처리하는 상황이라고 하겠습니다. 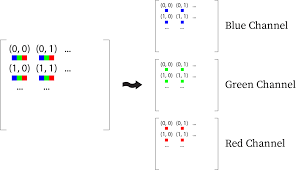
mini-batch의 사이즈는 100, 이미지 크기는 10x10이라고 가정하겠습니다. feature의 크기는 RGB 3의 값을 갖겠지요.
RGB 각각의 feature마다 정규화가 진행되며, 정규화 시 이용되는 평균값은 100x10x10 입력을 평균해서 구해지게 됩니다. (mini-batch:100, image-size:10x10)
이러한 방법은 순환구조가 있는 RNN에는 사용될 수 없습니다. RNN의 mini-batch를 생각해보겠습니다. vector_size:8 , mini-batch:100, step-size: 10 의 RNN 구조가 있습니다. 이 RNN에 batch norm을 적용하기 위해서는 batch의 입력들을 이용해서 평균값을 구해주어야 합니다. 그러나 생각해보면 RNN의 각각의 입력 값들은 모두 시간에 따라 달라지는 값을 갖고 있습니다. 즉, 시간적인 특성인 포함된 값들입니다. 모두 동일하게 평균화를 시켜버리면 이러한 특성을 모두 잃어버리게 됩겠지요.
[참고] [https://stackoverflow.com/questions/45493384/is-it-normal-to-use-batch-ormalization-in-rnn-lstm]
For RNNs, this means computing the relevant statistics over the mini-batch and the time/step dimension, so the normalization is applied only over the vector depths. This also means that you only batch normalize the transformed input (so in the vertical directions, e.g. BN(W_x * x)) since the horizontal (across time) connections are time-dependent and shouldn't just be plainly averaged.
```
이 예에서 feature은 vector_size이다? 각각의 토큰은 vector_size의 길이로 변환된다, 이 토큰의 vector_size별로 normalize 시킨다는 개념이 RNN에서의 Batch Norm이다. ```
그래서 RNN은 Layer normalization이라는 BN과는 조금 다른 방법으로 정규화를 시킵니다.
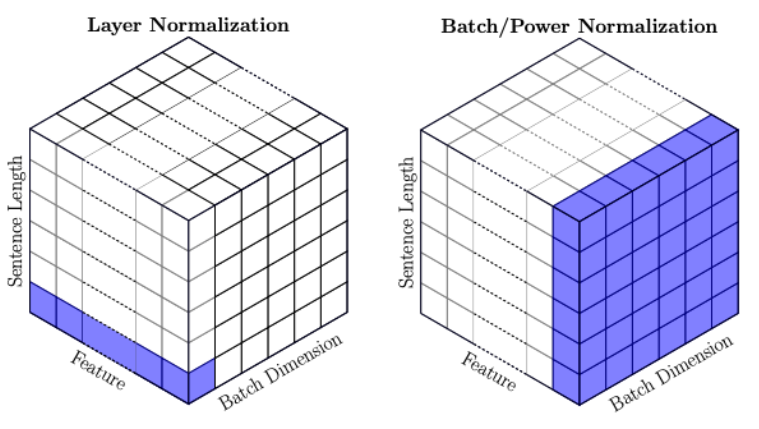
바로 모든 각각의 입력 값 마다 정규화 시켜주는 것입니다.
각각의 입력값들을 vector_size 마다 정규화를 시켜주는 정규화를 Layer Normalization이라고 합니다.
[참고]
[논문] Batch Normalization: Accelerating Deep Network Training b y, Reducing Internal Covariate Shift
