Covariate Shift
서론
Internal Coviative Shift
Normalization 기법이 사용되는 가장 큰 이유는
Covatiate Shift를 없애주기 위해서 입니다. 그래서 Covatiate Shift란 무엇일까요? 다음 블로그 내용을 참고했습니다.
데이터 사이언스를 공부하다 보면 그에 관련된 대회들도 많은 것을 볼 수 있습니다. 이런 대회들에서 데이터를 다루는 것과 실제 현실에서 데이터를 다루는 것에는 어떤 차이가 있을 까요?
대회에서 사용되는 데이터셋들 같은 경우, 대부분 하나의 데이터 셋에서 나옵니다. 하나의 deviation을 가진 데이터들을 Test, Train용 데이터로 나누는 것이지요.
그러나 현실에서는 오랜 시간동안 데이터가 수집되면서 환경에 따른 변화가 생길 수 있고 변수들에 많은 변화가 생길 수 있습니다. 오직 하나의 deviation을 가진 데이터셋으로 학습된 모델로는 해결할 수 없는 문제들이 발생할 것 입니다. 한마디로 오버피팅이 문제가 됩니다.
이 글에서 우리는 현실에서 마주할 수 있는 문제들 혹은 Dataset Shift에 대해 다룰 것입니다.
- 목차
- What is Dataset Shift?
- What causes Dataset Shift?
- Types of Dataset Shift
- Covariate Shift
- Identification
- Treatment
- Dropping of drifting features
- Importance Weight using Density Ratio Estimation
what is data shift?
데이터 사이언스 대회는 이런 식으로 진행됩니다.  Train와 Test 파일이 대회에서 제공이 되면
Train와 Test 파일이 대회에서 제공이 되면 preprocess, feature engineering, cross-validation과정을 진행합니다.
- preprocess : 데이터 전처리
토큰화 등을 진행하는 단계입니다.
- feature engineering : 특징 추출
데이터에 대한 도메인 지식을 활용해 특징을 만들어내는 과정입니다.
훈련 데이터를 사용해 학습을 할 때 매번 학습이 잘되어 결과가 나타나지는 않습니다.
내가 가지고 있는 데이터가 방대하다고 해도 그 데이터를 모두 데이터를 도출하는데 쓰면 정확히
나타낼 듯하지만 오히려 결과가 잘못되게 도출하는 경우가 많습니다.
feature가 유용한지 확인하는 과정을 `feature selection` 이라고 합니다.
- Cross-Validation : 교차 검증

처음 보는 데이터에서 모델이 어떻게 작동하는지 알기 위해 만든 데이터가 `Valid Data`입니다.

그림과 같이 학습 데이터에 대한 ``오버피팅``이 일어 났을 가능성을 말해주며
테스트 데이터로 가기전에 모델을 검증하고 잘못된 부분을 고칠 수 있습니다.
하지만 Train Data와 Vailid 데이터로 나누는 것은 Train Data가 많은 경우 입니다.
`데이터가 적은 경우에 사용할 수 있는 방법이 Cross Validation`입니다.
test data를 valid data로 사용할 수 있도록 재탕해주는 것이지요.
그런 후 Test-Prediction 단계에 들어서는데 결과가 cross-vaildation 결과와 다르게 나오는 일은 빈번히 발생합니다. 이러한 현상의 이유는 train data와 test data에서의 data distribution의 차이 때문이고 이를 Dataset Shift라고 합니다.
Types of Dataset Shift
- Shift in the
independent variables(Covariate Shift) - Shift in the
target variable(Prior probability shift) - Shift in the relationship between the independent and the target variable (Concept Shift)
즉, 우리가 주는 입력에서 발생하는 shift가 Covatiate Shift이고 출력에서 발생하는 shift가 Prior probability shift인 것 입니다. 입력이 예상하지 못한 값에서 오는 경우 : Covatiate Shift 결과가 예상하지 못한 값에서 오는 경우 : Prior Probability Shift
Covariate Shift
Covariate Shift가 발생하는 이유는 Train과 Test에서 입력변수의 분포의 차이 때문입니다. 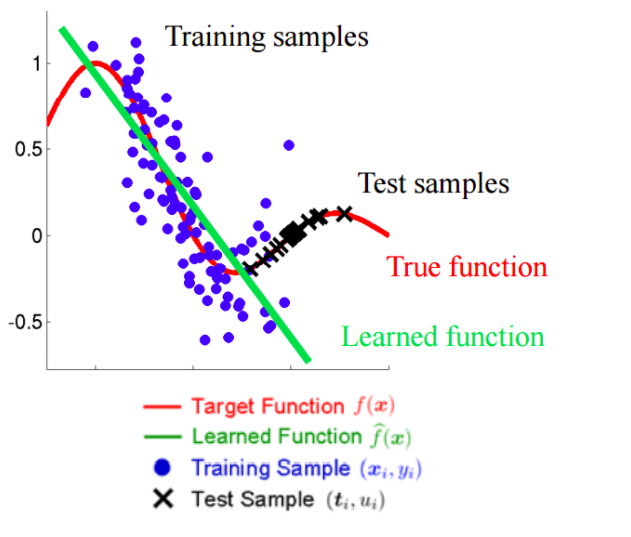
[이 다음부터는 머신러닝 내용이여서 SKIP..]
